


COMPOSITION
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.

-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)















DESIGN















COLOR
-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
-
“Reality” is constructed by your brain. Here’s what that means, and why it matters.
Read more: “Reality” is constructed by your brain. Here’s what that means, and why it matters.“Fix your gaze on the black dot on the left side of this image. But wait! Finish reading this paragraph first. As you gaze at the left dot, try to answer this question: In what direction is the object on the right moving? Is it drifting diagonally, or is it moving up and down?”

What color are these strawberries?

Are A and B the same gray?

-
VES Cinematic Color – Motion-Picture Color Management
Read more: VES Cinematic Color – Motion-Picture Color ManagementThis paper presents an introduction to the color pipelines behind modern feature-film visual-effects and animation.
Authored by Jeremy Selan, and reviewed by the members of the VES Technology Committee including Rob Bredow, Dan Candela, Nick Cannon, Paul Debevec, Ray Feeney, Andy Hendrickson, Gautham Krishnamurti, Sam Richards, Jordan Soles, and Sebastian Sylwan.
-
Sensitivity of human eye
Read more: Sensitivity of human eyehttp://www.wikilectures.eu/index.php/Spectral_sensitivity_of_the_human_eye
http://www.normankoren.com/Human_spectral_sensitivity_small.jpg
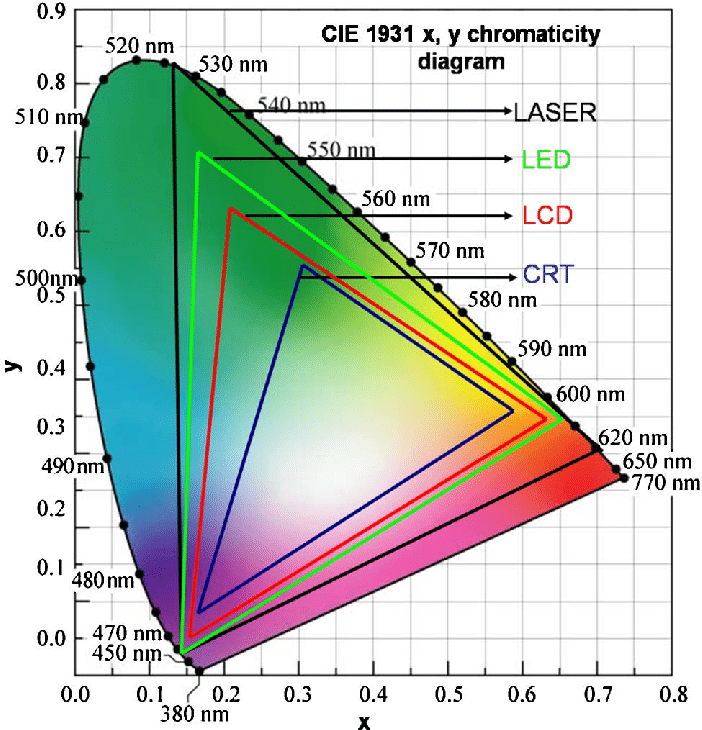
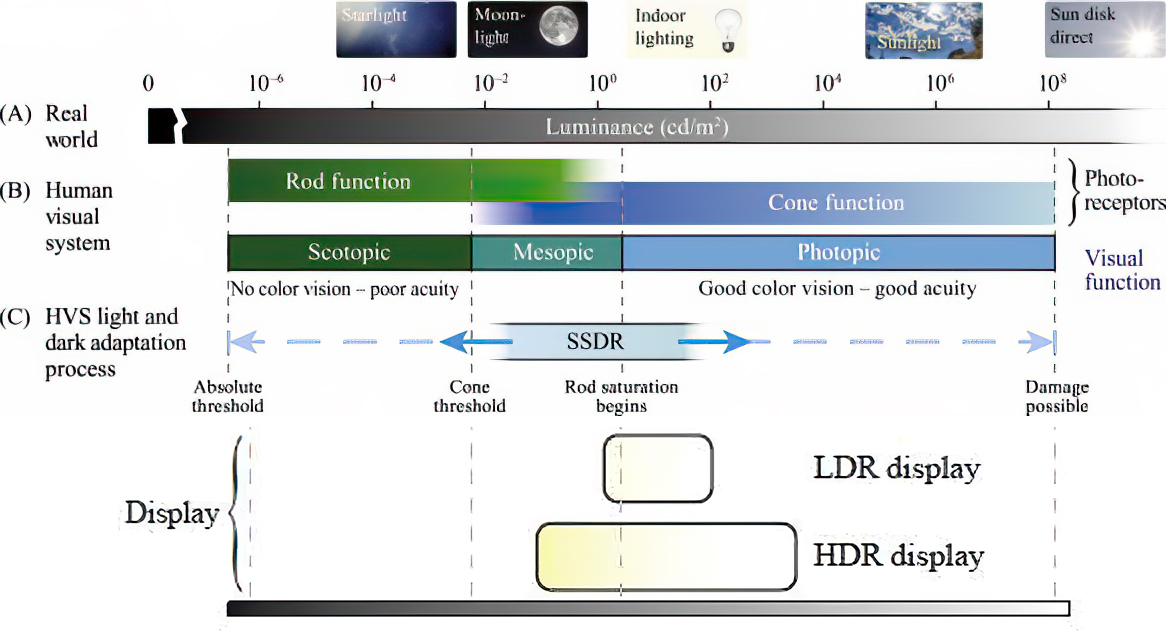
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
http://weeklysciencequiz.blogspot.com/2013/01/violet-skies-are-for-birds.html

