


COMPOSITION
-
Mastering Camera Shots and Angles: A Guide for Filmmakers
Read more: Mastering Camera Shots and Angles: A Guide for Filmmakershttps://website.ltx.studio/blog/mastering-camera-shots-and-angles
1. Extreme Wide Shot

2. Wide Shot

3. Medium Shot

4. Close Up

5. Extreme Close Up

-
7 Commandments of Film Editing and composition
Read more: 7 Commandments of Film Editing and composition
1. Watch every frame of raw footage twice. On the second time, take notes. If you don’t do this and try to start developing a scene premature, then it’s a big disservice to yourself and to the director, actors and production crew.
2. Nurture the relationships with the director. You are the secondary person in the relationship. Be calm and continually offer solutions. Get the main intention of the film as soon as possible from the director.
3. Organize your media so that you can find any shot instantly.
4. Factor in extra time for renders, exports, errors and crashes.
5. Attempt edits and ideas that shouldn’t work. It just might work. Until you do it and watch it, you won’t know. Don’t rule out ideas just because they don’t make sense in your mind.
6. Spend more time on your audio. It’s the glue of your edit. AUDIO SAVES EVERYTHING. Create fluid and seamless audio under your video.
7. Make cuts for the scene, but always in context for the whole film. Have a macro and a micro view at all times.
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.

-
Key/Fill ratios and scene composition using false colors
Read more: Key/Fill ratios and scene composition using false colors
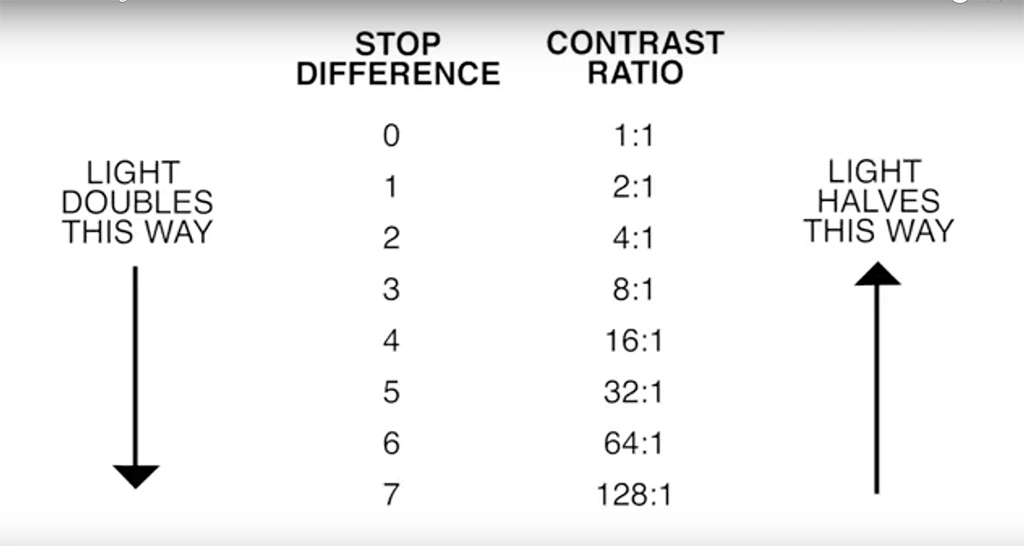
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
Let’s say you grabbed a measurement from your key light of f/8.0. Then, when you measured your fill light area, you get a reading of f/4.0. This will lead you to a contrast ratio of 4:1 because there are two stops between f/4.0 and f/8.0 and each stop doubles the amount of light. In other words, two stops x twice the light per stop = four times as much light at f/8.0 than at f/4.0.

theslantedlens.com/2017/lighting-ratios-photo-video/
Examples in the post

















DESIGN
-
The 7 key elements of brand identity design + 10 corporate identity examples
Read more: The 7 key elements of brand identity design + 10 corporate identity exampleswww.lucidpress.com/blog/the-7-key-elements-of-brand-identity-design
1. Clear brand purpose and positioning
2. Thorough market research
3. Likable brand personality
4. Memorable logo
5. Attractive color palette
6. Professional typography
7. On-brand supporting graphics













