


-
Chongqing the world’s largest city in pictures
https://www.theguardian.com/world/gallery/2025/apr/27/chongqing-the-worlds-largest-city-in-pictures
The largest city in the world is as big as Austria, but few people have ever heard of it. The megacity of 34 million people in central of China is the emblem of the fastest urban revolution on the planet.




-
Fluent 4.0 released for Blender hard surface modeler
Beyond the boolean support, this add-on also provides cloth panel, grid, head screw, wire and pipe tool.
https://cgthoughts.gumroad.com/
https://superhivemarket.com/creators/cg-thoughts?ref=82

-
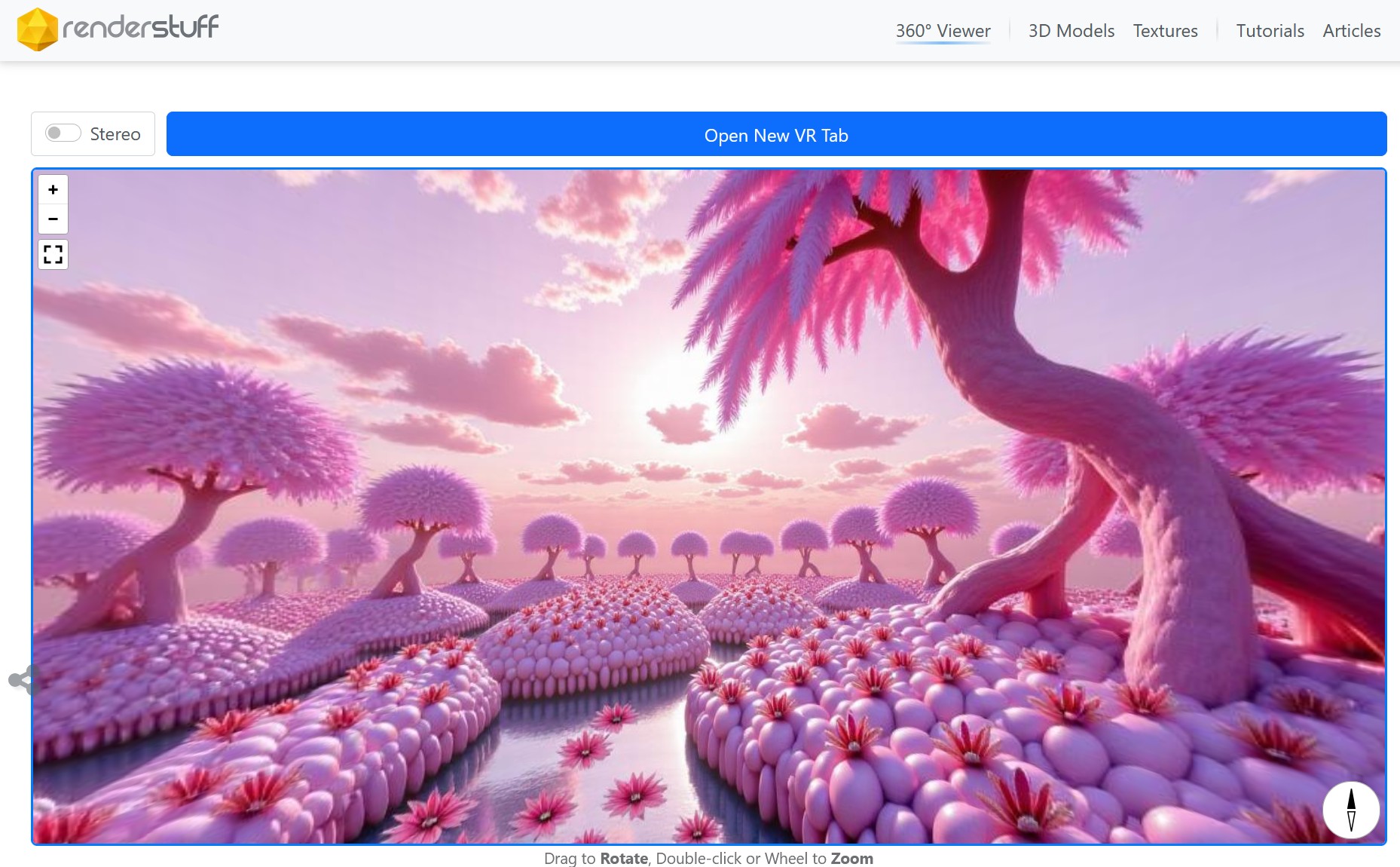
Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Flux
https://civitai.com/models/735980/flux-equirectangular-360-panorama
https://civitai.com/models/745010?modelVersionId=833115
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
8-bit output at the moment


-
Scientists claim to have discovered ‘new colour’ no one has seen before: Olo
https://www.bbc.com/news/articles/clyq0n3em41o
By stimulating specific cells in the retina, the participants claim to have witnessed a blue-green colour that scientists have called “olo”, but some experts have said the existence of a new colour is “open to argument”.
The findings, published in the journal Science Advances on Friday, have been described by the study’s co-author, Prof Ren Ng from the University of California, as “remarkable”.

