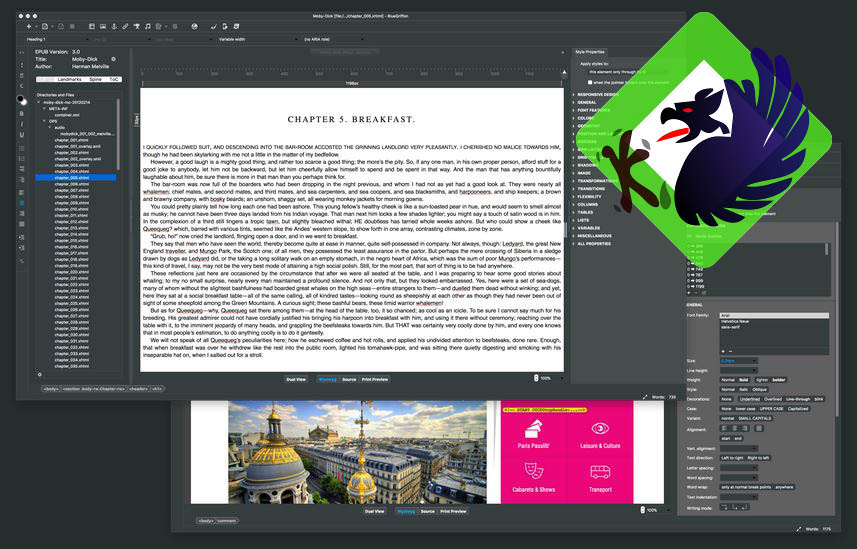
BlueGriffon is an open source WYSIWYG editor powered by Gecko, the rendering engine developed for Mozilla Firefox. One of a few derivatives of NVU, a now-discontinued HTML editor, BlueGriffon is the only actively developed NVU derivative that supports HTML5 as well as modern components of CSS.
If your goal is to write as little actual HTML as possible, then BlueGriffon is the tool you want. It’s a true drag-and-drop WYSIWYG website designer, and even includes a dual view option so you can see the code behind your design, in case you want to edit it or just learn from it.
It also supports the EPUB ebook format, so you don’t have to just publish to the web: you can provide your readers with a download of your content that they can take with them. Licensed under the MPL, GPL, and LGPL, a version of BlueGriffon is available for Linux, Windows, and Mac.
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.
OpenAI researchers fed the following Lord-of-the-Rings-style prompt to the system: Legolas and Gimli advanced on the orcs, raising their weapons with a harrowing war cry.
The computer composed this appropriately violent addition:
The orcs’ response was a deafening onslaught of claws, claws, and claws; even Elrond was forced to retreat. “You are in good hands, dwarf,” said Gimli, who had been among the first to charge at the orcs; it took only two words before their opponents were reduced to a blood-soaked quagmire, and the dwarf took his first kill of the night.”
The company’s decision to keep it from public use is the latest indication of a growing unease in and about the tech community about building cutting-edge technology — in particular AI —without setting limits on how it can be deployed.
Amazon and Microsoft in particular have voiced their support for legislation to regulate how facial recognition technology can and can’t be used. And Amazon investors and employees (as well as a dozens of civil rights groups) have urged the company to stop selling its face-recognition technology, Rekognition, to government agencies due to concerns it could be used to violate people’s rights.
The goal of the community driven apertus° project is to create a variety of powerful, free (in terms of liberty) and open cinema tools that we as filmmakers love to use.
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
OpenTrackIO defines the schema of JSON samples that contain a wide range of metadata about the device, its transform(s), associated camera and lens. The full schema is given below and can be downloaded here.
Working for a VFX (Visual Effects) studio provides numerous opportunities to leverage the power of Python and OpenCV for various tasks. OpenCV is a versatile computer vision library that can be applied to many aspects of the VFX pipeline. Here’s a detailed list of opportunities to take advantage of Python and OpenCV in a VFX studio:
Image and Video Processing:
Preprocessing: Python and OpenCV can be used for tasks like resizing, color correction, noise reduction, and frame interpolation to prepare images and videos for further processing.
Format Conversion: Convert between different image and video formats using OpenCV’s capabilities.
Tracking and Matchmoving:
Feature Detection and Tracking: Utilize OpenCV to detect and track features in image sequences, which is essential for matchmoving tasks to integrate computer-generated elements into live-action footage.
Rotoscoping and Masking:
Segmentation and Masking: Use OpenCV for creating and manipulating masks and alpha channels for various VFX tasks, like isolating objects or characters from their backgrounds.
Camera Calibration:
Intrinsic and Extrinsic Calibration: Python and OpenCV can help calibrate cameras for accurate 3D scene reconstruction and camera tracking.
3D Scene Reconstruction:
Stereoscopy: Use OpenCV to process stereoscopic image pairs for creating 3D depth maps and generating realistic 3D scenes.
Structure from Motion (SfM): Implement SfM techniques to create 3D models from 2D image sequences.
Green Screen and Blue Screen Keying:
Chroma Keying: Implement advanced keying algorithms using OpenCV to seamlessly integrate actors and objects into virtual environments.
Particle and Fluid Simulations:
Particle Tracking: Utilize OpenCV to track and manipulate particles in fluid simulations for more realistic visual effects.
Motion Analysis:
Optical Flow: Implement optical flow algorithms to analyze motion patterns in footage, useful for creating dynamic VFX elements that follow the motion of objects.
