https://www.youtube.com/watch?v=9u_08—oEw




3Dprinting (178) A.I. (833) animation (348) blender (206) colour (233) commercials (52) composition (152) cool (361) design (646) Featured (79) hardware (311) IOS (109) jokes (138) lighting (288) modeling (144) music (186) photogrammetry (189) photography (754) production (1287) python (91) quotes (496) reference (314) software (1350) trailers (305) ves (549) VR (221)
The combination brings together NVIDIA’s leading AI computing platform with Arm’s vast ecosystem to create the premier computing company for the age of artificial intelligence, accelerating innovation while expanding into large, high-growth markets.
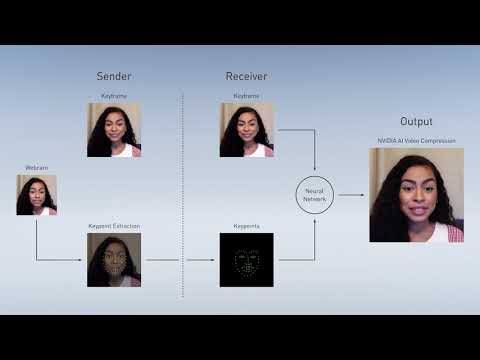
Marbles runs on a single Quadro RTX 8000 simulating complex physics in a real-time ray traced world.

blogs.nvidia.com/blog/2019/03/18/omniverse-collaboration-platform/

developer.nvidia.com/nvidia-omniverse
An open, Interactive 3D Design Collaboration Platform for Multi-Tool Workflows to simplify studio workflows for real-time graphics.
It supports Pixar’s Universal Scene Description technology for exchanging information about modeling, shading, animation, lighting, visual effects and rendering across multiple applications.
It also supports NVIDIA’s Material Definition Language, which allows artists to exchange information about surface materials across multiple tools.
With Omniverse, artists can see live updates made by other artists working in different applications. They can also see changes reflected in multiple tools at the same time.
For example an artist using Maya with a portal to Omniverse can collaborate with another artist using UE4 and both will see live updates of each others’ changes in their application.
www.nvidia.com/en-us/design-visualization/technologies/material-definition-language/
THE NVIDIA MATERIAL DEFINITION LANGUAGE (MDL) gives you the freedom to share physically based materials and lights between supporting applications.
For example, create an MDL material in an application like Allegorithmic Substance Designer, save it to your library, then use it in NVIDIA® Iray® or Chaos Group’s V-Ray, or any other supporting application.
Unlike a shading language that produces programs for a particular renderer, MDL materials define the behavior of light at a high level. Different renderers and tools interpret the light behavior and create the best possible image.

As point cloud processing becomes increasingly important across industries, I wanted to share the most powerful open-source tools I’ve used in my projects:
1️⃣ Open3D (http://www.open3d.org/)
The gold standard for point cloud processing in Python. Incredible visualization capabilities, efficient data structures, and comprehensive geometry processing functions. Perfect for both research and production.
2️⃣ PCL – Point Cloud Library (https://pointclouds.org/)
The C++ powerhouse of point cloud processing. Extensive algorithms for filtering, feature estimation, surface reconstruction, registration, and segmentation. Steep learning curve but unmatched performance.
3️⃣ PyTorch3D (https://pytorch3d.org/)
Facebook’s differentiable 3D library. Seamlessly integrates point cloud operations with deep learning. Essential if you’re building neural networks for 3D data.
4️⃣ PyTorch Geometric (https://lnkd.in/eCutwTuB)
Specializes in graph neural networks for point clouds. Implements cutting-edge architectures like PointNet, PointNet++, and DGCNN with optimized performance.
5️⃣ Kaolin (https://lnkd.in/eyj7QzCR)
NVIDIA’s 3D deep learning library. Offers differentiable renderers and accelerated GPU implementations of common point cloud operations.
6️⃣ CloudCompare (https://lnkd.in/emQtPz4d)
More than just visualization. This desktop application lets you perform complex processing without writing code. Perfect for quick exploration and comparison.
7️⃣ LAStools (https://lnkd.in/eRk5Bx7E)
The industry standard for LiDAR processing. Fast, scalable, and memory-efficient tools specifically designed for massive aerial and terrestrial LiDAR data.
8️⃣ PDAL – Point Data Abstraction Library (https://pdal.io/)
Think of it as “GDAL for point clouds.” Powerful for building processing pipelines and handling various file formats and coordinate transformations.
9️⃣ Open3D-ML (https://lnkd.in/eWnXufgG)
Extends Open3D with machine learning capabilities. Implementations of state-of-the-art 3D deep learning methods with consistent APIs.
🔟 MeshLab (https://www.meshlab.net/)
The Swiss Army knife for mesh processing. While primarily for meshes, its point cloud processing capabilities are excellent for cleanup, simplification, and reconstruction.

