GOT-OCR2 works on a wide range of tasks, including plain document OCR, scene text OCR, formatted document OCR, and even OCR for tables, charts, mathematical formulas, geometric shapes, molecular formulas and sheet music.
Arminas created this using Juggernaut Xl model and QR Code Monster SDXL ControlNet.
His pipeline: Static Images – Forge UI. Upscaled with Leonardo AI universal upscaler. Animated with Runway ML and Minimax. Video upscale – Topaz Video AI. Composited in Adobe Premiere.
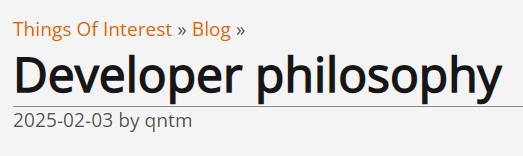
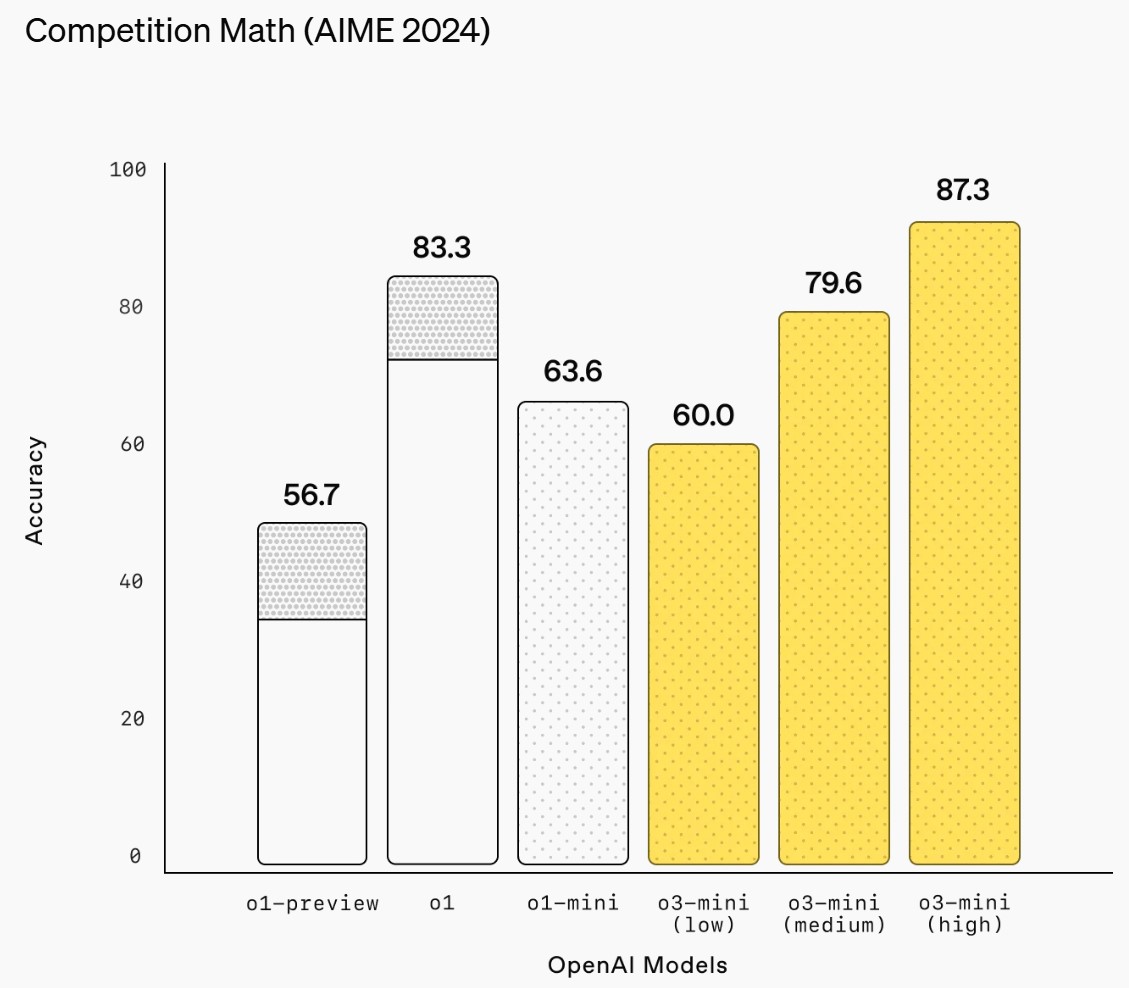