COLOR
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
Akiyoshi Kitaoka – Surround biased illumination perception
Read more: Akiyoshi Kitaoka – Surround biased illumination perceptionhttps://x.com/AkiyoshiKitaoka/status/1798705648001327209
The left face appears whitish and the right one blackish, but they are made up of the same luminance.

https://community.wolfram.com/groups/-/m/t/3191015
Illusory staircase Gelb effect
https://www.psy.ritsumei.ac.jp/akitaoka/illgelbe.html
-
Björn Ottosson – OKlch color space
Read more: Björn Ottosson – OKlch color spaceBjörn Ottosson proposed OKlch in 2020 to create a color space that can closely mimic how color is perceived by the human eye, predicting perceived lightness, chroma, and hue.
The OK in OKLCH stands for Optimal Color.
- L: Lightness (the perceived brightness of the color)
- C: Chroma (the intensity or saturation of the color)
- H: Hue (the actual color, such as red, blue, green, etc.)

Also read:
-
3D Lighting Tutorial by Amaan Kram
Read more: 3D Lighting Tutorial by Amaan Kramhttp://www.amaanakram.com/lightingT/part1.htm
The goals of lighting in 3D computer graphics are more or less the same as those of real world lighting.
Lighting serves a basic function of bringing out, or pushing back the shapes of objects visible from the camera’s view.
It gives a two-dimensional image on the monitor an illusion of the third dimension-depth.But it does not just stop there. It gives an image its personality, its character. A scene lit in different ways can give a feeling of happiness, of sorrow, of fear etc., and it can do so in dramatic or subtle ways. Along with personality and character, lighting fills a scene with emotion that is directly transmitted to the viewer.
Trying to simulate a real environment in an artificial one can be a daunting task. But even if you make your 3D rendering look absolutely photo-realistic, it doesn’t guarantee that the image carries enough emotion to elicit a “wow” from the people viewing it.
Making 3D renderings photo-realistic can be hard. Putting deep emotions in them can be even harder. However, if you plan out your lighting strategy for the mood and emotion that you want your rendering to express, you make the process easier for yourself.
Each light source can be broken down in to 4 distinct components and analyzed accordingly.
· Intensity
· Direction
· Color
· SizeThe overall thrust of this writing is to produce photo-realistic images by applying good lighting techniques.

-
Tobia Montanari – Memory Colors: an essential tool for Colorists
Read more: Tobia Montanari – Memory Colors: an essential tool for Coloristshttps://www.tobiamontanari.com/memory-colors-an-essential-tool-for-colorists/
“Memory colors are colors that are universally associated with specific objects, elements or scenes in our environment. They are the colors that we expect to see in specific situations: these colors are based on our expectation of how certain objects should look based on our past experiences and memories.
For instance, we associate specific hues, saturation and brightness values with human skintones and a slight variation can significantly affect the way we perceive a scene.
Similarly, we expect blue skies to have a particular hue, green trees to be a specific shade and so on.
Memory colors live inside of our brains and we often impose them onto what we see. By considering them during the grading process, the resulting image will be more visually appealing and won’t distract the viewer from the intended message of the story. Even a slight deviation from memory colors in a movie can create a sense of discordance, ultimately detracting from the viewer’s experience.”
-
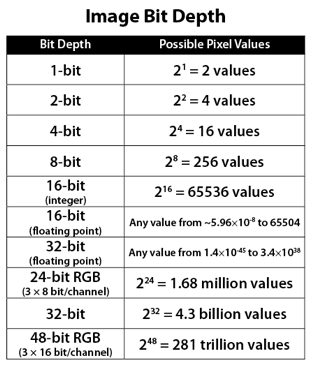
Image rendering bit depth
Read more: Image rendering bit depthThe terms 8-bit, 16-bit, 16-bit float, and 32-bit refer to different data formats used to store and represent image information, as bits per pixel.
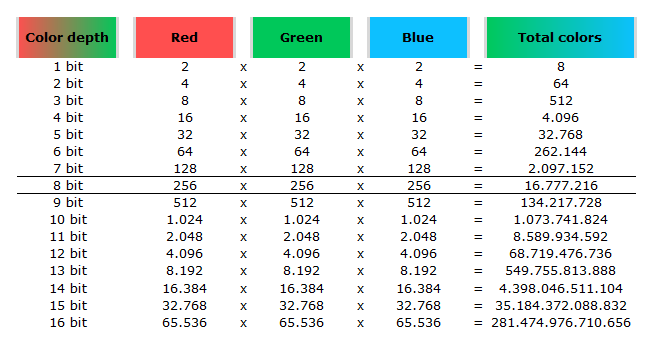
https://en.wikipedia.org/wiki/Color_depth
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.

