


Featured AI
-
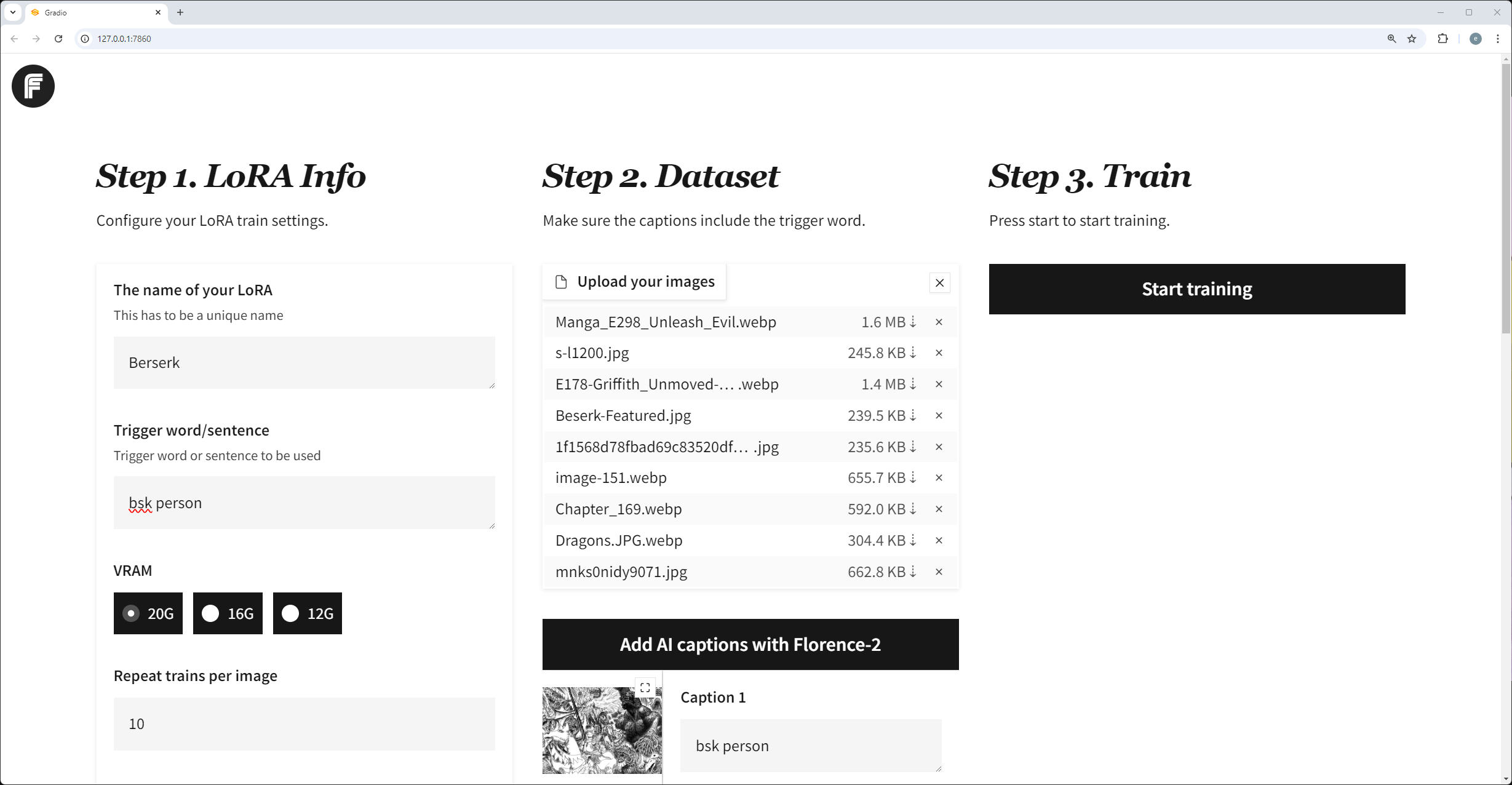
FluxGym – Simplified web UI for training FLUX LoRA locally with LOW VRAM (12GB/16GB/20GB) support
Read more: FluxGym – Simplified web UI for training FLUX LoRA locally with LOW VRAM (12GB/16GB/20GB) supporthttps://github.com/cocktailpeanut/fluxgym
https://pinokio.computer/item?uri=https://github.com/cocktailpeanut/fluxgym
-
Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Flux
Read more: Arto T. – A workflow for creating photorealistic, equirectangular 360° panoramas in ComfyUI using Fluxhttps://civitai.com/models/735980/flux-equirectangular-360-panorama
https://civitai.com/models/745010?modelVersionId=833115
The trigger phrase is “equirectangular 360 degree panorama”. I would avoid saying “spherical projection” since that tends to result in non-equirectangular spherical images.