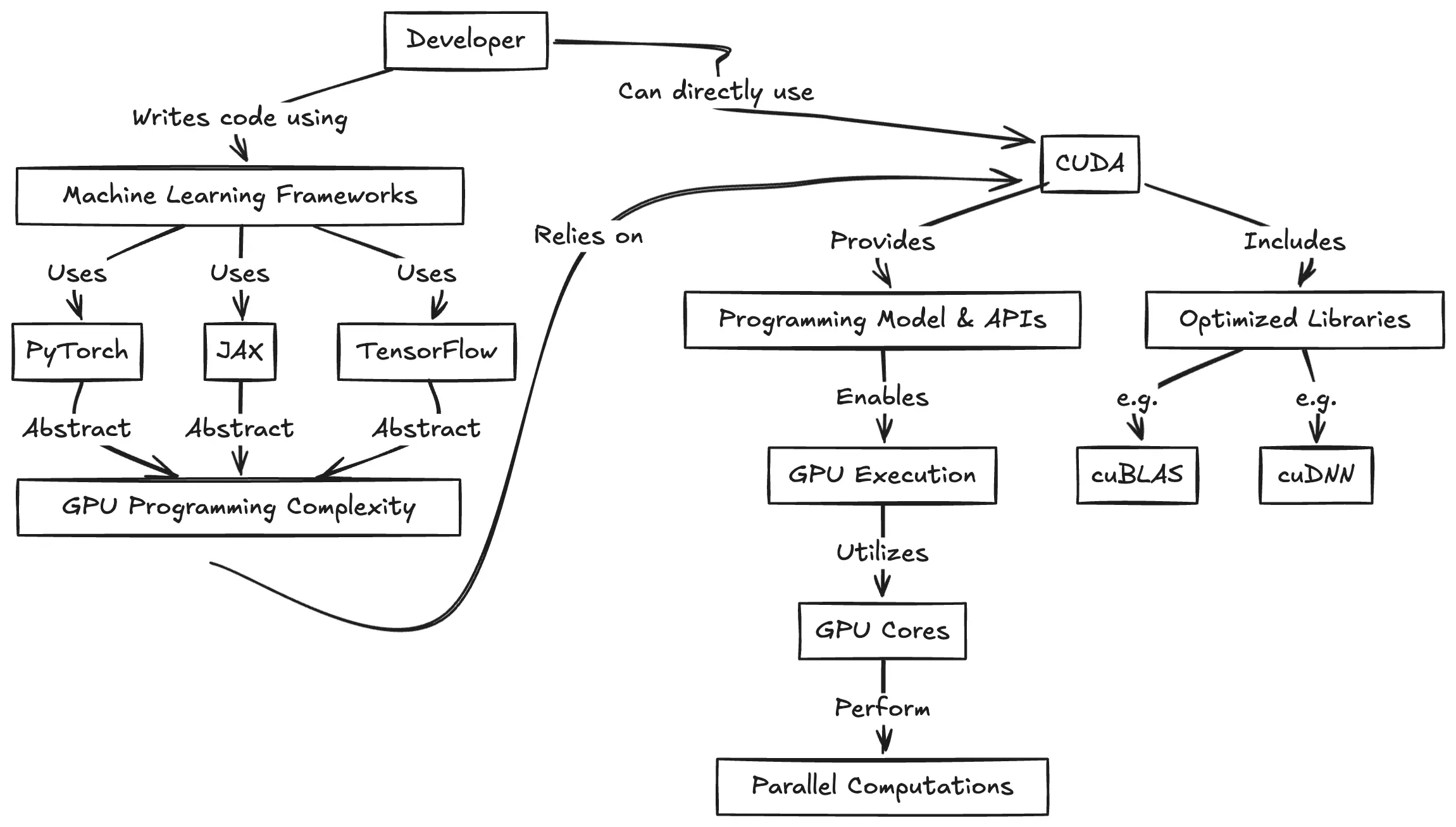
https://www.pyspur.dev/blog/introduction_cuda_programming
Check your Cuda version, it will be the release version here:
>>> nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Wed_Apr_17_19:36:51_Pacific_Daylight_Time_2024
Cuda compilation tools, release 12.5, V12.5.40
Build cuda_12.5.r12.5/compiler.34177558_0or from here:
>>> nvidia-smi
Mon Jun 16 12:35:20 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 555.85 Driver Version: 555.85 CUDA Version: 12.5 |
|-----------------------------------------+------------------------+----------------------+
https://www.seangoedecke.com/deepseek-r1
The Chinese AI lab DeepSeek recently released their new reasoning model R1, which is supposedly (a) better than the current best reasoning models (OpenAI’s o1- series), and (b) was trained on a GPU cluster a fraction the size of any of the big western AI labs.
DeepSeek uses a reinforcement learning approach, not a fine-tuning approach. There’s no need to generate a huge body of chain-of-thought data ahead of time, and there’s no need to run an expensive answer-checking model. Instead, the model generates its own chains-of-thought as it goes.
The secret behind their success? A bold move to train their models using FP8 (8-bit floating-point precision) instead of the standard FP32 (32-bit floating-point precision).
…
By using a clever system that applies high precision only when absolutely necessary, they achieved incredible efficiency without losing accuracy.
…
The impressive part? These multi-token predictions are about 85–90% accurate, meaning DeepSeek R1 can deliver high-quality answers at double the speed of its competitors.
Chinese AI firm DeepSeek has 50,000 NVIDIA H100 AI GPUs