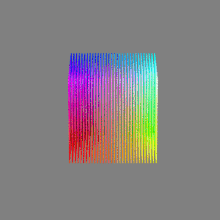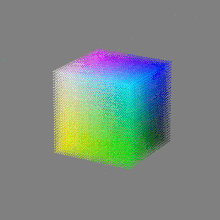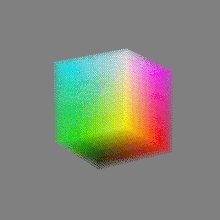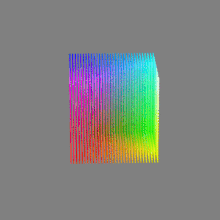
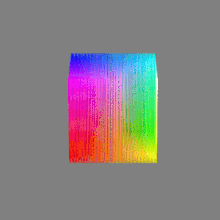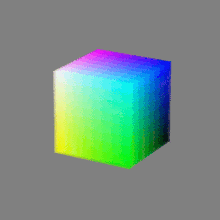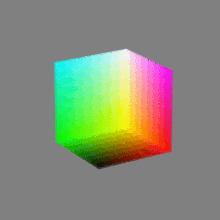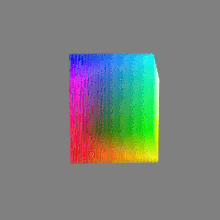
Here’s a simple explanation of each.
8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.16-bit: This format is commonly referred to as “half-precision.” It uses 16 bits of data to represent color values for each pixel. With 16 bits, you can have 65,536 discrete levels of color, allowing for relatively high precision and smooth gradients. However, it has a limited dynamic range, meaning it cannot accurately represent extremely bright or dark values. It is commonly used for regular images and textures.
16-bit float: This format is an extension of the 16-bit format but uses floating-point numbers instead of fixed integers. Floating-point numbers allow for more precise calculations and a larger dynamic range. In this case, the 16 bits are used to store both the color value and the exponent, which controls the range of values that can be represented. The 16-bit float format provides better accuracy and a wider dynamic range than regular 16-bit, making it useful for high-dynamic-range imaging (HDRI) and computations that require more precision.
32-bit: (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range. This format, also known as “full-precision” or “float,” uses 32 bits to represent color values and offers the highest precision and dynamic range among the three options. With 32 bits, you have a significantly larger number of discrete levels, allowing for extremely accurate color representation, smooth gradients, and a wide range of brightness values. It is commonly used for professional rendering, visual effects, and scientific applications where maximum precision is required.
Bits and HDR coverage
High Dynamic Range (HDR) images are designed to capture a wide range of luminance values, from the darkest shadows to the brightest highlights, in order to reproduce a scene with more accuracy and detail. The bit depth of an image refers to the number of bits used to represent each pixel’s color information. When comparing 32-bit float and 16-bit float HDR images, the drop in accuracy primarily relates to the precision of the color information.
A 32-bit float HDR image offers a higher level of precision compared to a 16-bit float HDR image. In a 32-bit float format, each color channel (red, green, and blue) is represented by 32 bits, allowing for a larger range of values to be stored. This increased precision enables the image to retain more details and subtleties in color and luminance.