(A) System inputs. (i) Retina map of 103 cone cells preclassified by spectral type (7). (ii) Target visual percept (here, a video of a child, see movie S1 at 1:04). (iii) Infrared cellular-scale imaging of the retina with 60-frames-per-second rolling shutter. Fixational eye movement is visible over the three frames shown.
(B) System outputs. (iv) Real-time per-cone target activation levels to reproduce the target percept, computed by: extracting eye motion from the input video relative to the retina map; identifying the spectral type of every cone in the field of view; computing the per-cone activation the target percept would have produced. (v) Intensities of visible-wavelength 488-nm laser microdoses at each cone required to achieve its target activation level.
(C) Infrared imaging and visible-wavelength stimulation are physically accomplished in a raster scan across the retinal region using AOSLO. By modulating the visible-wavelength beam’s intensity, the laser microdoses shown in (v) are delivered. Drawing adapted with permission [Harmening and Sincich (54)].
(D) Examples of target percepts with corresponding cone activations and laser microdoses, ranging from colored squares to complex imagery. Teal-striped regions represent the color “olo” of stimulating only M cones.
-
-
Finn Jager – From HEIC (High Efficiency Image Container) iPhone to a Multichannel EXR
Finn Jäger has spent some time in making a sleeker tool for all you VFX nerds out there, it takes a HEIC iPhone still and exports a Multichannel EXR – the cool thing is it also converts it to acesCG and it merges the SDR base image with the gain map according to apples math hdr_rgb = sdr_rgb * (1.0 + (headroom – 1.0) * gainmap)
https://github.com/finnschi/heic-shenanigans

-
Mars Lewis on the Brandolini’s Law
Brandolini’s law (or the bullshit asymmetry principle) is an internet adage coined in 2013 by Italian programmer Alberto Brandolini. It compares the considerable effort of debunking misinformation to the relative ease of creating it in the first place.
The law states: “The amount of energy needed to refute bullshit is an order of magnitude bigger than to produce it.”
https://en.wikipedia.org/wiki/Brandolini%27s_law
This is why every time you kill a lie, it feels like nothing changed. It’s why no matter how many facts you post, how many sources you cite, how many receipts you show—the swarm just keeps coming. Because while you’re out in the open doing surgery, the machine is behind the curtain spraying aerosol deceit into every vent.
The lie takes ten seconds. The truth takes ten paragraphs. And by the time you’ve written the tenth, the people you’re trying to reach have already scrolled past.
Every viral deception—the fake quote, the rigged video, the synthetic outrage—takes almost nothing to create. And once it’s out there, you’re not just correcting a fact—you’re prying it out of someone’s identity. Because people don’t adopt lies just for information. They adopt them for belonging. The lie becomes part of who they are, and your correction becomes an attack.
And still—you must correct it. Still, you must fight.
Because even if truth doesn’t spread as fast, it roots deeper. Even if it doesn’t go viral, it endures. And eventually, it makes people bulletproof to the next wave of narrative sewage.
You’re not here to win a one-day war. You’re here to outlast a never-ending invasion.
The lies are roaches. You kill one, and a hundred more scramble behind the drywall.The lies are Hydra heads. You cut one off, and two grow back. But you keep swinging anyway.
Because this isn’t about instant wins. It’s about making the cost of lying higher. It’s about being the resistance that doesn’t fold. You don’t fight because it’s easy. You fight because it’s right.
-
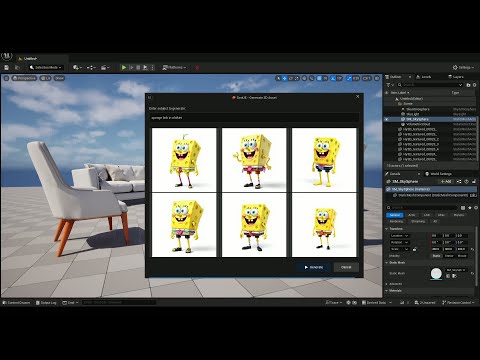
GenUE – Direct Prompt-to-Mesh Generation in Unreal Engine Integrated with ComfyUI
GenUE brings prompt-driven 3D asset creation directly into Unreal Engine using ComfyUI as a flexible backend. • Generate high-quality images from text prompts. • Choose from a catalog of batch-generated images – no style limitations. • Convert the selected image to a fully textured 3D mesh. • Automatically import and place the model into your Unreal Engine scene. This modular pipeline gives you full control over the image and 3D generation stages, with support for any ComfyUI workflow or model. Full generation (image + mesh + import) completes in under 2 minutes on a high-end consumer GPU.
-
Edward Ureña – Rig creator
https://edwardurena.gumroad.com/l/ramoo
What it offers:
• Base rigs for multiple character types
• Automatic weight application
• Built-in facial rigging system
• Bone generators with FK and IK options
• Streamlined constraint panel








COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Emmanuel Tsekleves – Writing Research Papers
-
Image rendering bit depth
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
Photography basics: Shutter angle and shutter speed and motion blur
-
Principles of Animation with Alan Becker, Dermot OConnor and Shaun Keenan
-
Want to build a start up company that lasts? Think three-layer cake
-
Ross Pettit on The Agile Manager – How tech firms went for prioritizing cash flow instead of talent
-
AI Search – Find The Best AI Tools & Apps
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