Virtual Set Extension:
Camera Projection: Use camera calibration techniques to project virtual environments onto physical sets, extending the visual scope of a scene.
Color Grading:
Color Correction: Implement custom color grading algorithms to match the color tones and moods of different shots.
Automated QC (Quality Control):
Artifact Detection: Develop Python scripts to automatically detect and flag visual artifacts like noise, flicker, or compression artifacts in rendered frames.
Data Analysis and Visualization:
Performance Metrics: Use Python to analyze rendering times and optimize the rendering process.
Data Visualization: Generate graphs and charts to visualize render farm usage, project progress, and resource allocation.
Automating Repetitive Tasks:
Batch Processing: Automate repetitive tasks like resizing images, applying filters, or converting file formats across multiple shots.
Machine Learning Integration:
Object Detection: Integrate machine learning models (using frameworks like TensorFlow or PyTorch) to detect and track specific objects or elements within scenes.
Pipeline Integration:
Custom Tools: Develop Python scripts and tools to integrate OpenCV-based processes seamlessly into the studio’s pipeline.
Real-time Visualization:
Live Previsualization: Implement real-time OpenCV-based visualizations to aid decision-making during the preproduction stage.
VR and AR Integration:
Augmented Reality: Use Python and OpenCV to integrate virtual elements into real-world footage, creating compelling AR experiences.
Camera Effects:
Lens Distortion: Correct lens distortions and apply various camera effects using OpenCV, contributing to the desired visual style.
Interpolating frames from an EXR sequence using OpenCV can be useful when you have only every second frame of a final render and you want to create smoother motion by generating intermediate frames. However, keep in mind that interpolating frames might not always yield perfect results, especially if there are complex changes between frames. Here’s a basic example of how you might use OpenCV to achieve this:
import cv2
import numpy as np
import os
# Replace with the path to your EXR frames
exr_folder = "path_to_exr_frames"
# Replace with the appropriate frame extension and naming convention
frame_template = "frame_{:04d}.exr"
# Define the range of frame numbers you have
start_frame = 1
end_frame = 100
step = 2
# Define the output folder for interpolated frames
output_folder = "output_interpolated_frames"
os.makedirs(output_folder, exist_ok=True)
# Loop through the frame range and interpolate
for frame_num in range(start_frame, end_frame + 1, step):
frame_path = os.path.join(exr_folder, frame_template.format(frame_num))
next_frame_path = os.path.join(exr_folder, frame_template.format(frame_num + step))
if os.path.exists(frame_path) and os.path.exists(next_frame_path):
frame = cv2.imread(frame_path, cv2.IMREAD_ANYDEPTH | cv2.IMREAD_COLOR)
next_frame = cv2.imread(next_frame_path, cv2.IMREAD_ANYDEPTH | cv2.IMREAD_COLOR)
# Interpolate frames using simple averaging
interpolated_frame = (frame + next_frame) / 2
# Save interpolated frame
output_path = os.path.join(output_folder, frame_template.format(frame_num))
cv2.imwrite(output_path, interpolated_frame)
print(f"Interpolated frame {frame_num}") # alternatively: print("Interpolated frame {}".format(frame_num))
Please note the following points:
The above example uses simple averaging to interpolate frames. More advanced interpolation methods might provide better results, such as motion-based algorithms like optical flow-based interpolation.
EXR files can store high dynamic range (HDR) data, so make sure to use cv2.IMREAD_ANYDEPTH flag when reading these files.
OpenCV might not support EXR format directly. You might need to use a library like exr to read and manipulate EXR files, and then convert them to OpenCV-compatible formats.
Consider the characteristics of your specific render when using interpolation. If there are large changes between frames, the interpolation might lead to artifacts.
Experiment with different interpolation methods and parameters to achieve the desired result.
For a more advanced and accurate interpolation, you might need to implement or use existing algorithms that take into account motion estimation and compensation.
If you have no previous experience with Unity, start with these six video tutorials which give a quick overview of the Unity interface and some important features http://unity3d.com/support/documentation/video/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.
If you’re serious about protecting your IP, client relationships, and professional credibility, you need to stop treating generative AI tools like consumer-grade apps. This isn’t about fear, it’s about operational discipline. Below are immediate steps you can take to reduce your exposure and stay in control of your creative pipeline.
Use ChatGPT via the API, not the public app, for any sensitive data.
Isolate ComfyUI to a sandboxed VM, Docker container, or offline machine.
Audit every custom node, don’t blindly trust GitHub links or ComfyUI workflows
Educate your team, a single mistake can leak an unreleased game asset, a feature film script, or trade secrets.
Kartaverse is a free open source post-production pipeline that is optimized for the immersive media sector. If you can imagine it, Kartaverse can help you create it in XR!
“Karta” is the Swedish word for map. With KartaVR you can stitch, composite, retouch, and remap any kind of panoramic video: from any projection to any projection. This provides the essential tools for 360VR, panoramic video stitching, depthmap, lightfield, and fulldome image editing workflows.
Kartaverse makes it a breeze to accessibly and affordably create content for use with virtual reality HMDs (head mounted displays) and fulldome theatres by providing ready to go scripts, templates, plugins, and command-line tools that allow you to work efficiently with XR media. The toolset works inside of Blackmagic Design’s powerful node based Fusion Studio and DaVinci Resolve Studio software.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.