On the other hand, a 16-bit float HDR image utilizes 16 bits per color channel, resulting in a reduced range of values that can be represented. This lower precision leads to a loss of fine details and color nuances, especially in highly contrasted areas of the image where there are significant differences in luminance.
The drop in accuracy between 32-bit and 16-bit float HDR images becomes more noticeable as the exposure range of the scene increases. Exposure range refers to the span between the darkest and brightest areas of an image. In scenes with a limited exposure range, where the luminance differences are relatively small, the loss of accuracy may not be as prominent or perceptible. These images usually are around 8-10 exposure levels.
However, in scenes with a wide exposure range, such as a landscape with deep shadows and bright highlights, the reduced precision of a 16-bit float HDR image can result in visible artifacts like color banding, posterization, and loss of detail in both shadows and highlights. The image may exhibit abrupt transitions between tones or colors, which can appear unnatural and less realistic.
To provide a rough estimate, it is often observed that exposure values beyond approximately ±6 to ±8 stops from the middle gray (18% reflectance) may be more prone to accuracy issues in a 16-bit float format. This range may vary depending on the specific implementation and encoding scheme used.
To summarize, the drop in accuracy between 32-bit and 16-bit float HDR images is mainly related to the reduced precision of color information. This decrease in precision becomes more apparent in scenes with a wide exposure range, affecting the representation of fine details and leading to visible artifacts in the image.
In practice, this means that exposure values beyond a certain range will experience a loss of accuracy and detail when stored in a 16-bit float format. The exact range at which this loss occurs depends on the encoding scheme and the specific implementation. However, in general, extremely bright or extremely dark values that fall outside the representable range may be subject to quantization errors, resulting in loss of detail, banding, or other artifacts.
HDRs used for lighting purposes are usually slightly convolved to improve on sampling speed and removing specular artefacts. To that extent, 16 bit float HDRIs tend to me most used in CG cycles.