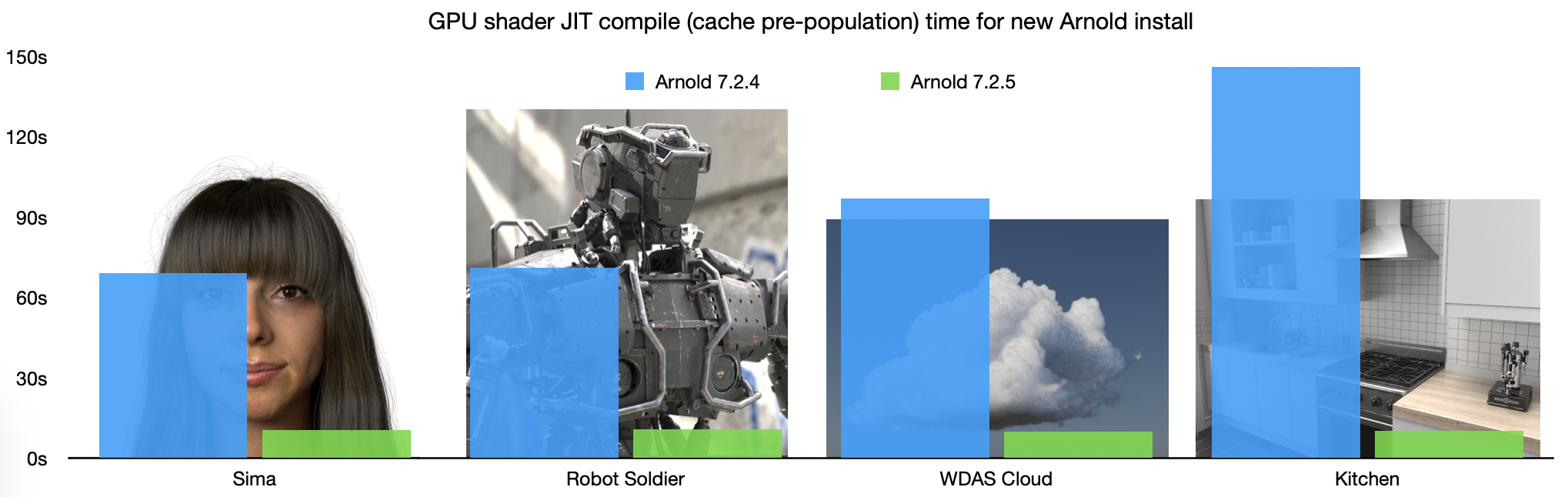
Arnold 7.2.5 adds support for NVIDIA and Intel GPU denoising on Windows in the Intel Denoiser. Denoising with a GPU using the Intel Denoiser should be now between 10x and 20x faster.
https://help.autodesk.com/view/ARNOL/ENU/?guid=arnold_core_7250_html
https://help.autodesk.com/view/ARNOL/ENU/?guid=arnold_user_guide_ac_denoising_html

