


Featured AI
-
NormalCrafter – Learning Temporally Consistent Normals from Video Diffusion Priors
Read more: NormalCrafter – Learning Temporally Consistent Normals from Video Diffusion Priorshttps://normalcrafter.github.io
https://github.com/Binyr/NormalCrafter
https://huggingface.co/spaces/Yanrui95/NormalCrafter
https://huggingface.co/Yanrui95/NormalCrafter

-
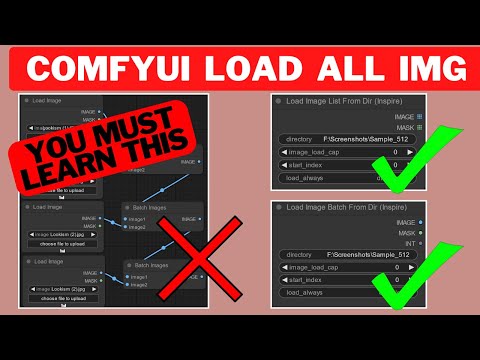
Comfy-Org comfy-cli – A Command Line Tool for ComfyUI
Read more: Comfy-Org comfy-cli – A Command Line Tool for ComfyUIhttps://github.com/Comfy-Org/comfy-cli
comfy-cli is a command line tool that helps users easily install and manage ComfyUI, a powerful open-source machine learning framework. With comfy-cli, you can quickly set up ComfyUI, install packages, and manage custom nodes, all from the convenience of your terminal.
C:\<PATH_TO>\python.exe -m venv C:\comfyUI_cli_install cd C:\comfyUI_env C:\comfyUI_env\Scripts\activate.bat C:\<PATH_TO>\python.exe -m pip install comfy-cli comfy --workspace=C:\comfyUI_env\ComfyUI install # then comfy launch # or comfy launch -- --cpu --listen 0.0.0.0If you are trying to clone a different install, pip freeze it first. Then run those requirements.
# from the original env python.exe -m pip freeze > M:\requirements.txt # under the new venv env pip install -r M:\requirements.txt
-
HoloPart -Generative 3D Models Part Amodal Segmentation