Image resolution should always be a 2:1 aspect ratio. 1024 x 512 or 1408 x 704 work quite well and were used in the training data. 2048 x 1024 also works.
I suggest using a weight of 0.5 – 1.5. If you are having issues with the image generating too flat instead of having the necessary spherical distortion, try increasing the weight above 1, though this could negatively impact small details of the image. For Flux guidance, I recommend a value of about 2.5 for realistic scenes.
8-bit output at the moment


-
GPT-Image-1 API now available through ComfyUI with Dall-E integration
Read more: GPT-Image-1 API now available through ComfyUI with Dall-E integrationhttps://blog.comfy.org/p/comfyui-now-supports-gpt-image-1
https://docs.comfy.org/tutorials/api-nodes/openai/gpt-image-1
https://openai.com/index/image-generation-api
• Prompt GPT-Image-1 directly in ComfyUI using text or image inputs
• Set resolution and quality
• Supports image editing + transparent backgrounds
• Seamlessly mix with local workflows like WAN 2.1, FLUX Tools, and more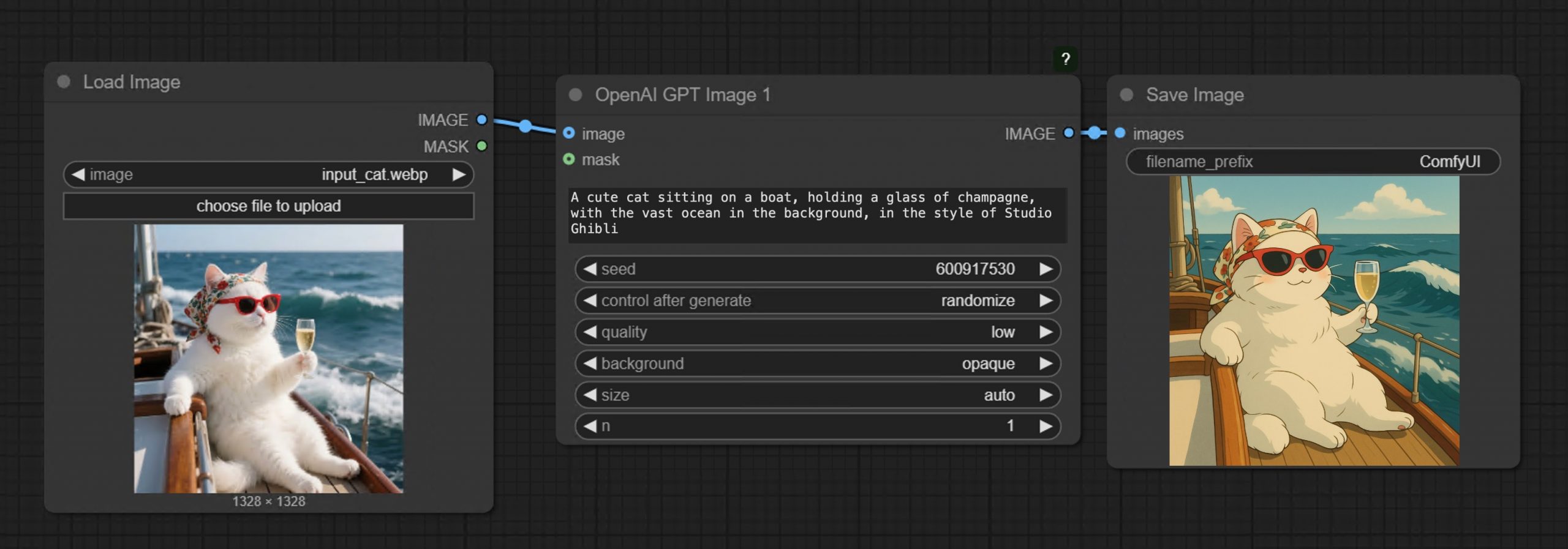
-
FramePack – Packing Input Frame Context in Next-Frame Prediction Models for Offline Video Generation With Low Resource Requirements
Read more: FramePack – Packing Input Frame Context in Next-Frame Prediction Models for Offline Video Generation With Low Resource Requirementshttps://lllyasviel.github.io/frame_pack_gitpage/
- Diffuse thousands of frames at full fps-30 with 13B models using 6GB laptop GPU memory.
- Finetune 13B video model at batch size 64 on a single 8xA100/H100 node for personal/lab experiments.
- Personal RTX 4090 generates at speed 2.5 seconds/frame (unoptimized) or 1.5 seconds/frame (teacache).
- No timestep distillation.
- Video diffusion, but feels like image diffusion.

