


COMPOSITION
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

-
7 Commandments of Film Editing and composition
Read more: 7 Commandments of Film Editing and composition
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.















DESIGN
-
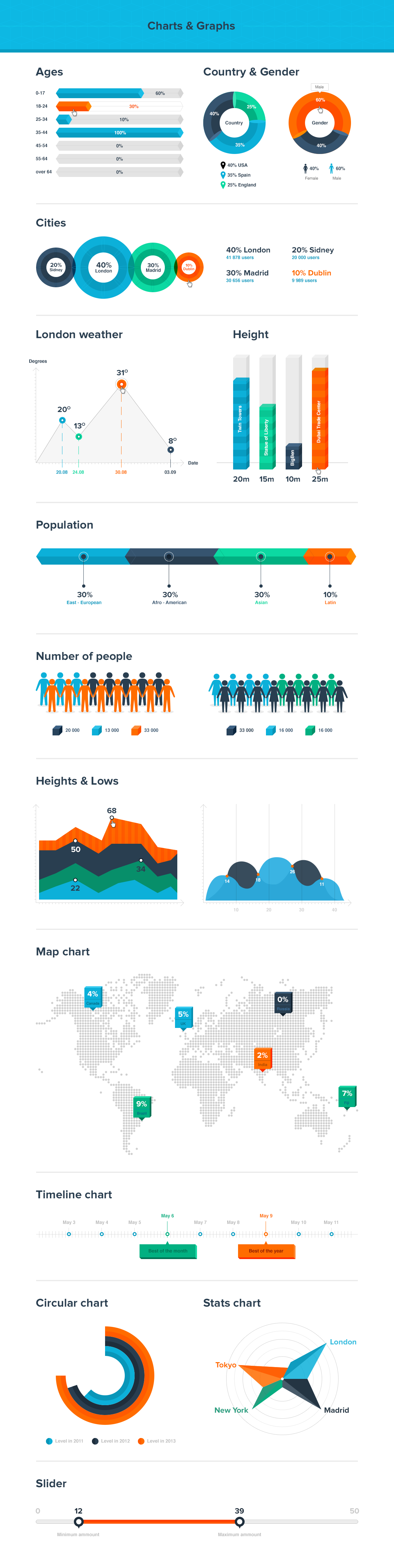
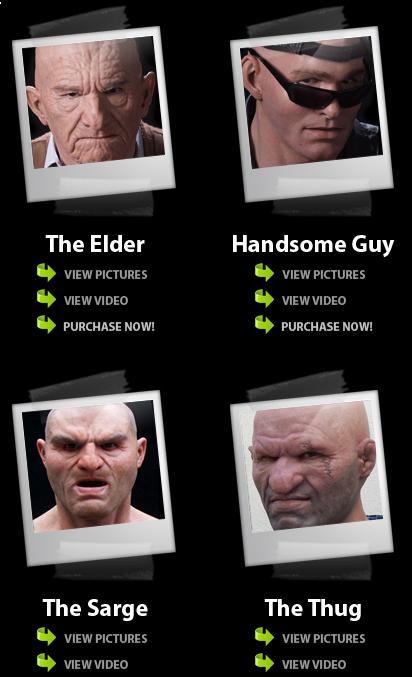
The Hybrids by Phil Langer – hyper-realistic AI-generated human animal portraits
Read more: The Hybrids by Phil Langer – hyper-realistic AI-generated human animal portraitshttps://www.reddit.com/r/aiArt/comments/1azepd6/hybrid_portraits_by_phil_langer/
https://www.thehybridportraits.com/
https://www.instagram.com/hybridportraits/













COLOR
-
Björn Ottosson – How software gets color wrong
Read more: Björn Ottosson – How software gets color wronghttps://bottosson.github.io/posts/colorwrong/
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:
- Perceptual blend – A smooth transition using a model designed to mimic human perception of color. The blending is done so that the perceived brightness and color varies smoothly and evenly.
- Linear blend – A model for blending color based on how light behaves physically. This type of blending can occur in many ways naturally, for example when colors are blended together by focus blur in a camera or when viewing a pattern of two colors at a distance.
- sRGB blend – This is how colors would normally be blended in computer software, using sRGB to represent the colors.

Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.

Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Also see:
-
Image rendering bit depth
Read more: Image rendering bit depthThe terms 8-bit, 16-bit, 16-bit float, and 32-bit refer to different data formats used to store and represent image information, as bits per pixel.
https://en.wikipedia.org/wiki/Color_depth
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.

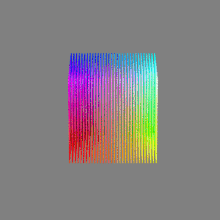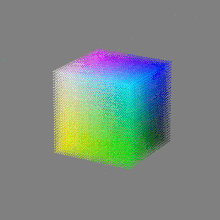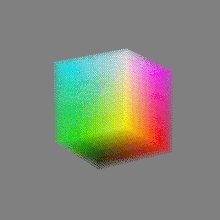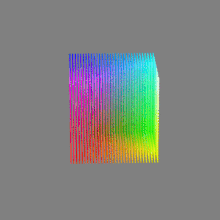
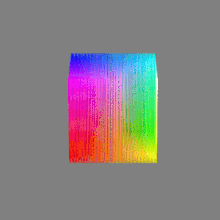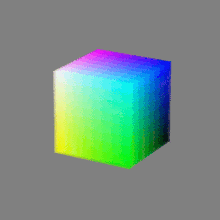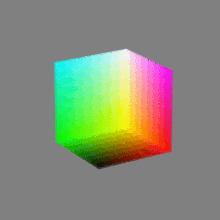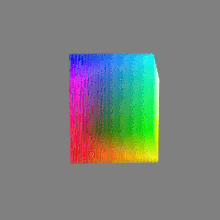
Here’s a simple explanation of each.
8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.16-bit: This format is commonly referred to as “half-precision.” It uses 16 bits of data to represent color values for each pixel. With 16 bits, you can have 65,536 discrete levels of color, allowing for relatively high precision and smooth gradients. However, it has a limited dynamic range, meaning it cannot accurately represent extremely bright or dark values. It is commonly used for regular images and textures.
16-bit float: This format is an extension of the 16-bit format but uses floating-point numbers instead of fixed integers. Floating-point numbers allow for more precise calculations and a larger dynamic range. In this case, the 16 bits are used to store both the color value and the exponent, which controls the range of values that can be represented. The 16-bit float format provides better accuracy and a wider dynamic range than regular 16-bit, making it useful for high-dynamic-range imaging (HDRI) and computations that require more precision.
32-bit: (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range. This format, also known as “full-precision” or “float,” uses 32 bits to represent color values and offers the highest precision and dynamic range among the three options. With 32 bits, you have a significantly larger number of discrete levels, allowing for extremely accurate color representation, smooth gradients, and a wide range of brightness values. It is commonly used for professional rendering, visual effects, and scientific applications where maximum precision is required.
Bits and HDR coverage
High Dynamic Range (HDR) images are designed to capture a wide range of luminance values, from the darkest shadows to the brightest highlights, in order to reproduce a scene with more accuracy and detail. The bit depth of an image refers to the number of bits used to represent each pixel’s color information. When comparing 32-bit float and 16-bit float HDR images, the drop in accuracy primarily relates to the precision of the color information.
A 32-bit float HDR image offers a higher level of precision compared to a 16-bit float HDR image. In a 32-bit float format, each color channel (red, green, and blue) is represented by 32 bits, allowing for a larger range of values to be stored. This increased precision enables the image to retain more details and subtleties in color and luminance.
On the other hand, a 16-bit float HDR image utilizes 16 bits per color channel, resulting in a reduced range of values that can be represented. This lower precision leads to a loss of fine details and color nuances, especially in highly contrasted areas of the image where there are significant differences in luminance.
The drop in accuracy between 32-bit and 16-bit float HDR images becomes more noticeable as the exposure range of the scene increases. Exposure range refers to the span between the darkest and brightest areas of an image. In scenes with a limited exposure range, where the luminance differences are relatively small, the loss of accuracy may not be as prominent or perceptible. These images usually are around 8-10 exposure levels.
However, in scenes with a wide exposure range, such as a landscape with deep shadows and bright highlights, the reduced precision of a 16-bit float HDR image can result in visible artifacts like color banding, posterization, and loss of detail in both shadows and highlights. The image may exhibit abrupt transitions between tones or colors, which can appear unnatural and less realistic.
To provide a rough estimate, it is often observed that exposure values beyond approximately ±6 to ±8 stops from the middle gray (18% reflectance) may be more prone to accuracy issues in a 16-bit float format. This range may vary depending on the specific implementation and encoding scheme used.
To summarize, the drop in accuracy between 32-bit and 16-bit float HDR images is mainly related to the reduced precision of color information. This decrease in precision becomes more apparent in scenes with a wide exposure range, affecting the representation of fine details and leading to visible artifacts in the image.
In practice, this means that exposure values beyond a certain range will experience a loss of accuracy and detail when stored in a 16-bit float format. The exact range at which this loss occurs depends on the encoding scheme and the specific implementation. However, in general, extremely bright or extremely dark values that fall outside the representable range may be subject to quantization errors, resulting in loss of detail, banding, or other artifacts.
HDRs used for lighting purposes are usually slightly convolved to improve on sampling speed and removing specular artefacts. To that extent, 16 bit float HDRIs tend to me most used in CG cycles.