Read more: HoloPart -Generative 3D Models Part Amodal Segmentationhttps://vast-ai-research.github.io/HoloPart
https://huggingface.co/VAST-AI/HoloPart
https://github.com/VAST-AI-Research/HoloPart
Applications:
– 3d printing segmentation
– texturing segmentation
– animation segmentation
– modeling segmentation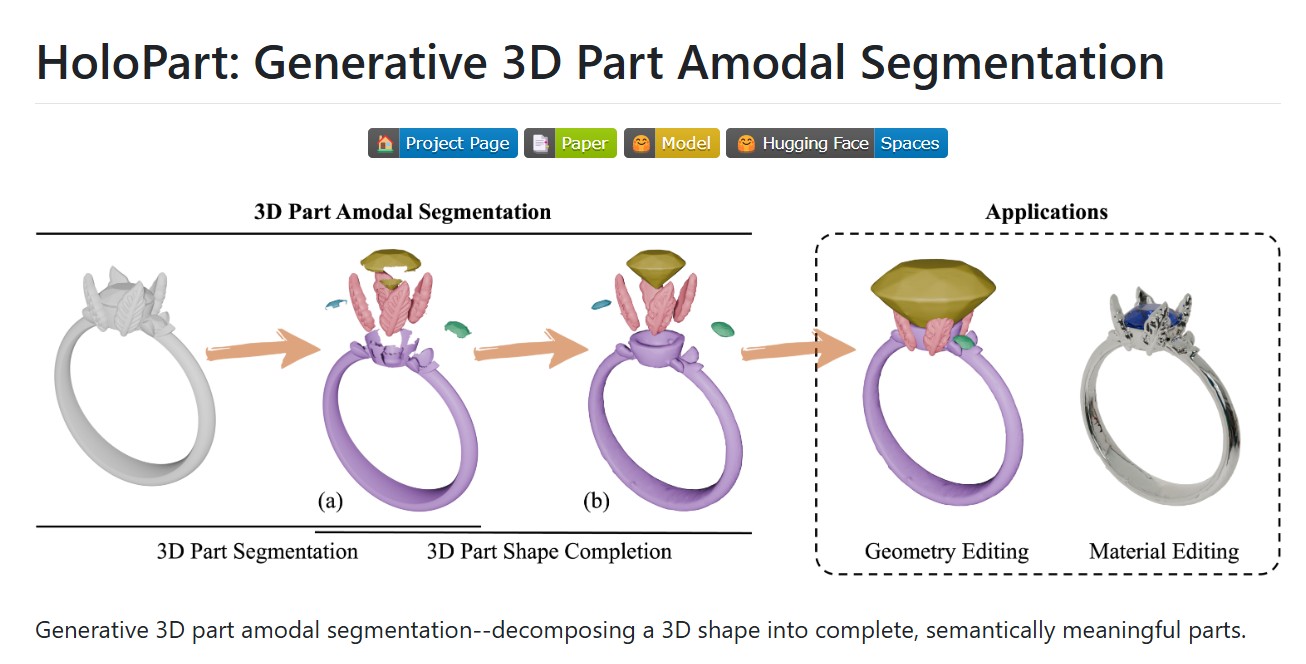
-
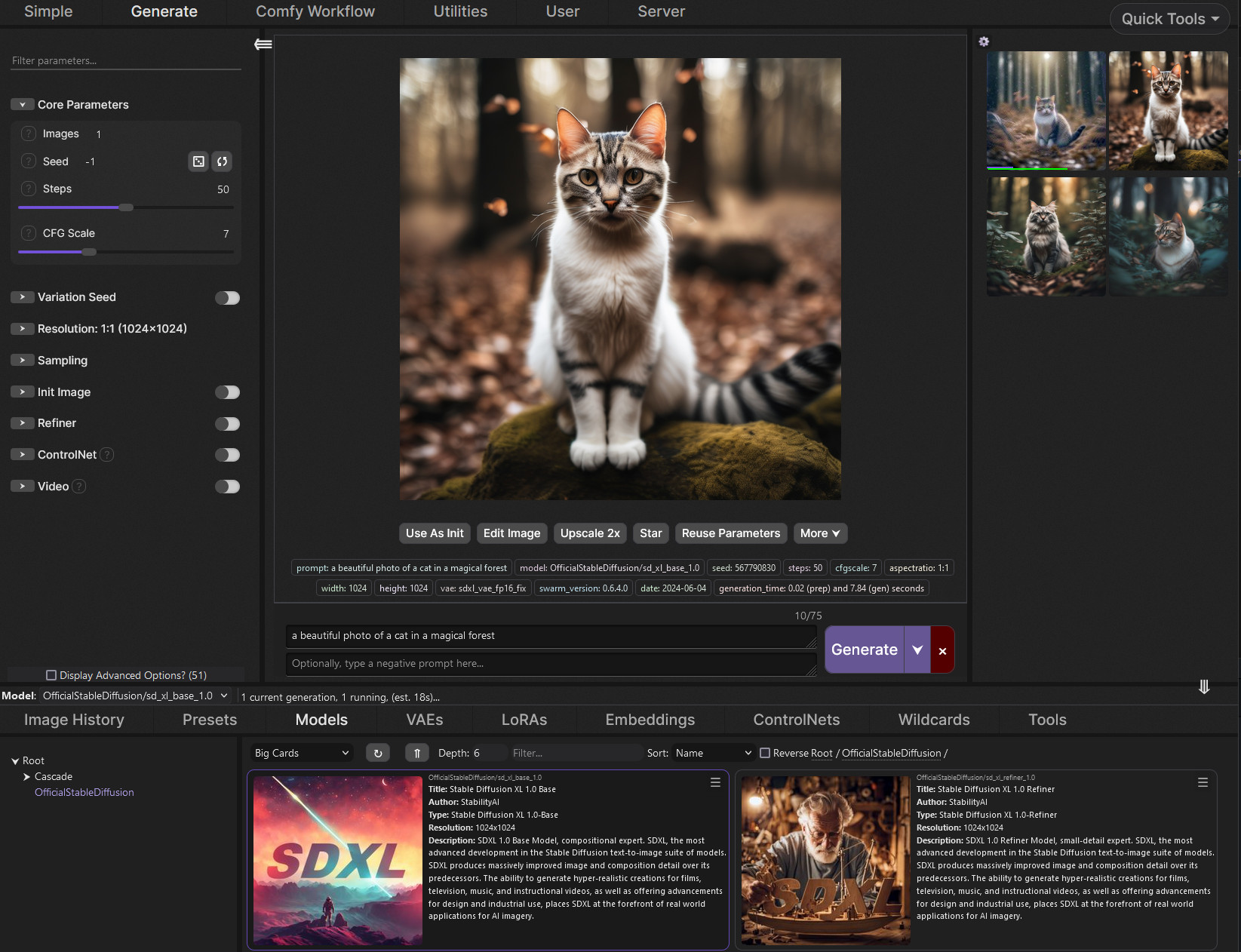
SwarmUI.net – A free, open source, modular AI image generation Web-User-Interface
Read more: SwarmUI.net – A free, open source, modular AI image generation Web-User-Interfacehttps://github.com/mcmonkeyprojects/SwarmUI
A Modular AI Image Generation Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. Supports AI image models (Stable Diffusion, Flux, etc.), and AI video models (LTX-V, Hunyuan Video, Cosmos, Wan, etc.), with plans to support eg audio and more in the future.
SwarmUI by default runs entirely locally on your own computer. It does not collect any data from you.
SwarmUI is 100% Free-and-Open-Source software, under the MIT License. You can do whatever you want with it.
-
VACE – All-in-One Video Creation and Editing
Read more: VACE – All-in-One Video Creation and Editinghttps://ali-vilab.github.io/VACE-Page
https://github.com/ali-vilab/VACE
https://huggingface.co/collections/ali-vilab/vace-67eca186ff3e3564726aff38
https://github.com/kijai/ComfyUI-WanVideoWrapper/tree/main/example_workflows