-
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.



-
Is it possible to get a dark yellow
Read more: Is it possible to get a dark yellowhttps://www.patreon.com/posts/102660674
https://www.linkedin.com/posts/stephenwestland_here-is-a-post-about-the-dark-yellow-problem-activity-7187131643764092929-7uCL









LIGHTING
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
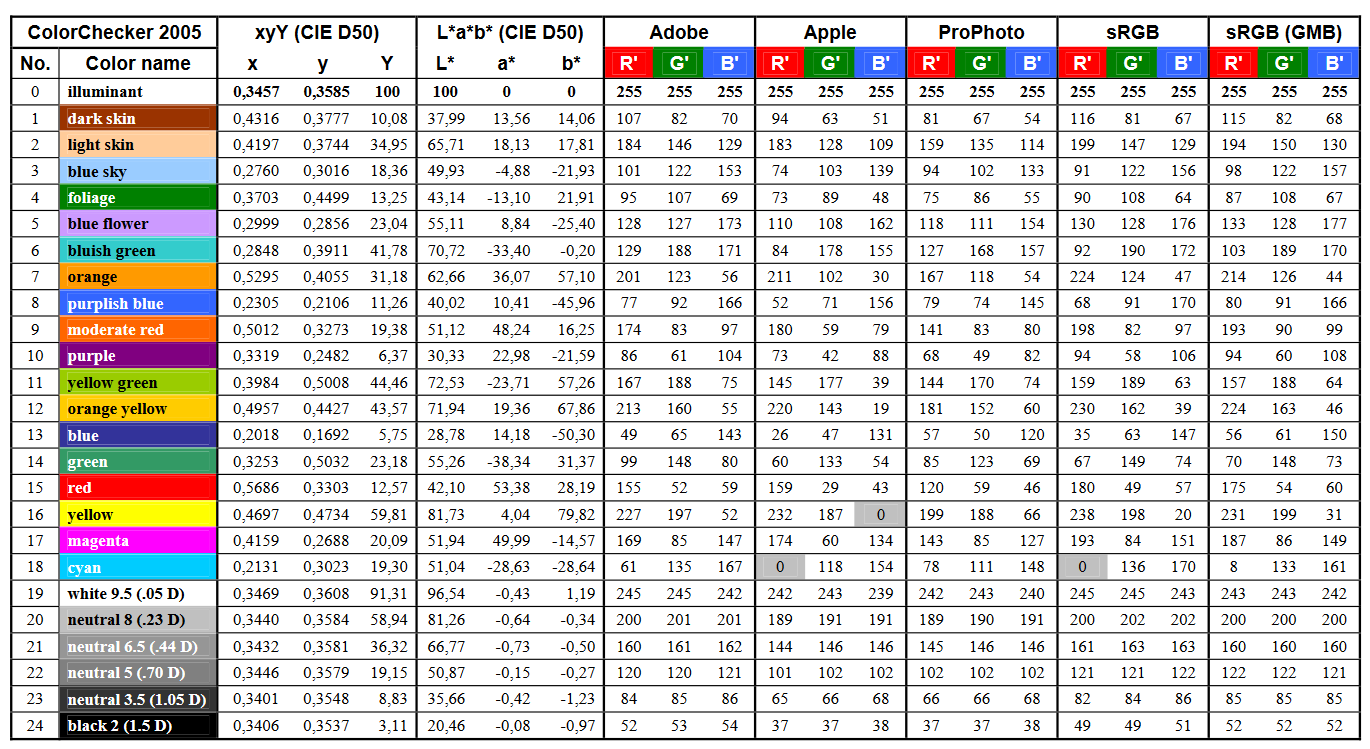
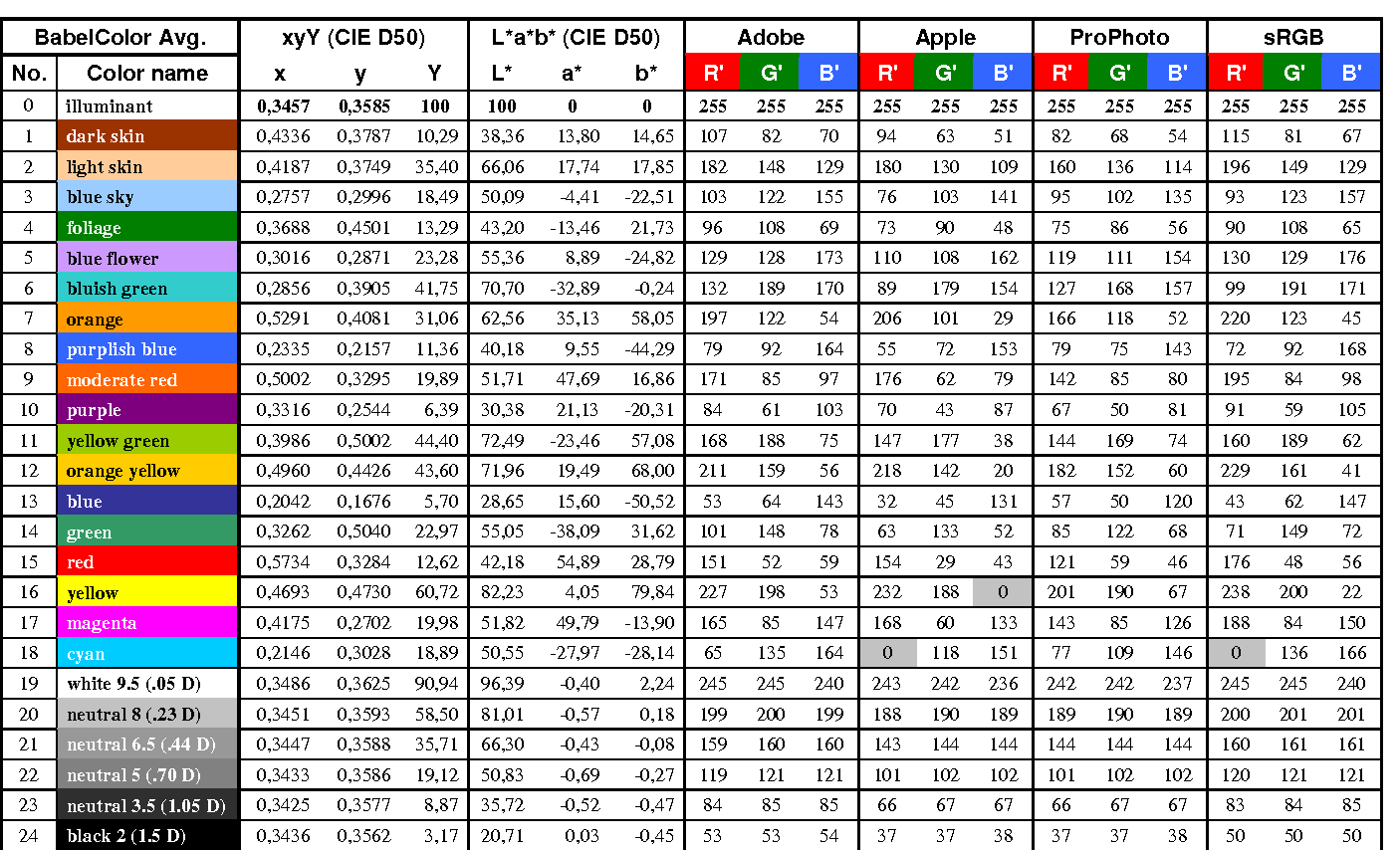
GretagMacbeth Color Checker Numeric Values and Middle Gray
Read more: GretagMacbeth Color Checker Numeric Values and Middle GrayThe human eye perceives half scene brightness not as the linear 50% of the present energy (linear nature values) but as 18% of the overall brightness. We are biased to perceive more information in the dark and contrast areas. A Macbeth chart helps with calibrating back into a photographic capture into this “human perspective” of the world.
https://en.wikipedia.org/wiki/Middle_gray
In photography, painting, and other visual arts, middle gray or middle grey is a tone that is perceptually about halfway between black and white on a lightness scale in photography and printing, it is typically defined as 18% reflectance in visible light
Light meters, cameras, and pictures are often calibrated using an 18% gray card[4][5][6] or a color reference card such as a ColorChecker. On the assumption that 18% is similar to the average reflectance of a scene, a grey card can be used to estimate the required exposure of the film.
https://en.wikipedia.org/wiki/ColorChecker