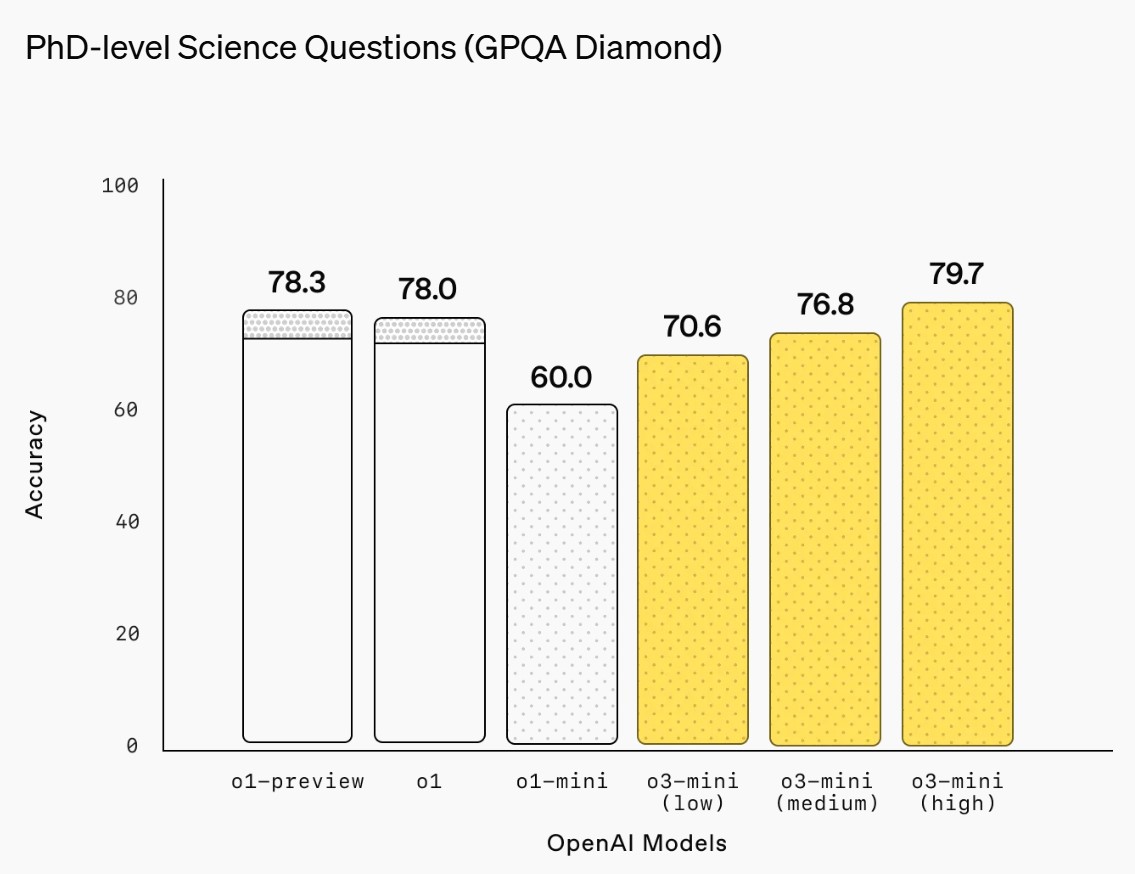
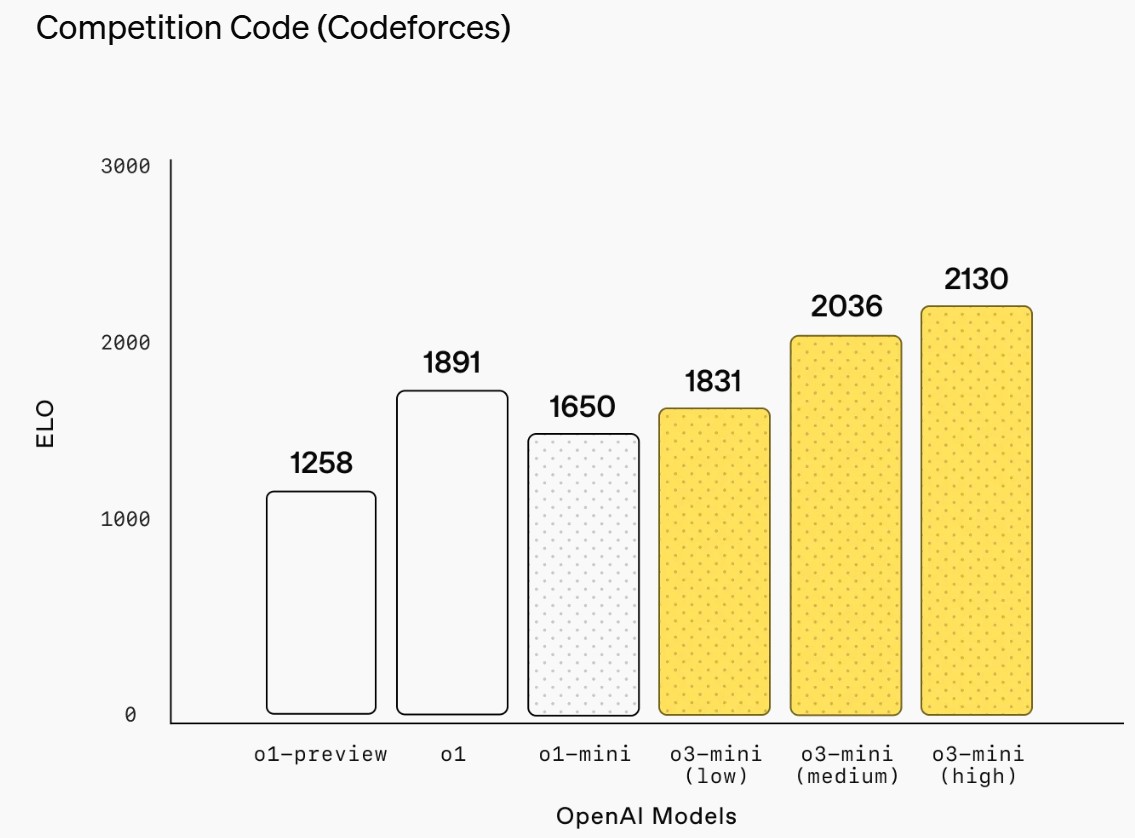
o3-mini does not support vision capabilities, so developers should continue using OpenAI o1 for visual reasoning tasks.
ChatGPT Plus, Team, and Pro users can access OpenAI o3-mini starting today, with Enterprise access coming in February. o3-mini will replace OpenAI o1-mini in the model picker, offering higher rate limits and lower latency, making it a compelling choice for coding, STEM, and logical problem-solving tasks.
As part of this upgrade, we’re tripling the rate limit for Plus and Team users from 50 messages per day with o1-mini to 150 messages per day with o3-mini.
Starting today, free plan users can also try OpenAI o3-mini by selecting ‘Reason’ in the message composer or by regenerating a response. This marks the first time a reasoning model has been made available to free users in ChatGPT.
Benchmarks don’t capture real-world complexity like latency, domain-specific tasks, or edge cases. Enterprises often need more than raw performance, also needing reliability, ease of integration, and robust vendor support. Enterprise money will support the industries providing these services.