Image-to-5-Seconds (30fps, 150 frames)
-
FreeCodeCamp – Train Your Own LLM
Read more: FreeCodeCamp – Train Your Own LLMhttps://www.freecodecamp.org/news/train-your-own-llm
Ever wondered how large language models like ChatGPT are actually built? Behind these impressive AI tools lies a complex but fascinating process of data preparation, model training, and fine-tuning. While it might seem like something only experts with massive resources can do, it’s actually possible to learn how to build your own language model from scratch. And with the right guidance, you can go from loading raw text data to chatting with your very own AI assistant.

-
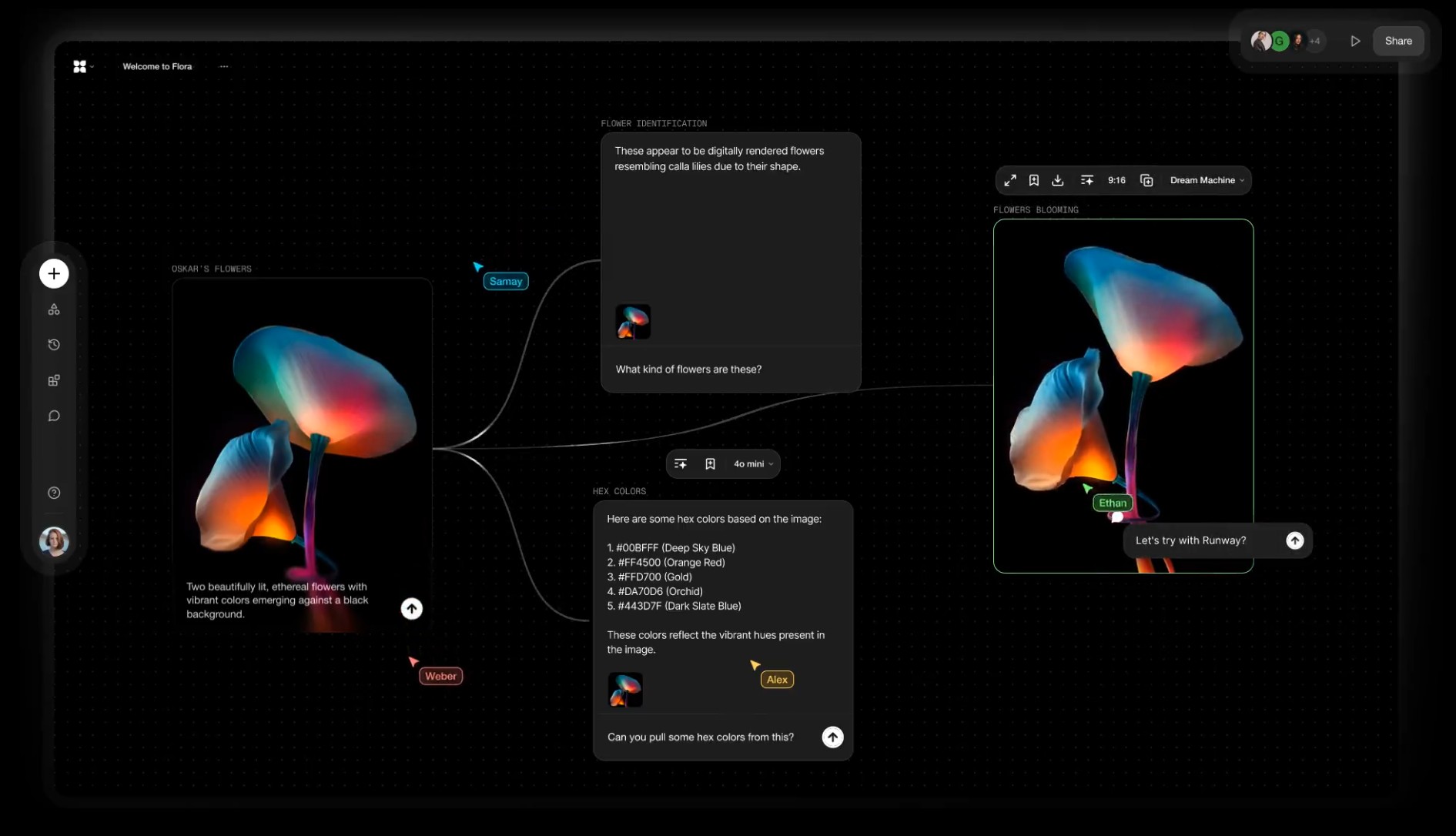
Alibaba FloraFauna.ai – AI Collaboration canvas
Read more: Alibaba FloraFauna.ai – AI Collaboration canvasFLORA aims to make generative creation accessible, removing the need for advanced technical skills or hardware. Drag, drop, and connect hand curated AI models to build your own creative workflows with a high degree of creative control.