Sensitivity of human eye Sensitivity of human eyes to light increase with the decrease in light intensity. In day-light condition, the cones cell is responding to this condition. And the eye is most sensitive at 555 nm. In darkness condition, the rod cell is responding to this condition. And the eye is most sensitive at 507 nm.
As light intensity decreases, cone function changes more effective way. And when decrease the light intensity, it prompt to accumulation of rhodopsin. Furthermore, in activates rods, it allow to respond to stimuli of light in much lower intensity.
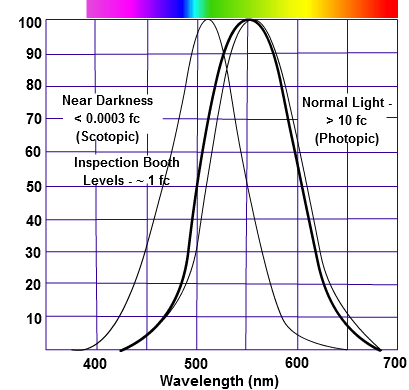
The three curves in the figure above shows the normalized response of an average human eye to various amounts of ambient light. The shift in sensitivity occurs because two types of photoreceptors called cones and rods are responsible for the eye’s response to light. The curve on the right shows the eye’s response under normal lighting conditions and this is called the photopic response. The cones respond to light under these conditions.
As mentioned previously, cones are composed of three different photo pigments that enable color perception. This curve peaks at 555 nanometers, which means that under normal lighting conditions, the eye is most sensitive to a yellowish-green color. When the light levels drop to near total darkness, the response of the eye changes significantly as shown by the scotopic response curve on the left. At this level of light, the rods are most active and the human eye is more sensitive to the light present, and less sensitive to the range of color. Rods are highly sensitive to light but are comprised of a single photo pigment, which accounts for the loss in ability to discriminate color. At this very low light level, sensitivity to blue, violet, and ultraviolet is increased, but sensitivity to yellow and red is reduced. The heavier curve in the middle represents the eye’s response at the ambient light level found in a typical inspection booth. This curve peaks at 550 nanometers, which means the eye is most sensitive to yellowish-green color at this light level. Fluorescent penetrant inspection materials are designed to fluoresce at around 550 nanometers to produce optimal sensitivity under dim lighting conditions.
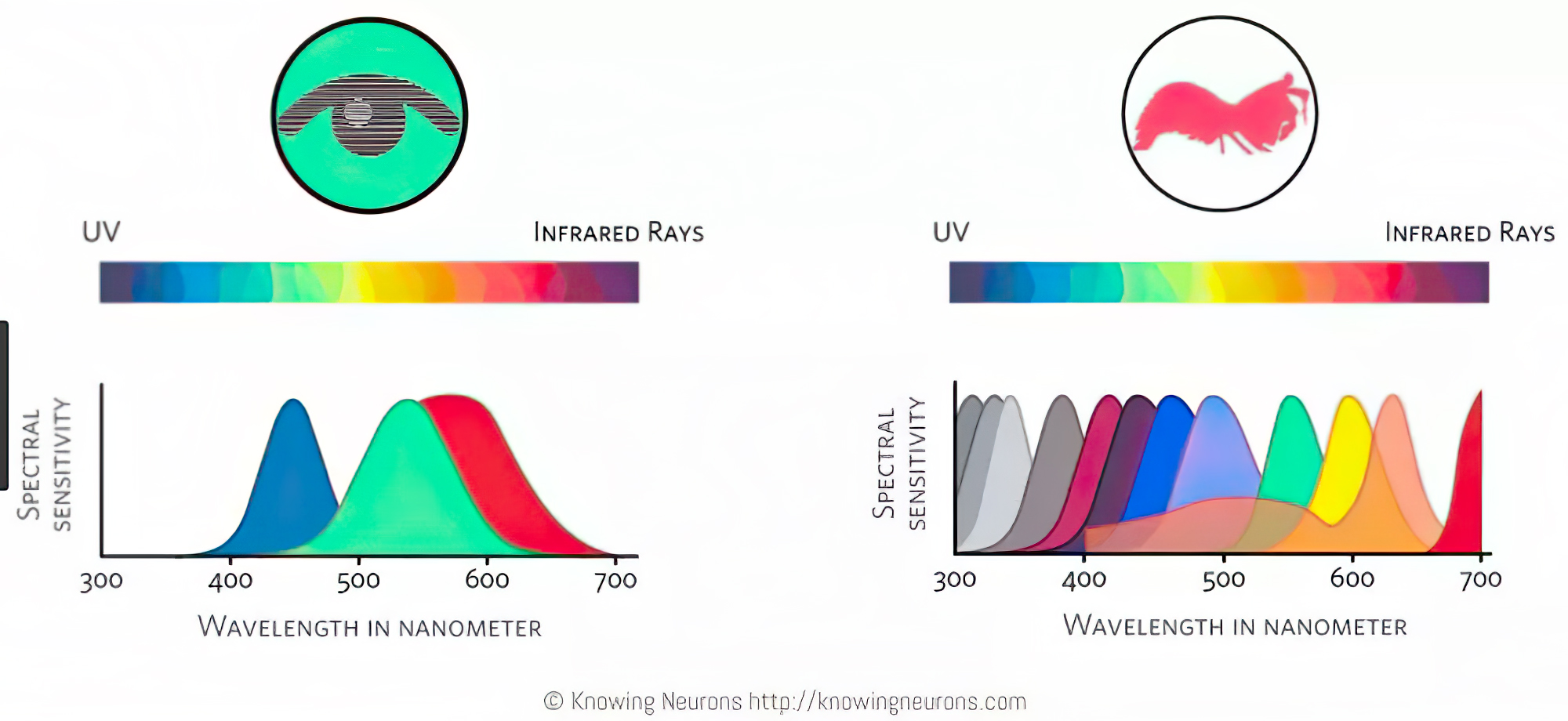