-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…) -
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.












LIGHTING
-
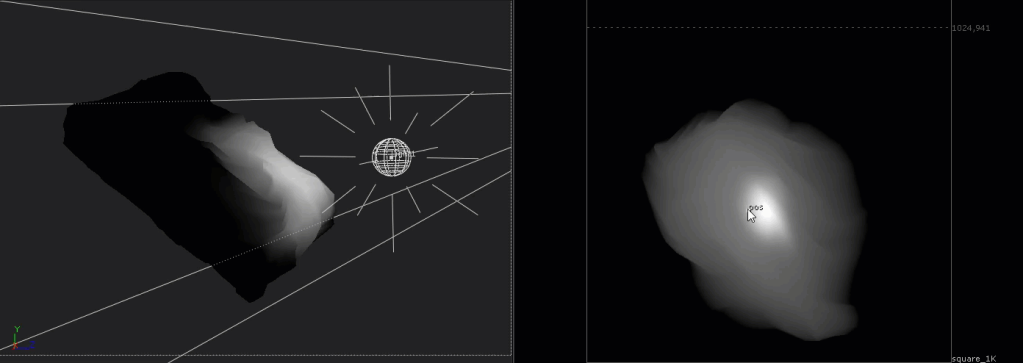
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
# bottom left coordinates = 0,0 import numpy as np import cv2 # Load the HDR or EXR image image = cv2.imread('your_image_path.exr', cv2.IMREAD_UNCHANGED) # Load as-is without modification # Calculate the luminance from the HDR channels (assuming RGB format) luminance = np.dot(image[..., :3], [0.299, 0.587, 0.114]) # Set a threshold value based on estimated EV threshold_value = 2.4 # Estimated threshold value based on 4.8 EV # Apply the threshold to identify bright areas # Theluminancearray contains the calculated luminance values for each pixel in the image. # Thethreshold_valueis a user-defined value that represents a cutoff point, separating "bright" and "dark" areas in terms of perceived luminance.thresholded = (luminance > threshold_value) * 255 # Convert the thresholded image to uint8 for contour detection thresholded = thresholded.astype(np.uint8) # Find contours of the bright areas contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # Create a list to store the bounding boxes of bright areas bright_areas = [] # Iterate through contours and extract bounding boxes for contour in contours: x, y, w, h = cv2.boundingRect(contour) # Adjust y-coordinate based on bottom-left origin y_bottom_left_origin = image.shape[0] - (y + h) bright_areas.append((x, y_bottom_left_origin, x + w, y_bottom_left_origin + h)) # Store as (x1, y1, x2, y2) # Print the identified bright areas print("Bright Areas (x1, y1, x2, y2):") for area in bright_areas: print(area)More details
Luminance and Exposure in an EXR Image:
- An EXR (Extended Dynamic Range) image format is often used to store high dynamic range (HDR) images that contain a wide range of luminance values, capturing both dark and bright areas.
- Luminance refers to the perceived brightness of a pixel in an image. In an RGB image, luminance is often calculated using a weighted sum of the red, green, and blue channels, where different weights are assigned to each channel to account for human perception.
- In an EXR image, the pixel values can represent radiometrically accurate scene values, including actual radiance or irradiance levels. These values are directly related to the amount of light emitted or reflected by objects in the scene.
The luminance line is calculating the luminance of each pixel in the image using a weighted sum of the red, green, and blue channels. The three float values [0.299, 0.587, 0.114] are the weights used to perform this calculation.
These weights are based on the concept of luminosity, which aims to approximate the perceived brightness of a color by taking into account the human eye’s sensitivity to different colors. The values are often derived from the NTSC (National Television System Committee) standard, which is used in various color image processing operations.
Here’s the breakdown of the float values:
- 0.299: Weight for the red channel.
- 0.587: Weight for the green channel.
- 0.114: Weight for the blue channel.
The weighted sum of these channels helps create a grayscale image where the pixel values represent the perceived brightness. This technique is often used when converting a color image to grayscale or when calculating luminance for certain operations, as it takes into account the human eye’s sensitivity to different colors.