-
Runway introduces Gen-4
Read more: Runway introduces Gen-4https://runwayml.com/research/introducing-runway-gen-4
With Gen-4, you are now able to precisely generate consistent characters, locations and objects across scenes. Simply set your look and feel and the model will maintain coherent world environments while preserving the distinctive style, mood and cinematographic elements of each frame. Then, regenerate those elements from multiple perspectives and positions within your scenes.
𝗛𝗲𝗿𝗲’𝘀 𝘄𝗵𝘆 𝗚𝗲𝗻-𝟰 𝗰𝗵𝗮𝗻𝗴𝗲𝘀 𝗲𝘃𝗲𝗿𝘆𝘁𝗵𝗶𝗻𝗴:
✨ 𝗨𝗻𝘄𝗮𝘃𝗲𝗿𝗶𝗻𝗴 𝗖𝗵𝗮𝗿𝗮𝗰𝘁𝗲𝗿 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆
• Characters and environments 𝗻𝗼𝘄 𝘀𝘁𝗮𝘆 𝗳𝗹𝗮𝘄𝗹𝗲𝘀𝘀𝗹𝘆 𝗰𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝘁 across shots—even as lighting shifts or angles pivot—all from one reference image. No more jarring transitions or mismatched details.
✨ 𝗗𝘆𝗻𝗮𝗺𝗶𝗰 𝗠𝘂𝗹𝘁𝗶-𝗔𝗻𝗴𝗹𝗲 𝗠𝗮𝘀𝘁𝗲𝗿𝘆
• Generate cohesive scenes from any perspective without manual tweaks. Gen-4 intuitively 𝗰𝗿𝗮𝗳𝘁𝘀 𝗺𝘂𝗹𝘁𝗶-𝗮𝗻𝗴𝗹𝗲 𝗰𝗼𝘃𝗲𝗿𝗮𝗴𝗲, 𝗮 𝗹𝗲𝗮𝗽 𝗽𝗮𝘀𝘁 𝗲𝗮𝗿𝗹𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹𝘀 that struggled with spatial continuity.
✨ 𝗣𝗵𝘆𝘀𝗶𝗰𝘀 𝗧𝗵𝗮𝘁 𝗙𝗲𝗲𝗹 𝗔𝗹𝗶𝘃𝗲
• Capes ripple, objects collide, and fabrics drape with startling realism. 𝗚𝗲𝗻-𝟰 𝘀𝗶𝗺𝘂𝗹𝗮𝘁𝗲𝘀 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝗽𝗵𝘆𝘀𝗶𝗰𝘀, breathing life into scenes that once demanded painstaking manual animation.
✨ 𝗦𝗲𝗮𝗺𝗹𝗲𝘀𝘀 𝗦𝘁𝘂𝗱𝗶𝗼 𝗜𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗶𝗼𝗻
• Outputs now blend effortlessly with live-action footage or VFX pipelines. 𝗠𝗮𝗷𝗼𝗿 𝘀𝘁𝘂𝗱𝗶𝗼𝘀 𝗮𝗿𝗲 𝗮𝗹𝗿𝗲𝗮𝗱𝘆 𝗮𝗱𝗼𝗽𝘁𝗶𝗻𝗴 𝗚𝗲𝗻-𝟰 𝘁𝗼 𝗽𝗿𝗼𝘁𝗼𝘁𝘆𝗽𝗲 𝘀𝗰𝗲𝗻𝗲𝘀 𝗳𝗮𝘀𝘁𝗲𝗿 and slash production timelines.
• 𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀: Gen-4 erases the line between AI experiments and professional filmmaking. 𝗗𝗶𝗿𝗲𝗰𝘁𝗼𝗿𝘀 𝗰𝗮𝗻 𝗶𝘁𝗲𝗿𝗮𝘁𝗲 𝗼𝗻 𝗰𝗶𝗻𝗲𝗺𝗮𝘁𝗶𝗰 𝘀𝗲𝗾𝘂𝗲𝗻𝗰𝗲𝘀 𝗶𝗻 𝗱𝗮𝘆𝘀, 𝗻𝗼𝘁 𝗺𝗼𝗻𝘁𝗵𝘀—democratizing access to tools that once required million-dollar budgets.

-
NormalCrafter – Learning Temporally Consistent Normals from Video Diffusion Priors
Read more: NormalCrafter – Learning Temporally Consistent Normals from Video Diffusion Priorshttps://normalcrafter.github.io
https://github.com/Binyr/NormalCrafter
https://huggingface.co/spaces/Yanrui95/NormalCrafter
https://huggingface.co/Yanrui95/NormalCrafter

-
Comfy-Org comfy-cli – A Command Line Tool for ComfyUI
Read more: Comfy-Org comfy-cli – A Command Line Tool for ComfyUIhttps://github.com/Comfy-Org/comfy-cli
comfy-cli is a command line tool that helps users easily install and manage ComfyUI, a powerful open-source machine learning framework. With comfy-cli, you can quickly set up ComfyUI, install packages, and manage custom nodes, all from the convenience of your terminal.