-
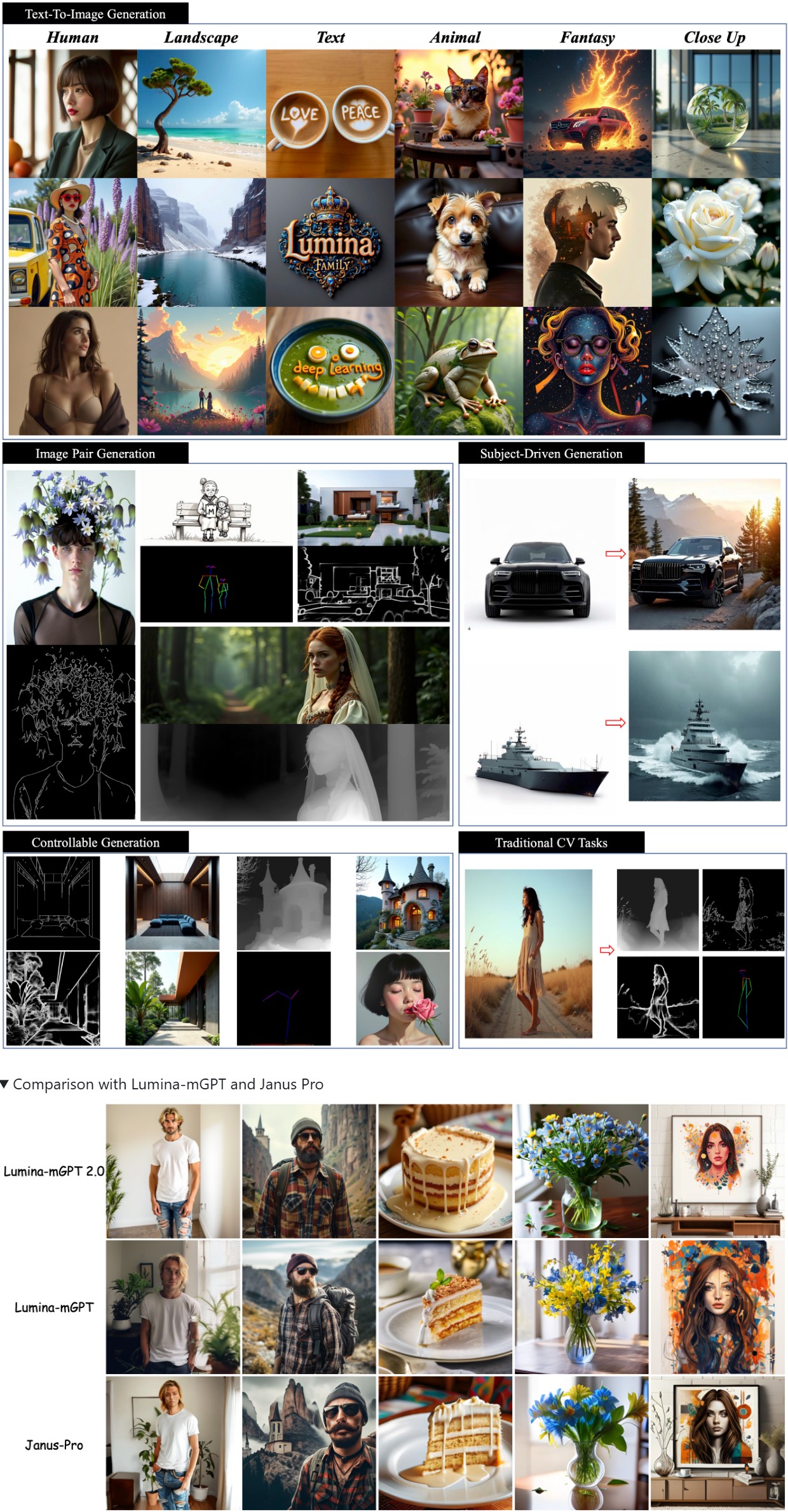
Lumina-mGPT 2.0 – Stand-alone Autoregressive Image Modeling
Read more: Lumina-mGPT 2.0 – Stand-alone Autoregressive Image ModelingA stand-alone, decoder-only autoregressive model, trained from scratch, that unifies a broad spectrum of image generation tasks, including text-to-image generation, image pair generation, subject-driven generation, multi-turn image editing, controllable generation, and dense prediction.
https://github.com/Alpha-VLLM/Lumina-mGPT-2.0
-
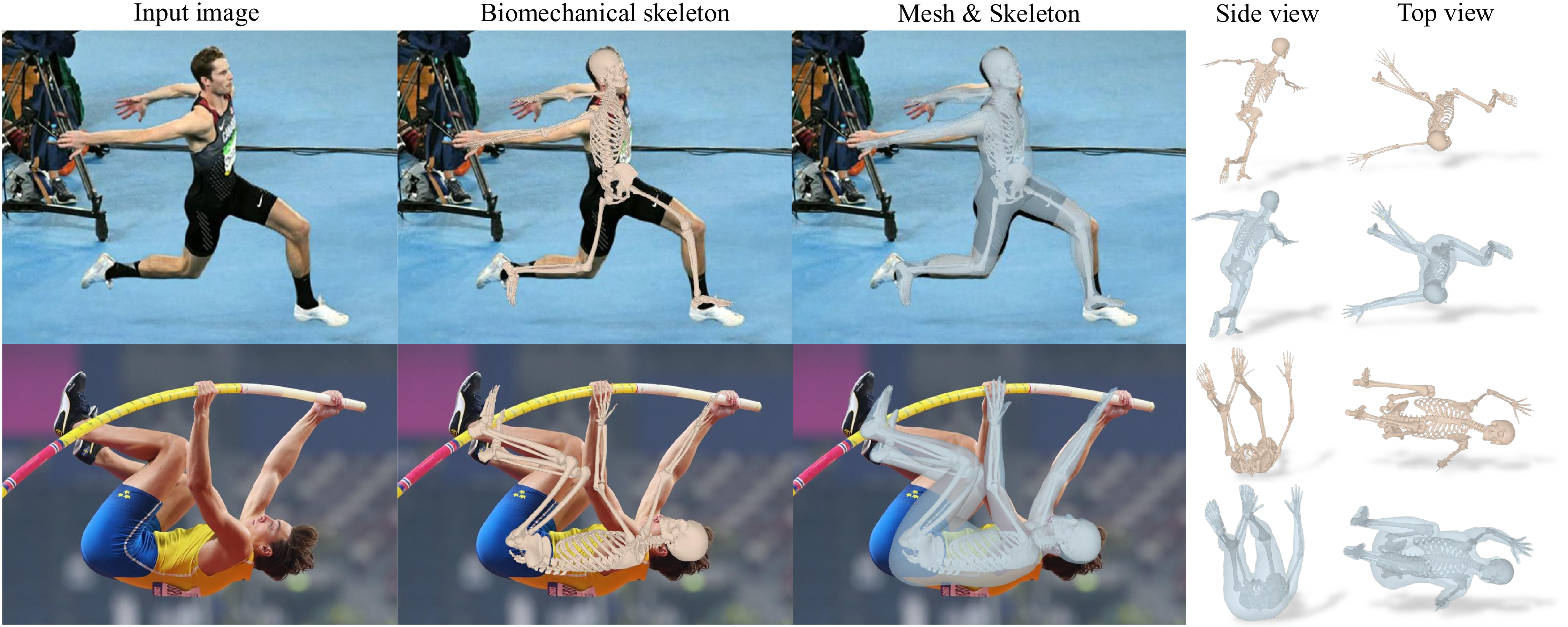
HSMR – Reconstructing Humans with a Biomechanically Accurate Skeleton
Read more: HSMR – Reconstructing Humans with a Biomechanically Accurate Skeletonhttps://isshikihugh.github.io/HSMR
https://github.com/IsshikiHugh/HSMR
https://huggingface.co/spaces/IsshikiHugh/HSMR
https://colab.research.google.com/drive/1RDA9iKckCDKh_bbaKjO8bQ0-Lv5fw1CB?usp=sharing
-
AccVideo – Accelerating Video Diffusion Model with Synthetic Dataset
Read more: AccVideo – Accelerating Video Diffusion Model with Synthetic Datasethttps://aejion.github.io/accvideo
https://github.com/aejion/AccVideo
https://huggingface.co/aejion/AccVideo
AccVideo is a novel efficient distillation method to accelerate video diffusion models with synthetic datset. This method is 8.5x faster than HunyuanVideo.