-
OLED vs QLED – What TV is better?
Read more: OLED vs QLED – What TV is better?
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs.
OLED stands for “organic light emitting diode.”
It is a fundamentally different technology from LCD, the major type of TV today.
OLED is “emissive,” meaning the pixels emit their own light.Samsung is branding its best TVs with a new acronym: “QLED”
QLED (according to Samsung) stands for “quantum dot LED TV.”
It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.”
QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.

When analyzing TVs color, it may be beneficial to consider at least 3 elements:
“Color Depth”, “Color Gamut”, and “Dynamic Range”.Color Depth (or “Bit-Depth”, e.g. 8-bit, 10-bit, 12-bit) determines how many distinct color variations (tones/shades) can be viewed on a given display.
Color Gamut (e.g. WCG) determines which specific colors can be displayed from a given “Color Space” (Rec.709, Rec.2020, DCI-P3) (i.e. the color range).
Dynamic Range (SDR, HDR) determines the luminosity range of a specific color – from its darkest shade (or tone) to its brightest.
The overall brightness range of a color will be determined by a display’s “contrast ratio”, that is, the ratio of luminance between the darkest black that can be produced and the brightest white.
Color Volume is the “Color Gamut” + the “Dynamic/Luminosity Range”.
A TV’s Color Volume will not only determine which specific colors can be displayed (the color range) but also that color’s luminosity range, which will have an affect on its “brightness”, and “colorfulness” (intensity and saturation).The better the colour volume in a TV, the closer to life the colours appear.
QLED TV can express nearly all of the colours in the DCI-P3 colour space, and of those colours, express 100% of the colour volume, thereby producing an incredible range of colours.
With OLED TV, when the image is too bright, the percentage of the colours in the colour volume produced by the TV drops significantly. The colours get washed out and can only express around 70% colour volume, making the picture quality drop too.
Note. OLED TV uses organic material, so it may lose colour expression as it ages.
Resources for more reading and comparison below
www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.html
www.newtechnologytv.com/qled-vs-oled/
news.samsung.com/za/qled-tv-vs-oled-tv
www.cnet.com/news/qled-vs-oled-samsungs-tv-tech-and-lgs-tv-tech-are-not-the-same/