C:\<PATH_TO>\python.exe -m venv C:\comfyUI_cli_install cd C:\comfyUI_env C:\comfyUI_env\Scripts\activate.bat C:\<PATH_TO>\python.exe -m pip install comfy-cli comfy --workspace=C:\comfyUI_env\ComfyUI install # then comfy launch # or comfy launch -- --cpu --listen 0.0.0.0If you are trying to clone a different install, pip freeze it first. Then run those requirements.
# from the original env python.exe -m pip freeze > M:\requirements.txt # under the new venv env pip install -r M:\requirements.txt
-
HoloPart -Generative 3D Models Part Amodal Segmentation
Read more: HoloPart -Generative 3D Models Part Amodal Segmentationhttps://vast-ai-research.github.io/HoloPart
https://huggingface.co/VAST-AI/HoloPart
https://github.com/VAST-AI-Research/HoloPart
Applications:
– 3d printing segmentation
– texturing segmentation
– animation segmentation
– modeling segmentation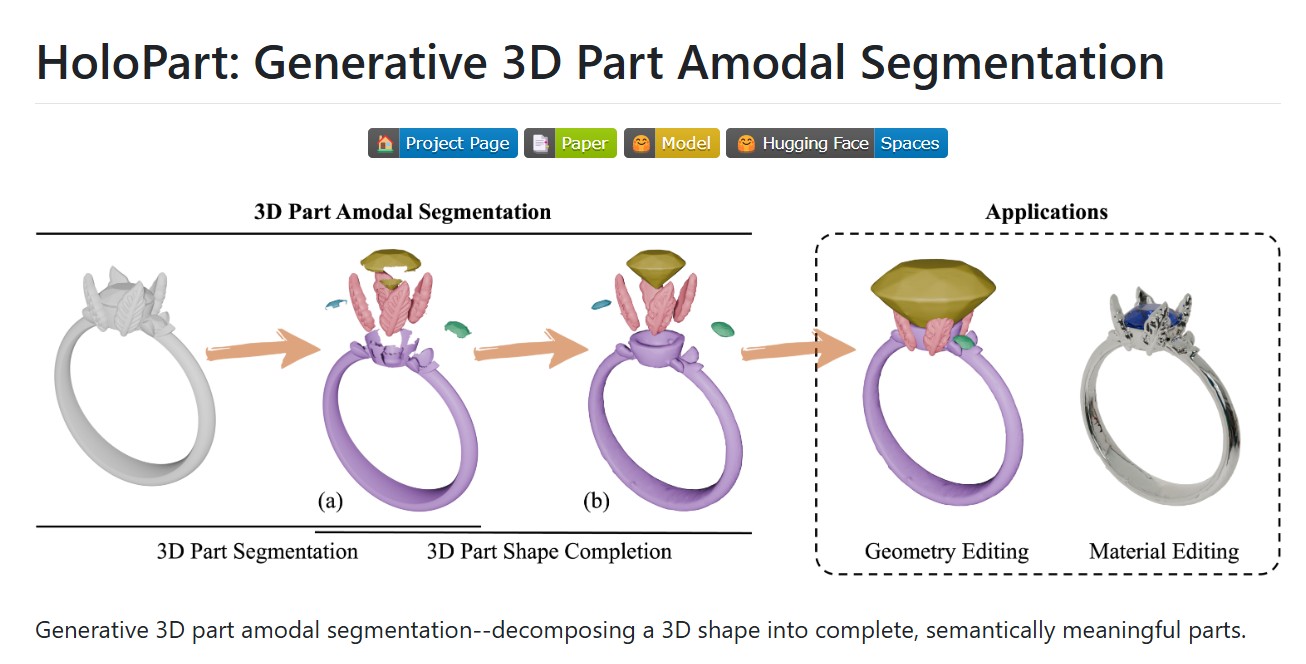
-
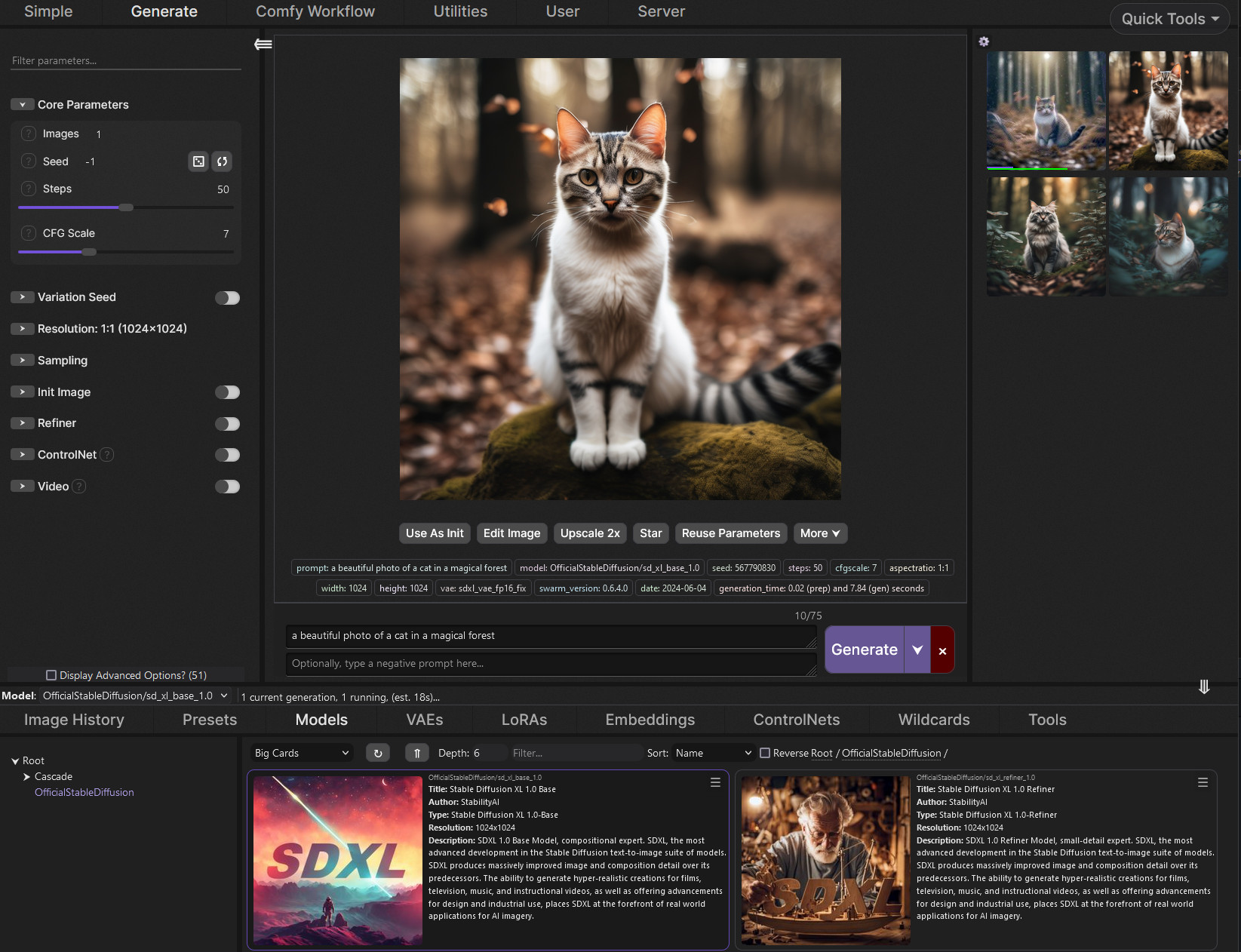
SwarmUI.net – A free, open source, modular AI image generation Web-User-Interface
Read more: SwarmUI.net – A free, open source, modular AI image generation Web-User-Interfacehttps://github.com/mcmonkeyprojects/SwarmUI
A Modular AI Image Generation Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. Supports AI image models (Stable Diffusion, Flux, etc.), and AI video models (LTX-V, Hunyuan Video, Cosmos, Wan, etc.), with plans to support eg audio and more in the future.
SwarmUI by default runs entirely locally on your own computer. It does not collect any data from you.
SwarmUI is 100% Free-and-Open-Source software, under the MIT License. You can do whatever you want with it.