… it is also reasonable to assume that anything you put into the app or their website will be going to the Chinese government as well, so factor that in as well.
Tneration models can create high-quality images from input prompts. However, they struggle to support the consistent generation of identity-preserving requirements for storytelling.
Our approach 1Prompt1Story concatenates all prompts into a single input for T2I diffusion models, initially preserving character identities.
The Chinese AI lab DeepSeek recently released their new reasoning model R1, which is supposedly (a) better than the current best reasoning models (OpenAI’s o1- series), and (b) was trained on a GPU cluster a fraction the size of any of the big western AI labs.
DeepSeek uses a reinforcement learning approach, not a fine-tuning approach. There’s no need to generate a huge body of chain-of-thought data ahead of time, and there’s no need to run an expensive answer-checking model. Instead, the model generates its own chains-of-thought as it goes.
The secret behind their success? A bold move to train their models using FP8 (8-bit floating-point precision) instead of the standard FP32 (32-bit floating-point precision). … By using a clever system that applies high precision only when absolutely necessary, they achieved incredible efficiency without losing accuracy. … The impressive part? These multi-token predictions are about 85–90% accurate, meaning DeepSeek R1 can deliver high-quality answers at double the speed of its competitors.
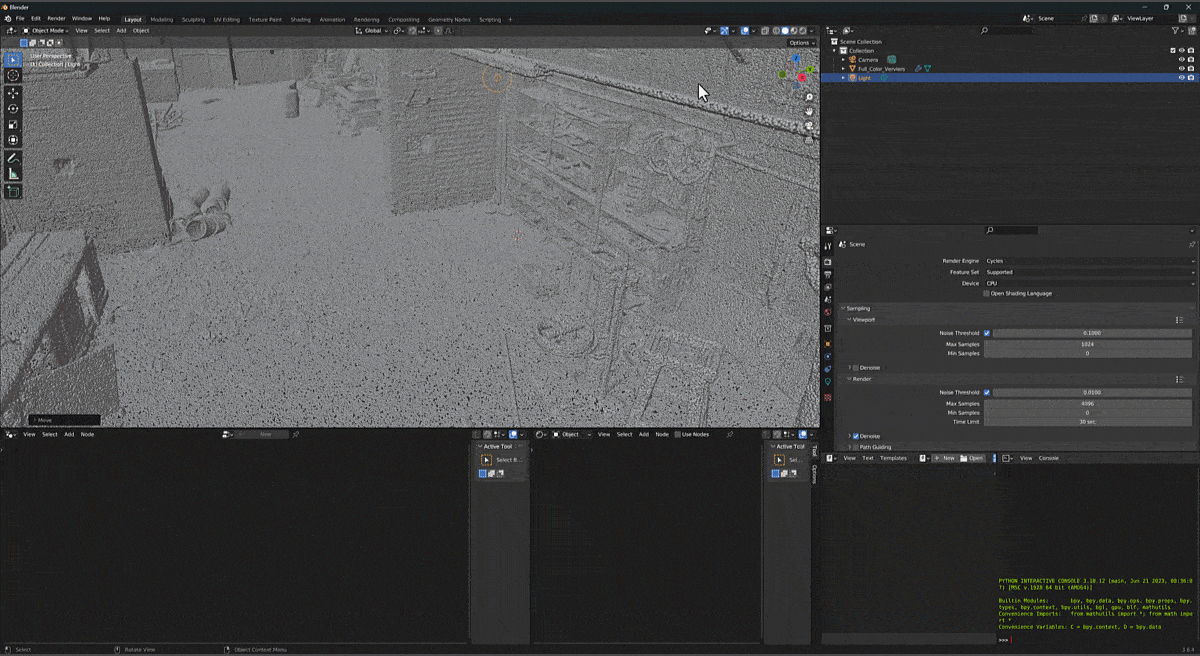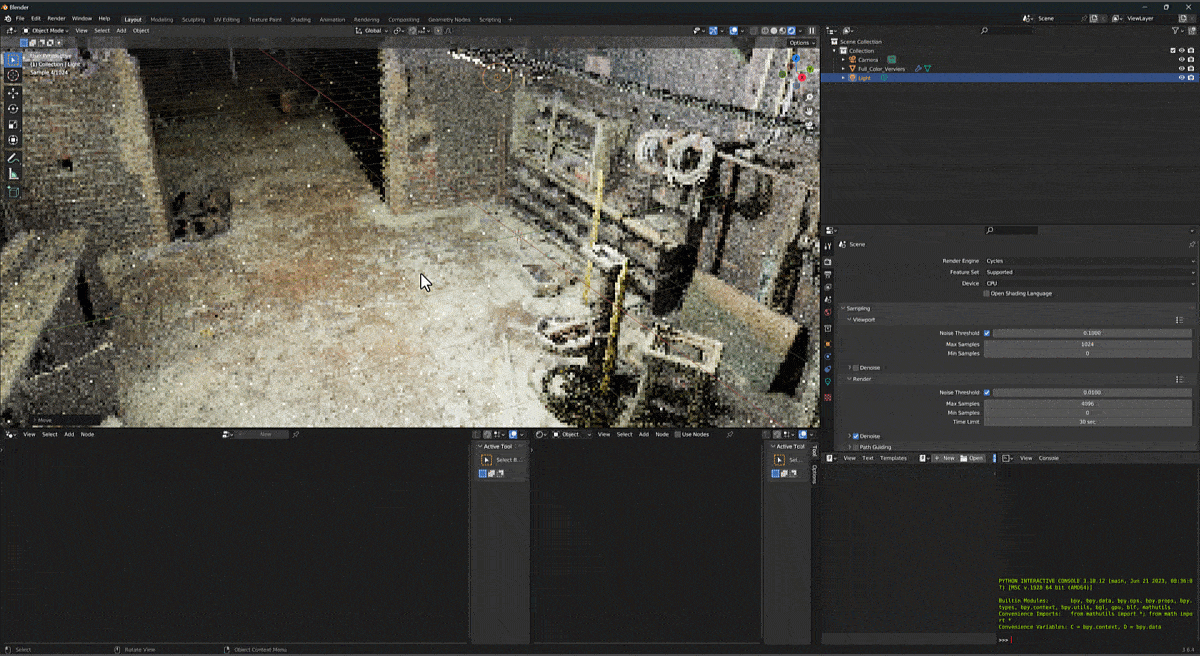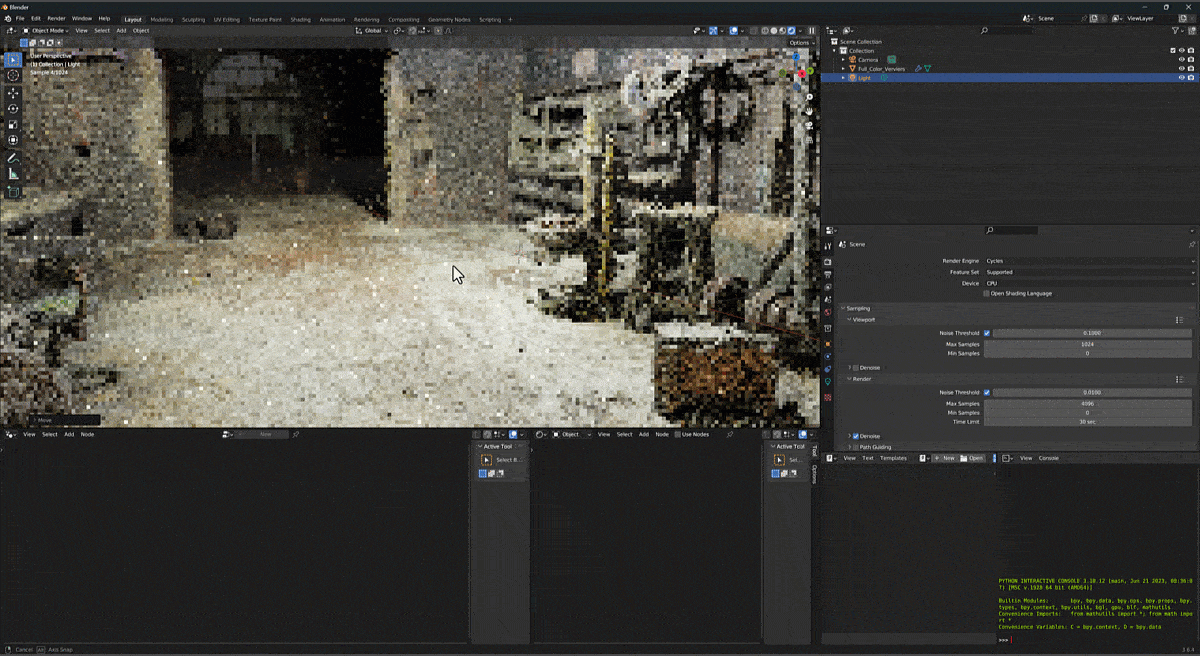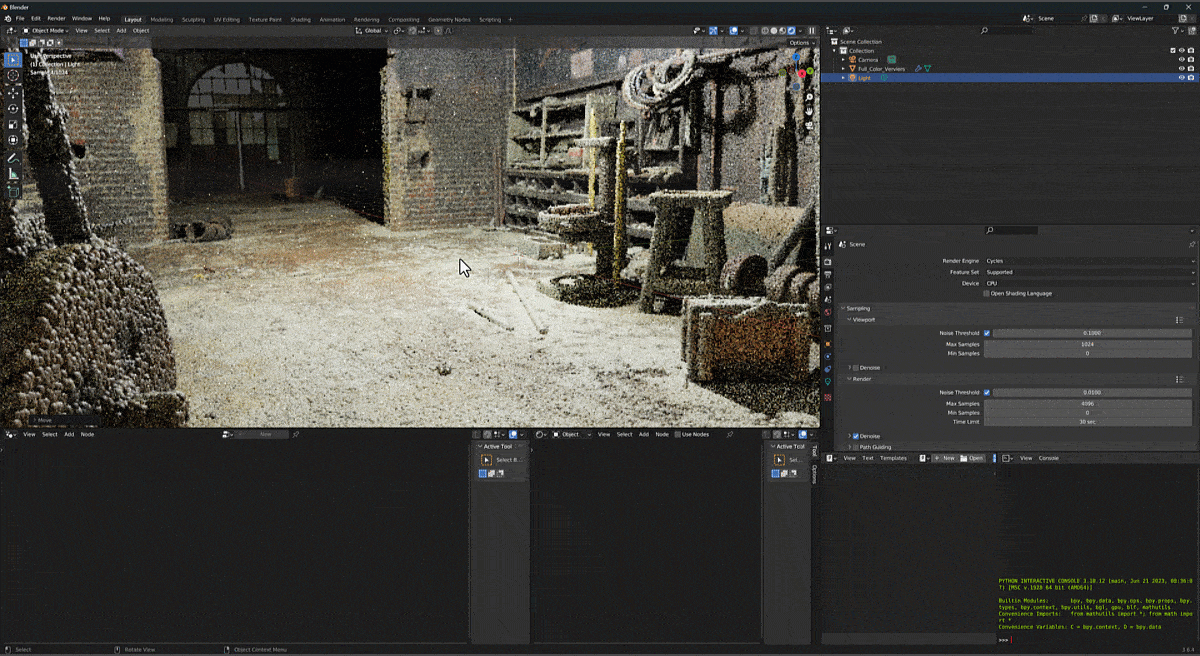
a novel method for generating hyper-quality 4K textured mesh under only 30 seconds, providing 3D assets ready for commercial applications such as games, movies, and VR/AR.