-
Victor Perez – The Color Management Handbook for Visual Effects Artists
Read more: Victor Perez – The Color Management Handbook for Visual Effects ArtistsDigital Color Principles, Color Management Fundamentals & ACES Workflows










LIGHTING
-
The Color of Infinite Temperature
Read more: The Color of Infinite TemperatureThis is the color of something infinitely hot.

Of course you’d instantly be fried by gamma rays of arbitrarily high frequency, but this would be its spectrum in the visible range.
johncarlosbaez.wordpress.com/2022/01/16/the-color-of-infinite-temperature/
This is also the color of a typical neutron star. They’re so hot they look the same.
It’s also the color of the early Universe!This was worked out by David Madore.
The color he got is sRGB(148,177,255).
www.htmlcsscolor.com/hex/94B1FFAnd according to the experts who sip latte all day and make up names for colors, this color is called ‘Perano’.
-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
-
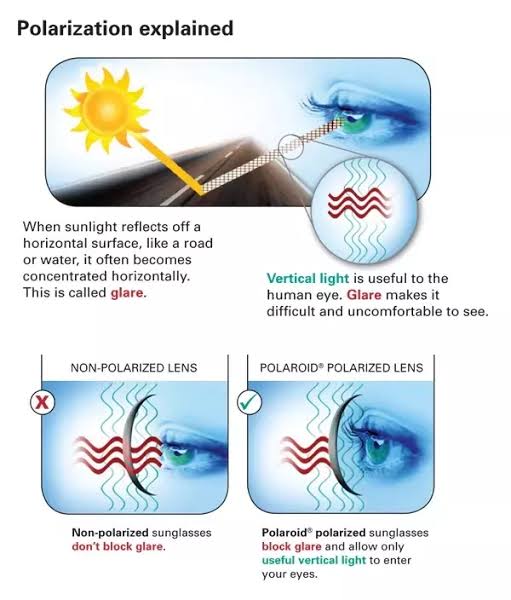
Polarised vs unpolarized filtering
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
Details such as glare and hard edges are not removed, but greatly reduced.This method is usually used in VFX to capture raw images with the least amount of specular diffusion or pollution, thus allowing artists to infer detail back through typical shading and rendering techniques and on demand.
Light reflected from a non-metallic surface becomes polarized; this effect is maximum at Brewster’s angle, about 56° from the vertical for common glass.
A polarizer rotated to pass only light polarized in the direction perpendicular to the reflected light will absorb much of it. This absorption allows glare reflected from, for example, a body of water or a road to be reduced. Reflections from shiny surfaces (e.g. vegetation, sweaty skin, water surfaces, glass) are also reduced. This allows the natural color and detail of what is beneath to come through. Reflections from a window into a dark interior can be much reduced, allowing it to be seen through. (The same effects are available for vision by using polarizing sunglasses.)

www.physicsclassroom.com/class/light/u12l1e.cfm
Some of the light coming from the sky is polarized (bees use this phenomenon for navigation). The electrons in the air molecules cause a scattering of sunlight in all directions. This explains why the sky is not dark during the day. But when looked at from the sides, the light emitted from a specific electron is totally polarized.[3] Hence, a picture taken in a direction at 90 degrees from the sun can take advantage of this polarization.

Use of a polarizing filter, in the correct direction, will filter out the polarized component of skylight, darkening the sky; the landscape below it, and clouds, will be less affected, giving a photograph with a darker and more dramatic sky, and emphasizing the clouds.