-
VACE – All-in-One Video Creation and Editing
Read more: VACE – All-in-One Video Creation and Editinghttps://ali-vilab.github.io/VACE-Page
https://github.com/ali-vilab/VACE
https://huggingface.co/collections/ali-vilab/vace-67eca186ff3e3564726aff38
https://github.com/kijai/ComfyUI-WanVideoWrapper/tree/main/example_workflows

-
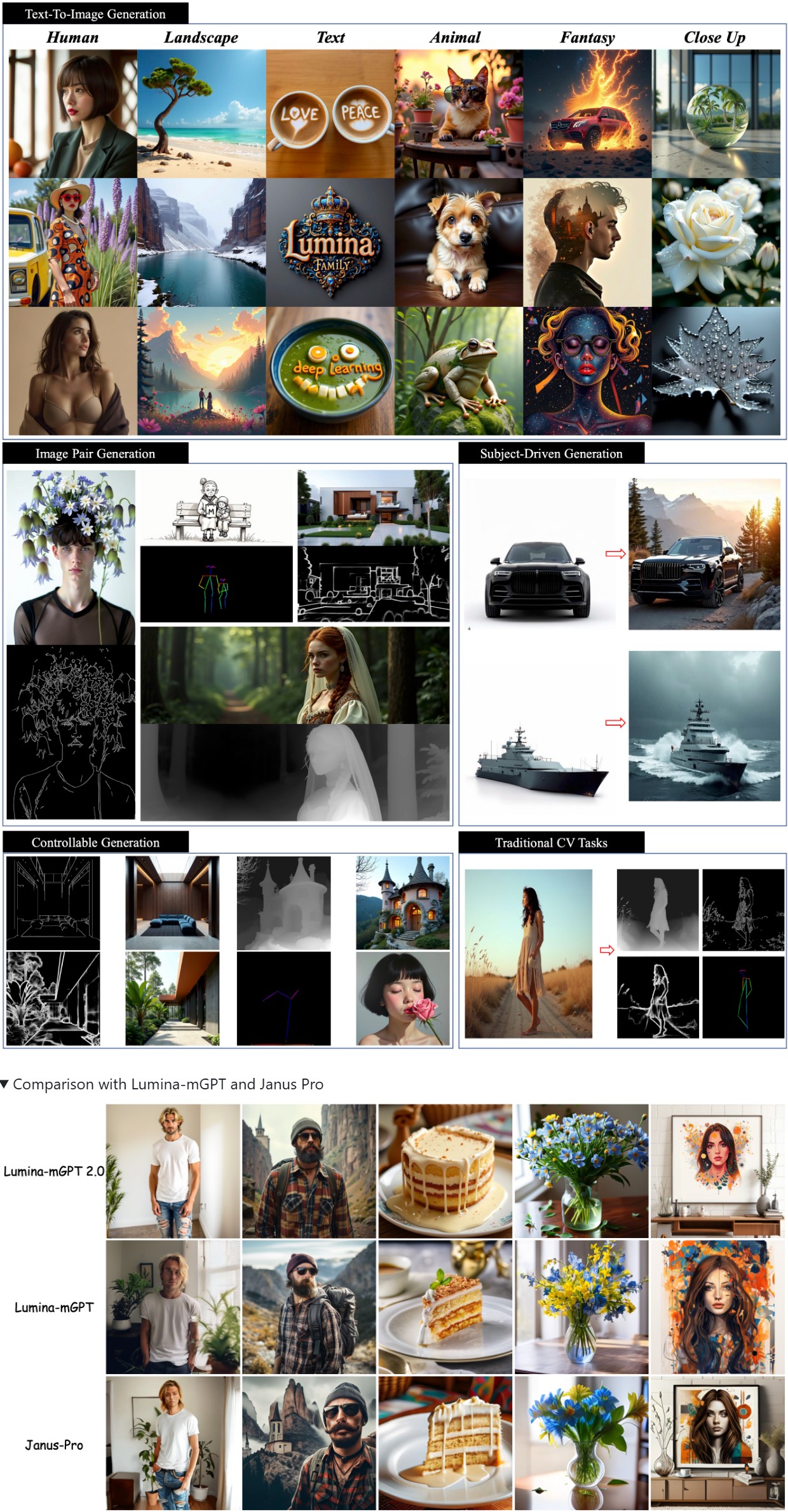
Lumina-mGPT 2.0 – Stand-alone Autoregressive Image Modeling
Read more: Lumina-mGPT 2.0 – Stand-alone Autoregressive Image ModelingA stand-alone, decoder-only autoregressive model, trained from scratch, that unifies a broad spectrum of image generation tasks, including text-to-image generation, image pair generation, subject-driven generation, multi-turn image editing, controllable generation, and dense prediction.