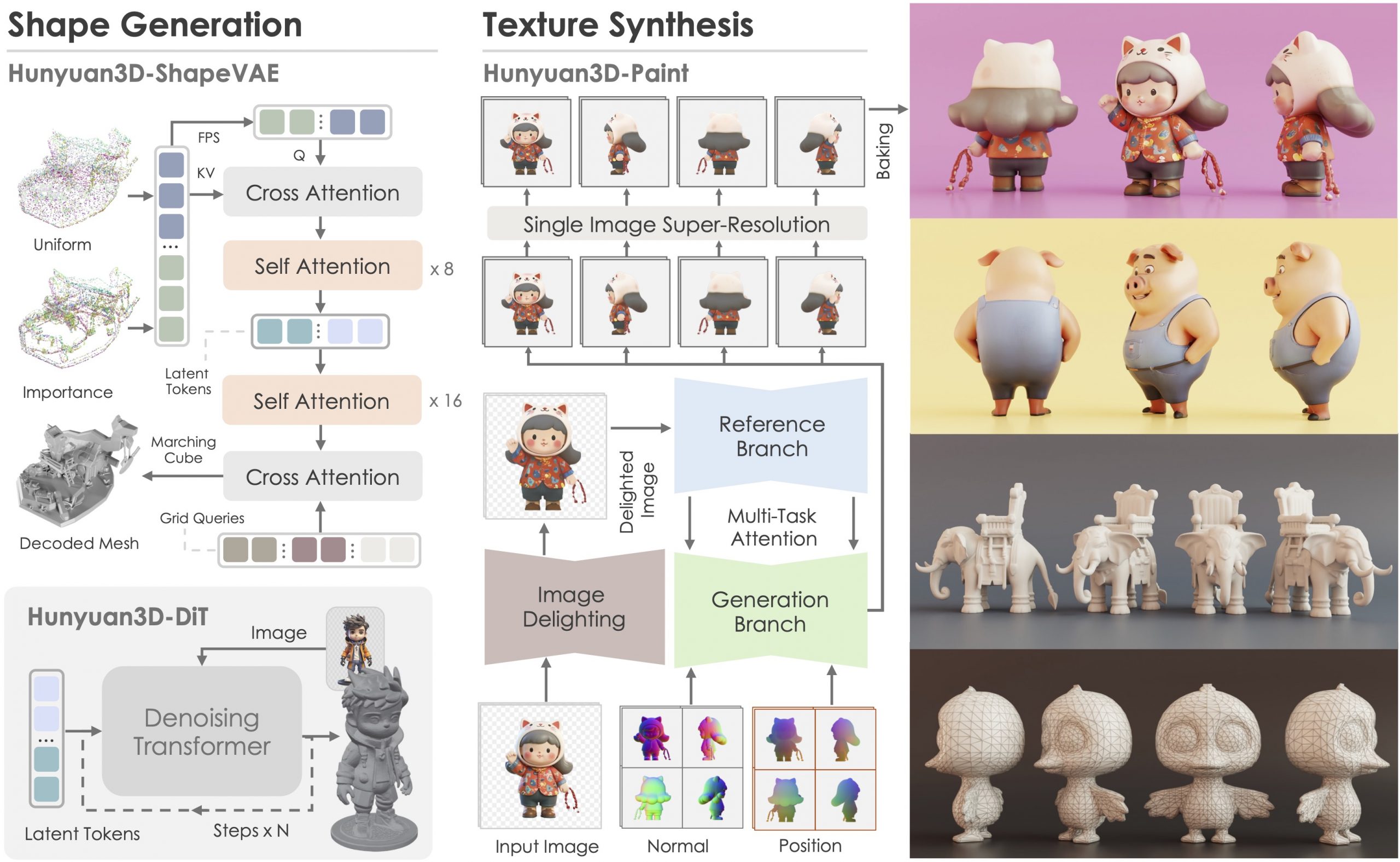
Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model – Hunyuan3D-DiT, and a large-scale texture synthesis model – Hunyuan3D-Paint.
The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio – a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets.
It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and e.t.c.
DISCLAIMER– Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.