-
Runway introduces Gen-4
Read more: Runway introduces Gen-4https://runwayml.com/research/introducing-runway-gen-4
With Gen-4, you are now able to precisely generate consistent characters, locations and objects across scenes. Simply set your look and feel and the model will maintain coherent world environments while preserving the distinctive style, mood and cinematographic elements of each frame. Then, regenerate those elements from multiple perspectives and positions within your scenes.


-
StarVector – A multimodal LLM for Scalable Vector Graphics (SVG) generation from images and text
Read more: StarVector – A multimodal LLM for Scalable Vector Graphics (SVG) generation from images and texthttps://huggingface.co/collections/starvector/starvector-models-6783b22c7bd4b43d13cb5289
https://github.com/joanrod/star-vector

-
Reve Image 1.0 Halfmoon – A new model trained from the ground up to excel at prompt adherence, aesthetics, and typography
Read more: Reve Image 1.0 Halfmoon – A new model trained from the ground up to excel at prompt adherence, aesthetics, and typographyA little-known AI image generator called Reve Image 1.0 is trying to make a name in the text-to-image space, potentially outperforming established tools like Midjourney, Flux, and Ideogram. Users receive 100 free credits to test the service after signing up, with additional credits available at $5 for 500 generations—pretty cheap when compared to options like MidJourney or Ideogram, which start at $8 per month and can reach $120 per month, depending on the usage. It also offers 20 free generations per day.