The exposure meter in the camera does not know whether the subject itself is bright or not. It simply measures the amount of light that comes in, and makes a guess based on that. The camera will aim for 18% gray independently, meaning if you take a photo of an entirely white surface, and an entirely black surface you should get two identical images which both are gray (at least in theory). Thus enters the Macbeth chart.

<!–more–>
Note that Chroma Key Green is reasonably close to an 18% gray reflectance.
http://www.rags-int-inc.com/PhotoTechStuff/MacbethTarget/

No Camera Data 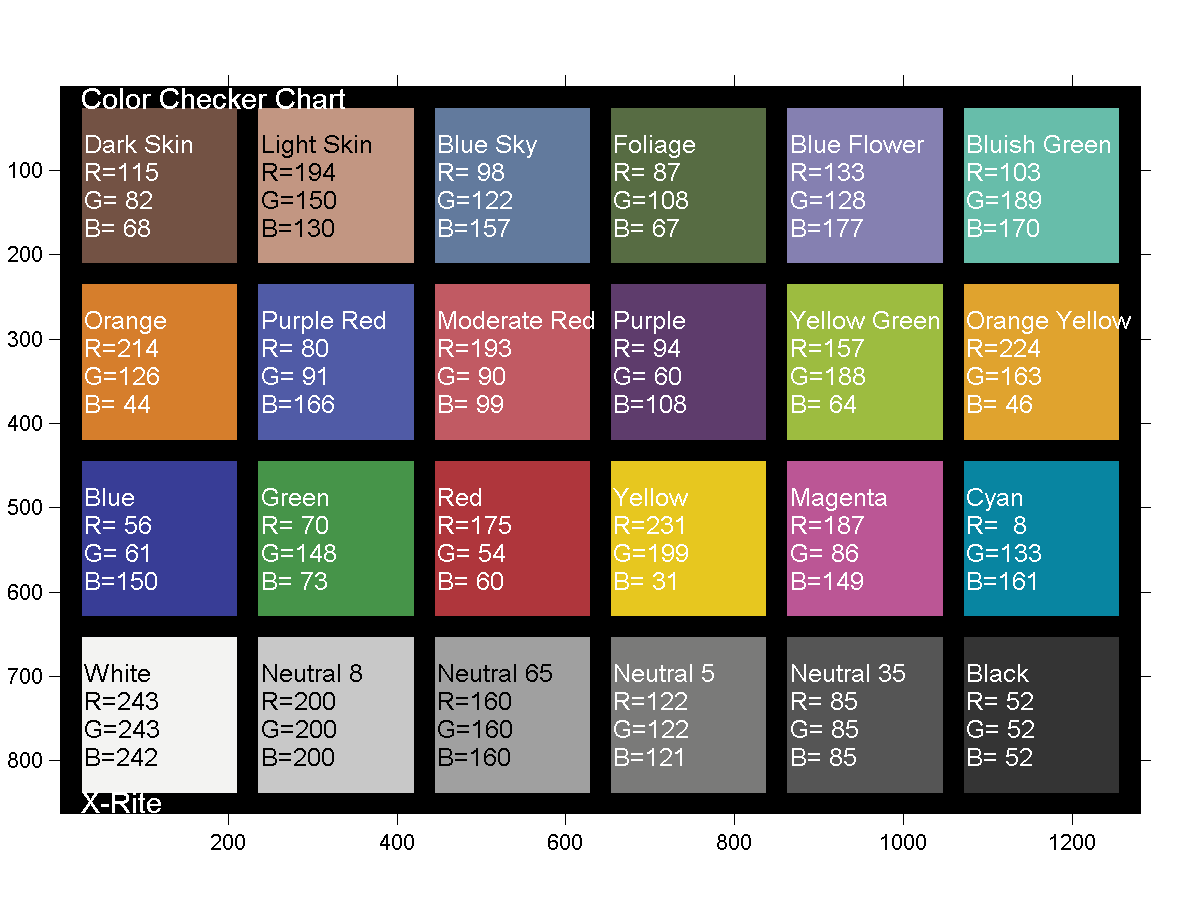
https://upload.wikimedia.org/wikipedia/commons/b/b4/CIE1931xy_ColorChecker_SMIL.svg

RGB coordinates of the Macbeth ColorChecker
https://pdfs.semanticscholar.org/0e03/251ad1e6d3c3fb9cb0b1f9754351a959e065.pdf
-
StudioBinder.com – Photography basics: What is Dynamic Range in Photography
Read more: StudioBinder.com – Photography basics: What is Dynamic Range in Photographyhttps://www.studiobinder.com/blog/what-is-dynamic-range-photography/
https://www.hdrsoft.com/resources/dri.html#bit-depth

