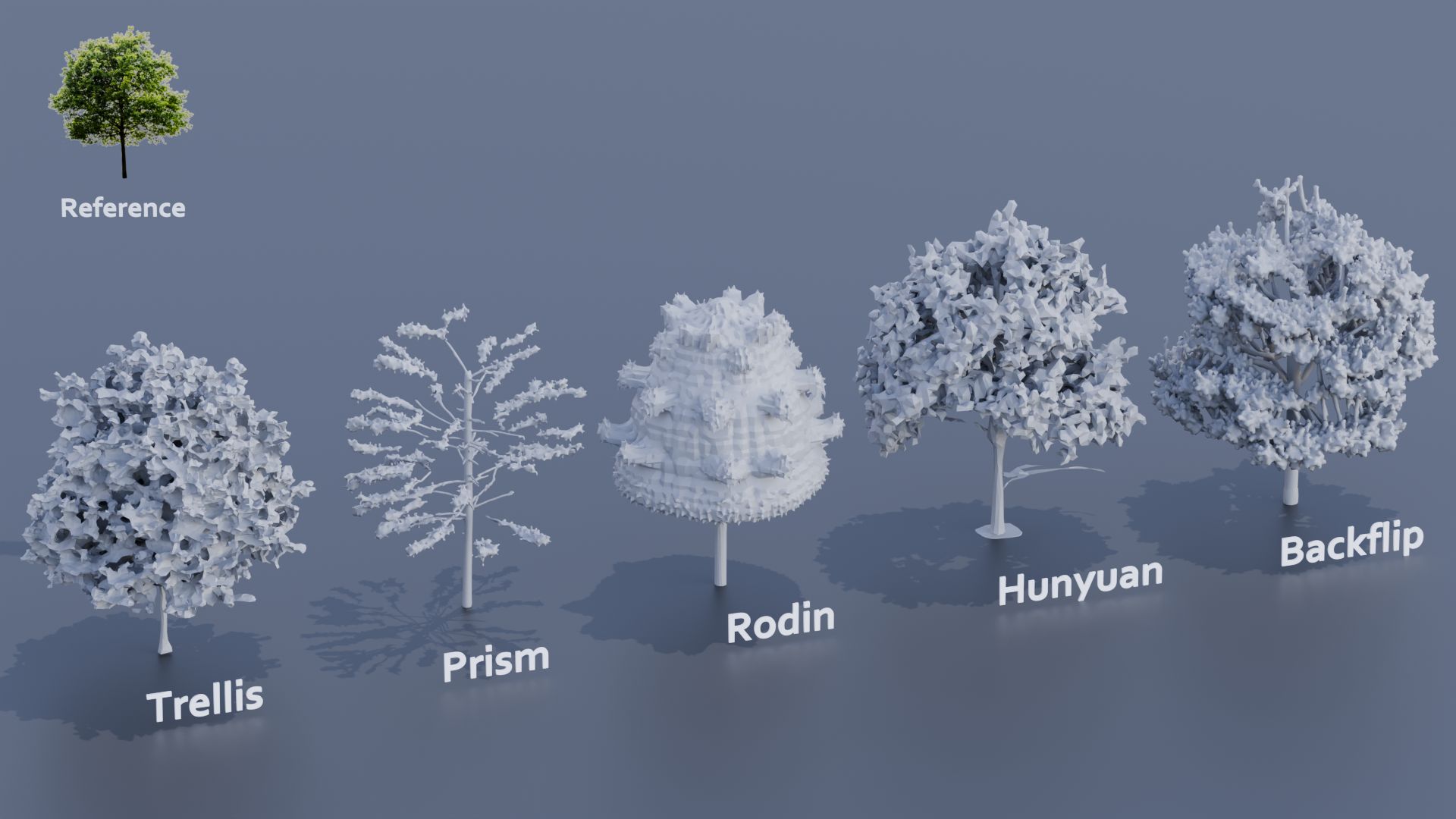
Unlike other models like Sora, Pika2, Veo2, HunyuanVideo’s neural network weights are uncensored and openly distributed, which means they can be run locally under the right circumstances (for example on a consumer 24 GB VRAM GPU) and it can be fine-tuned or used with LoRAs to teach it new concepts.