There are two types of polarizing filters readily available, linear and “circular”, which have exactly the same effect photographically. But the metering and auto-focus sensors in certain cameras, including virtually all auto-focus SLRs, will not work properly with linear polarizers because the beam splitters used to split off the light for focusing and metering are polarization-dependent.
Polarizing filters reduce the light passed through to the film or sensor by about one to three stops (2–8×) depending on how much of the light is polarized at the filter angle selected. Auto-exposure cameras will adjust for this by widening the aperture, lengthening the time the shutter is open, and/or increasing the ASA/ISO speed of the camera.
www.adorama.com/alc/nd-filter-vs-polarizer-what%25e2%2580%2599s-the-difference
Neutral Density (ND) filters help control image exposure by reducing the light that enters the camera so that you can have more control of your depth of field and shutter speed. Polarizers or polarizing filters work in a similar way, but the difference is that they selectively let light waves of a certain polarization pass through. This effect helps create more vivid colors in an image, as well as manage glare and reflections from water surfaces. Both are regarded as some of the best filters for landscape and travel photography as they reduce the dynamic range in high-contrast images, thus enabling photographers to capture more realistic and dramatic sceneries.
shopfelixgray.com/blog/polarized-vs-non-polarized-sunglasses/
www.eyebuydirect.com/blog/difference-polarized-nonpolarized-sunglasses/
-
What is the Light Field?
Read more: What is the Light Field?http://lightfield-forum.com/what-is-the-lightfield/
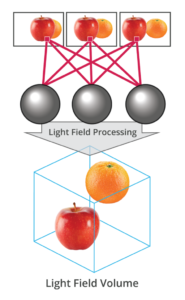
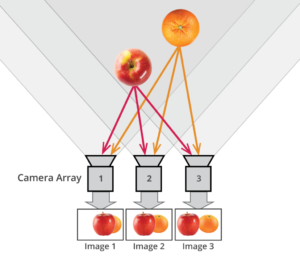
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array
-
Simulon – a Hollywood production studio app in the hands of an independent creator with access to consumer hardware, LDRi to HDRi through ML
Read more: Simulon – a Hollywood production studio app in the hands of an independent creator with access to consumer hardware, LDRi to HDRi through MLDivesh Naidoo: The video below was made with a live in-camera preview and auto-exposure matching, no camera solve, no HDRI capture and no manual compositing setup. Using the new Simulon phone app.
LDR to HDR through ML
https://simulon.typeform.com/betatest
Process example
-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Read more: Rec-2020 – TVs new color gamut standard used by Dolby Vision?https://www.hdrsoft.com/resources/dri.html#bit-depth
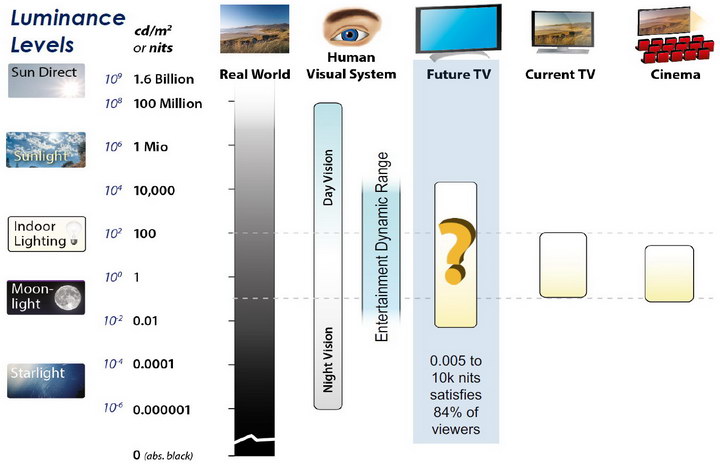
The dynamic range is a ratio between the maximum and minimum values of a physical measurement. Its definition depends on what the dynamic range refers to.
For a scene: Dynamic range is the ratio between the brightest and darkest parts of the scene.