AOV denoising: While all denoisers work on arbitrary AOVs, not all denoisers guarantee that the denoised AOVs composite together to match the denoised beauty. The AOV column indicates whether a denoiser has robust AOV denoising and can produce a result where denoised_AOV_1 + denoised_AOV_2 + … + denoised_AOV_N = denoised_Beauty.
OptiX™ Denoiser imager
This imager is available as a post-processing effect. The imager also exposes additional controls for clamping and blending the result. It is based on Nvidia AI technology and is integrated into Arnold for use with IPR and look dev. The OptiX™ denoiser is meant to be used during IPR (so that you get a very quickly denoised image as you’re moving the camera and making other adjustments).
OIDN Denoiser imager
The OIDN denoiser (based on Intel’s Open Image Denoise technology) is available as a post-processing effect. It is integrated into Arnold for use with IPR as an imager (so that you get a very quickly denoised image as you’re moving the camera and making other adjustments).
Arnold Denoiser (Noice)
The Arnold Denoiser (Noice) can be run from a dedicated UI, exposed in the Denoiser, or as an imager, you will need to render images out first via the Arnold EXR driver with variance AOVs enabled. It is also available as a stand-alone program (noice.exe).
This imager is available as a post-processing effect. You can automatically denoise images every time you render a scene, edit the denoising settings and see the resulting image directly in the render view. It favors quality over speed and is, therefore, more suitable for high-quality final frame denoising and animation sequences.
Note:
imager_denoiser_noice does not support temporal denoising (required for denoising an animation).
Text2Light
Royalty free links
Nvidia GauGAN360
https://github.com/autodesk/Aurora
Goals for Aurora
Features

Rob Legato, the award-winning FFX Supervisor whose work you may have seen in movies like Titanic, Avatar and The Jungle Book, is incredibly bullish on virtual production. At the Microsoft Production Summit, presented by NVIDIA NVDA +0.2%& Unreal Engine in Los Angeles, he reported that he recently did a movie with Ben Affleck and Matt Damon in twenty-four days, “Cutting down the days cut down the budget, and it’s amazing what a difference that can make. Productions can now do for $25 million what used to cost $100 million.”
NanoVDB, is NVIDIA’s version of the OpenVDB library. This solution offers one significant advantage over OpenVDB, namely GPU support. It accelerates processes such as filtering, volume rendering, collision detection, ray tracing, etc., and allows you to generate and load complex special effects, all in real time.
Nevertheless, the NanoVDB structure does not significantly compress volume size. Therefore, it’s not so commonly applied in game development.
github.com/eidosmontreal/unreal-vdb
Example file: https://lnkd.in/gMqmFwCj

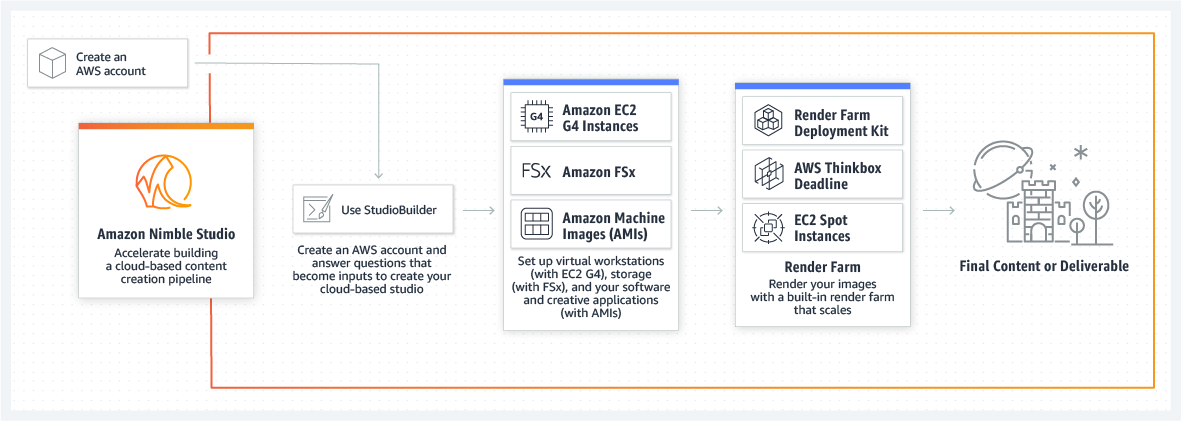
Using Amazon Nimble Studio, customers can create a new content production studio in just a few hours. Artists then have immediate access to high-performance workstations powered by Amazon Elastic Compute Cloud (EC2) G4dn instances with NVIDIA GPUs, shared file storage from Amazon FSx, and low-latency streaming via the AWS global network. Content production studios can onboard remote teams from around the world and provide them access to just the right amount of high-performance infrastructure for only as long as needed – all without having to procure, set up, and manage local workstations, file systems, and low-latency networking.

https://aws.amazon.com/nimble-studio
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.