FLUX (or FLUX. 1) is a suite of text-to-image models from Black Forest Labs, a new company set up by some of the AI researchers behind innovations and models like VQGAN, Stable Diffusion, Latent Diffusion, and Adversarial Diffusion Distillation
— Stelfie the Time Traveller (@StelfieTT) July 7, 2024
With LivePortrait you can just perform what you want the character on the screen to do. This clip is using cc0 footage from Pexels, but you can do this with all the AnimateDiff / Gen3 / Luma / Pika etc clips you've already made as well! pic.twitter.com/y2fLoC5183
An open-source Mixture-of-Experts (MoE) code language model that achieves performance comparable to GPT4-Turbo in code-specific tasks. Specifically, DeepSeek-Coder-V2 is further pre-trained from an intermediate checkpoint of DeepSeek-V2 with additional 6 trillion tokens. Through this continued pre-training, DeepSeek-Coder-V2 substantially enhances the coding and mathematical reasoning capabilities of DeepSeek-V2, while maintaining comparable performance in general language tasks. Compared to DeepSeek-Coder-33B, DeepSeek-Coder-V2 demonstrates significant advancements in various aspects of code-related tasks, as well as reasoning and general capabilities. Additionally, DeepSeek-Coder-V2 expands its support for programming languages from 86 to 338, while extending the context length from 16K to 128K.
3. Generative AI Fundamentals: Earn a skill badge by demonstrating your understanding of foundational concepts in Generative AI. https://www.cloudskillsboost.google/paths
7. Transformer Models and BERT Model: Get a comprehensive introduction to the Transformer architecture and the Bidirectional Encoder Representations from the Transformers (BERT) model. https://www.cloudskillsboost.google/course_templates/538
2- tune the caption with ChatGPT as suggested by Pixaroma: Craft detailed prompts for Al (image/video) generation, avoiding quotation marks. When I provide a description or image, translate it into a prompt that captures a cinematic, movie-like quality, focusing on elements like scene, style, mood, lighting, and specific visual details. Ensure that the prompt evokes a rich, immersive atmosphere, emphasizing textures, depth, and realism. Always incorporate (static/slow) camera or cinematic movement to enhance the feeling of fluidity and visual storytelling. Keep the wording precise yet descriptive, directly usable, and designed to achieve a high-quality, film-inspired result.
1. Use the 80/20 principle to learn faster Prompt: “I want to learn about [insert topic]. Identify and share the most important 20% of learnings from this topic that will help me understand 80% of it.”
2. Learn and develop any new skill Prompt: “I want to learn/get better at [insert desired skill]. I am a complete beginner. Create a 30-day learning plan that will help a beginner like me learn and improve this skill.”
3. Summarize long documents and articles Prompt: “Summarize the text below and give me a list of bullet points with key insights and the most important facts.” [Insert text]
4. Train ChatGPT to generate prompts for you Prompt: “You are an AI designed to help [insert profession]. Generate a list of the 10 best prompts for yourself. The prompts should be about [insert topic].”
5. Master any new skill Prompt: “I have 3 free days a week and 2 months. Design a crash study plan to master [insert desired skill].”
6. Simplify complex information Prompt: “Break down [insert topic] into smaller, easier-to-understand parts. Use analogies and real-life examples to simplify the concept and make it more relatable.”
“Simon Willison created a Datasette browser to explore WebVid-10M, one of the two datasets used to train the video generation model, and quickly learned that all 10.7 million video clips were scraped from Shutterstock, watermarks and all.”
“In addition to the Shutterstock clips, Meta also used 10 million video clips from this 100M video dataset from Microsoft Research Asia. It’s not mentioned on their GitHub, but if you dig into the paper, you learn that every clip came from over 3 million YouTube videos.”
“It’s become standard practice for technology companies working with AI to commercially use datasets and models collected and trained by non-commercial research entities like universities or non-profits.”
“Like with the artists, photographers, and other creators found in the 2.3 billion images that trained Stable Diffusion, I can’t help but wonder how the creators of those 3 million YouTube videos feel about Meta using their work to train their new model.”
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.