https://github.com/Alpha-VLLM/Lumina-mGPT-2.0
-
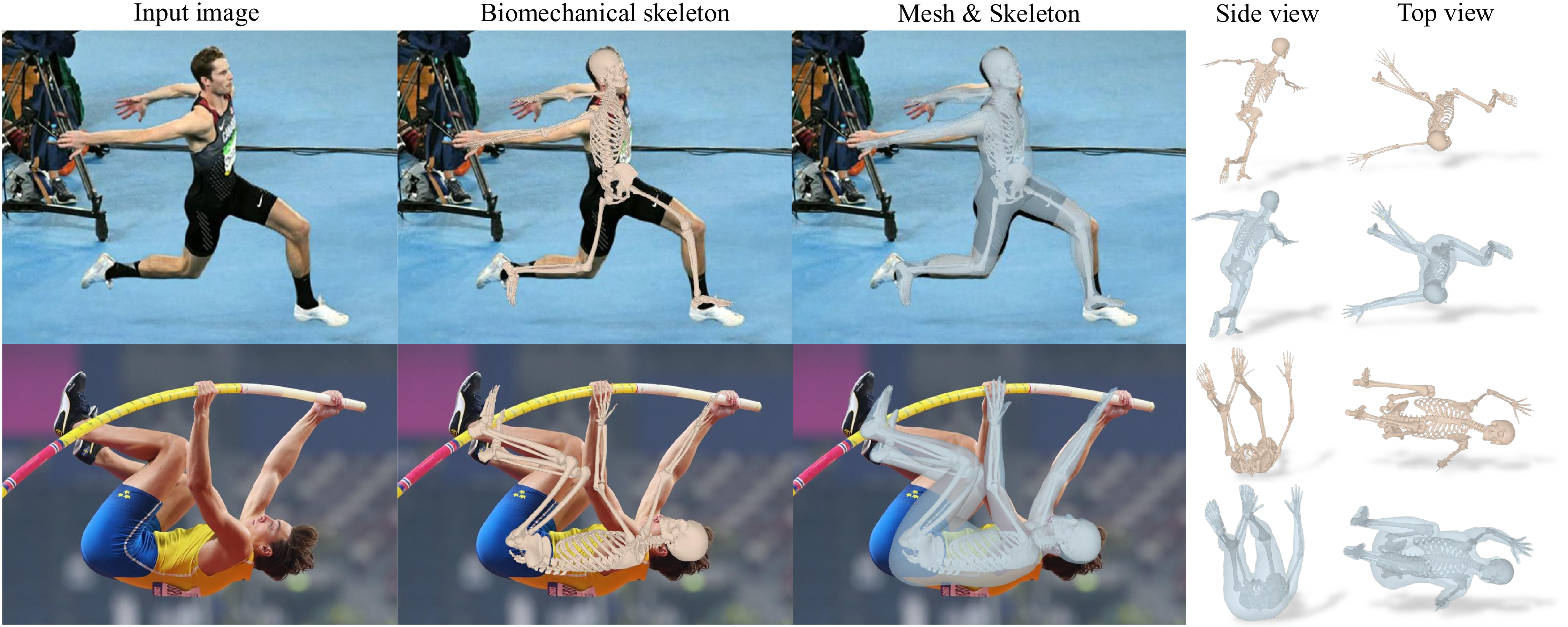
HSMR – Reconstructing Humans with a Biomechanically Accurate Skeleton
Read more: HSMR – Reconstructing Humans with a Biomechanically Accurate Skeletonhttps://isshikihugh.github.io/HSMR
https://github.com/IsshikiHugh/HSMR
https://huggingface.co/spaces/IsshikiHugh/HSMR
https://colab.research.google.com/drive/1RDA9iKckCDKh_bbaKjO8bQ0-Lv5fw1CB?usp=sharing
-
AccVideo – Accelerating Video Diffusion Model with Synthetic Dataset
Read more: AccVideo – Accelerating Video Diffusion Model with Synthetic Datasethttps://aejion.github.io/accvideo
https://github.com/aejion/AccVideo
https://huggingface.co/aejion/AccVideo
AccVideo is a novel efficient distillation method to accelerate video diffusion models with synthetic datset. This method is 8.5x faster than HunyuanVideo.

-
StarVector – A multimodal LLM for Scalable Vector Graphics (SVG) generation from images and text
Read more: StarVector – A multimodal LLM for Scalable Vector Graphics (SVG) generation from images and texthttps://huggingface.co/collections/starvector/starvector-models-6783b22c7bd4b43d13cb5289
https://github.com/joanrod/star-vector

-
Reve Image 1.0 Halfmoon – A new model trained from the ground up to excel at prompt adherence, aesthetics, and typography
Read more: Reve Image 1.0 Halfmoon – A new model trained from the ground up to excel at prompt adherence, aesthetics, and typographyA little-known AI image generator called Reve Image 1.0 is trying to make a name in the text-to-image space, potentially outperforming established tools like Midjourney, Flux, and Ideogram. Users receive 100 free credits to test the service after signing up, with additional credits available at $5 for 500 generations—pretty cheap when compared to options like MidJourney or Ideogram, which start at $8 per month and can reach $120 per month, depending on the usage. It also offers 20 free generations per day.





COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Kling 1.6 and competitors – advanced tests and comparisons
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
-
Python and TCL: Tips and Tricks for Foundry Nuke
-
How do LLMs like ChatGPT (Generative Pre-Trained Transformer) work? Explained by Deep-Fake Ryan Gosling
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
-
Ross Pettit on The Agile Manager – How tech firms went for prioritizing cash flow instead of talent
-
Top 3D Printing Website Resources
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