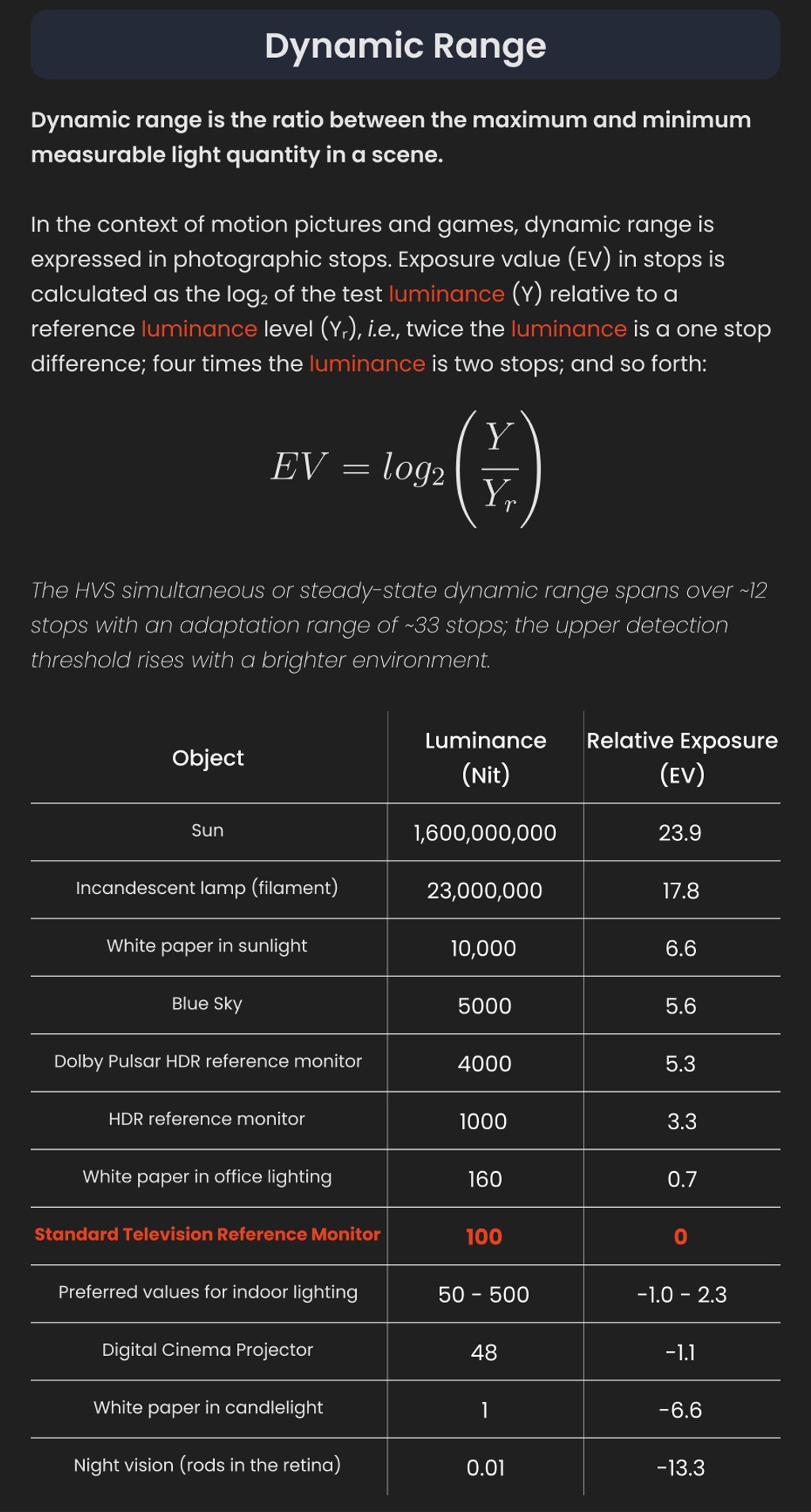
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.



-
Custom bokeh in a raytraced DOF render
Read more: Custom bokeh in a raytraced DOF render

To achieve a custom pinhole camera effect with a custom bokeh in Arnold Raytracer, you can follow these steps:
- Set the render camera with a focal length around 50 (or as needed)
- Set the F-Stop to a high value (e.g., 22).
- Set the focus distance as you require
- Turn on DOF
- Place a plane a few cm in front of the camera.
- Texture the plane with a transparent shape at the center of it. (Transmission with no specular roughness)










{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Generative AI Glossary / AI Dictionary / AI Terminology
-
Scene Referred vs Display Referred color workflows
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
-
Sensitivity of human eye
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
-
Photography basics: Color Temperature and White Balance
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Want to build a start up company that lasts? Think three-layer cake
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