For the threshold, remember that the exact relationship between EV values and pixel values can depend on the tone-mapping or normalization applied to the HDR image, as well as the dynamic range of the image itself.
To establish a relationship between exposure and the threshold value, you can consider the relationship between linear and logarithmic scales:
- Linear and Logarithmic Scales:
- Exposure values in an EXR image are often represented in logarithmic scales, such as EV (exposure value). Each increment in EV represents a doubling or halving of the amount of light captured.
- Threshold values for luminance thresholding are usually linear, representing an actual luminance level.
- Conversion Between Scales:
- To establish a mathematical relationship, you need to convert between the logarithmic exposure scale and the linear threshold scale.
- One common method is to use a power function. For instance, you can use a power function to convert EV to a linear intensity value.
threshold_value = base_value * (2 ** EV)Here,
EVis the exposure value,base_valueis a scaling factor that determines the relationship between EV and threshold_value, and2 ** EVis used to convert the logarithmic EV to a linear intensity value. - Choosing the Base Value:
- The
base_valuefactor should be determined based on the dynamic range of your EXR image and the specific luminance values you are dealing with. - You may need to experiment with different values of
base_valueto achieve the desired separation of bright areas from the rest of the image.
- The
Let’s say you have an EXR image with a dynamic range of 12 EV, which is a common range for many high dynamic range images. In this case, you want to set a threshold value that corresponds to a certain number of EV above the middle gray level (which is often considered to be around 0.18).
Here’s an example of how you might determine a
base_valueto achieve this:# Define the dynamic range of the image in EV dynamic_range = 12 # Choose the desired number of EV above middle gray for thresholding desired_ev_above_middle_gray = 2 # Calculate the threshold value based on the desired EV above middle gray threshold_value = 0.18 * (2 ** (desired_ev_above_middle_gray / dynamic_range)) print("Threshold Value:", threshold_value) -
IES Light Profiles and editing software
Read more: IES Light Profiles and editing softwarehttp://www.derekjenson.com/3d-blog/ies-light-profiles
https://ieslibrary.com/en/browse#ies
https://leomoon.com/store/shaders/ies-lights-pack
https://docs.arnoldrenderer.com/display/a5afmug/ai+photometric+light
IES profiles are useful for creating life-like lighting, as they can represent the physical distribution of light from any light source.
The IES format was created by the Illumination Engineering Society, and most lighting manufacturers provide IES profile for the lights they manufacture.


















{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Free fonts
-
How to paint a boardgame miniatures
-
Alejandro Villabón and Rafał Kaniewski – Recover Highlights With 8-Bit to High Dynamic Range Half Float Copycat – Nuke
-
Mastering The Art Of Photography – PixelSham.com Photography Basics
-
The Perils of Technical Debt – Understanding Its Impact on Security, Usability, and Stability
-
Matt Gray – How to generate a profitable business
-
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