-
De-reflection – Remove Reflections From Any Image with Diffusion Priors and Diversified Data
Read more: De-reflection – Remove Reflections From Any Image with Diffusion Priors and Diversified Datahttps://arxiv.org/pdf/2503.17347
https://abuuu122.github.io/DAI.github.io
https://github.com/Abuuu122/Dereflection-Any-Image
https://huggingface.co/spaces/sjtu-deepvision/Dereflection-Any-Image

-
Robert Legato joins Stability AI as Chief Pipeline Architect
Read more: Robert Legato joins Stability AI as Chief Pipeline Architecthttps://stability.ai/news/introducing-our-new-chief-pipeline-architect-rob-legato
“Joining Stability AI is an incredible opportunity, and I couldn’t be more excited to help shape the next era of filmmaking,” said Legato. “With dynamic leaders like Prem Akkaraju and James Cameron driving the vision, the potential here is limitless. What excites me most is Stability AI’s commitment to filmmakers—building a tool that is as intuitive as it is powerful, designed to elevate creativity rather than replace it. It’s an artist-first approach to AI, and I’m thrilled to be part of it.”


-
Personalize Anything – For Free with Diffusion Transformer
Read more: Personalize Anything – For Free with Diffusion Transformerhttps://fenghora.github.io/Personalize-Anything-Page
Customize any subject with advanced DiT without additional fine-tuning.

-
Google Gemini 2.0 Flash new AI model extremely proficient at removing watermarks from images
Read more: Google Gemini 2.0 Flash new AI model extremely proficient at removing watermarks from imagesGemini 2.0 Flash won’t just remove watermarks, but will also attempt to fill in any gaps created by a watermark’s deletion. Other AI-powered tools do this, too, but Gemini 2.0 Flash seems to be exceptionally skilled at it — and free to use.

-
Stability.ai – Introducing Stable Virtual Camera: Multi-View Video Generation with 3D Camera Control
Read more: Stability.ai – Introducing Stable Virtual Camera: Multi-View Video Generation with 3D Camera ControlCapabilities
Stable Virtual Camera offers advanced capabilities for generating 3D videos, including:
- Dynamic Camera Control: Supports user-defined camera trajectories as well as multiple dynamic camera paths, including: 360°, Lemniscate (∞ shaped path), Spiral, Dolly Zoom In, Dolly Zoom Out, Zoom In, Zoom Out, Move Forward, Move Backward, Pan Up, Pan Down, Pan Left, Pan Right, and Roll.
- Flexible Inputs: Generates 3D videos from just one input image or up to 32.
- Multiple Aspect Ratios: Capable of producing videos in square (1:1), portrait (9:16), landscape (16:9), and other custom aspect ratios without additional training.
- Long Video Generation: Ensures 3D consistency in videos up to 1,000 frames, enabling seamless
Model limitations
In its initial version, Stable Virtual Camera may produce lower-quality results in certain scenarios. Input images featuring humans, animals, or dynamic textures like water often lead to degraded outputs. Additionally, highly ambiguous scenes, complex camera paths that intersect objects or surfaces, and irregularly shaped objects can cause flickering artifacts, especially when target viewpoints differ significantly from the input images.





COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
-
VFX pipeline – Render Wall management topics
-
The CG Career YouTube channel is live!
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
Python and TCL: Tips and Tricks for Foundry Nuke
-
copypastecharacter.com – alphabets, special characters and symbols library
-
Kling 1.6 and competitors – advanced tests and comparisons
-
Emmanuel Tsekleves – Writing Research Papers
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