For a camera: Dynamic range is the ratio of saturation to noise. More specifically, the ratio of the intensity that just saturates the camera to the intensity that just lifts the camera response one standard deviation above camera noise.
For a display: Dynamic range is the ratio between the maximum and minimum intensities emitted from the screen.
The Dynamic Range of real-world scenes can be quite high — ratios of 100,000:1 are common in the natural world. An HDR (High Dynamic Range) image stores pixel values that span the whole tonal range of real-world scenes. Therefore, an HDR image is encoded in a format that allows the largest range of values, e.g. floating-point values stored with 32 bits per color channel. Another characteristics of an HDR image is that it stores linear values. This means that the value of a pixel from an HDR image is proportional to the amount of light measured by the camera.
For TVs HDR is great, but it’s not the only new TV feature worth discussing.
Wide color gamut, or WCG, is often lumped in with HDR. While they’re often found together, they’re not intrinsically linked. Where HDR is an increase in the dynamic range of the picture (with contrast and brighter highlights in particular), a TV’s wide color gamut coverage refers to how much of the new, larger color gamuts a TV can display.
Wide color gamuts only really matter for HDR video sources like UHD Blu-rays and some streaming video, as only HDR sources are meant to take advantage of the ability to display more colors.
www.cnet.com/how-to/what-is-wide-color-gamut-wcg/
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed through a pixel; the other aspect is how broad a range of colors can be expressed (the gamut)
Image rendering bit depth
Wide color gamuts include a greater number of colors than what most current TVs can display, so the greater a TV’s coverage of a wide color gamut, the more colors a TV will be able to reproduce.
When we talk about a color space or color gamut we refer to the range of color values stored in an image. The perception of these color also requires a display that has been tuned with to resolve these color profiles at best. This is often referred to as a ‘viewer lut’.
So this comes also usually paired with an increase in bit depth, going from the old 8 bit system (256 shades per color, with the potential of over 16.7 million colors: 256 green x 256 blue x 256 red) to 10 (1024+ shades per color, with access to over a billion colors) or higher bits, like 12 bit (4096 shades per RGB for 68 billion colors).
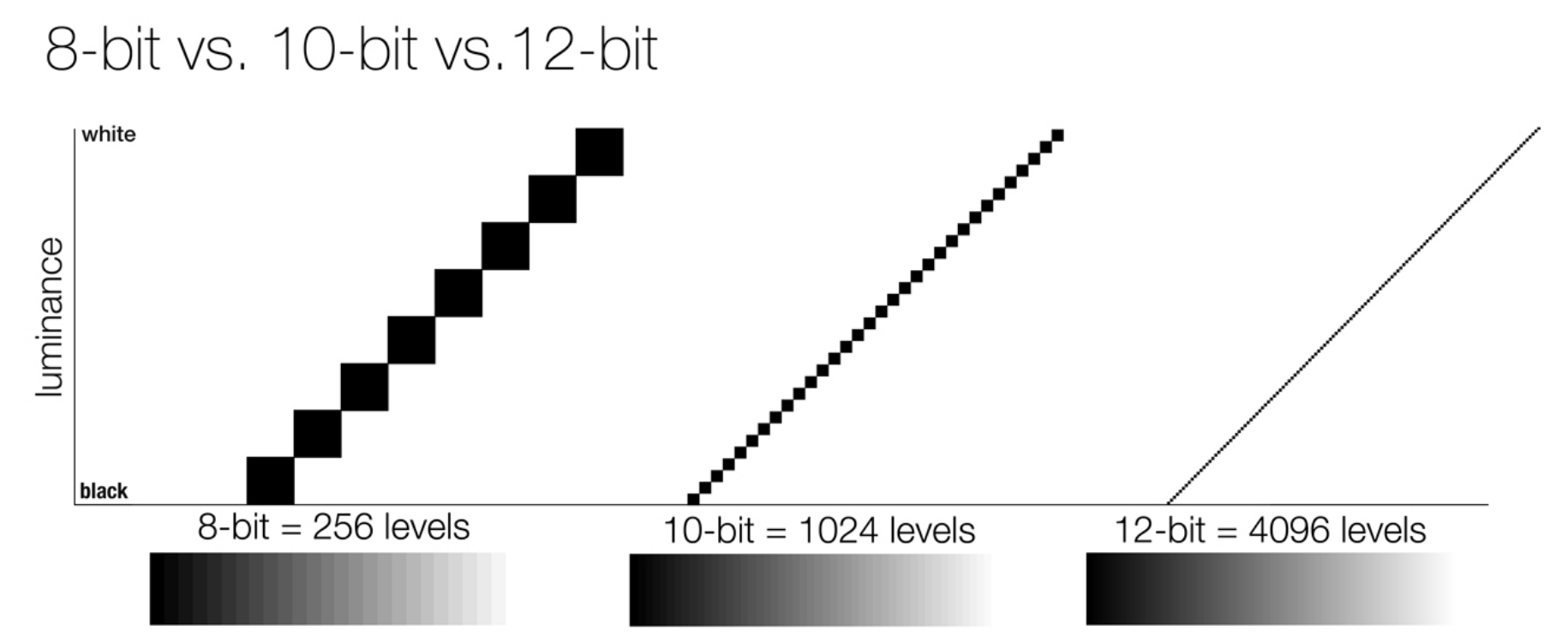
The advantage of higher bit depth is in the ability to bias color with the minimum loss.
For an extreme example, raising the brightness from a completely dark image allows for better reproduction, independently on the reproduction medium, due to the amount of data available at editing time:
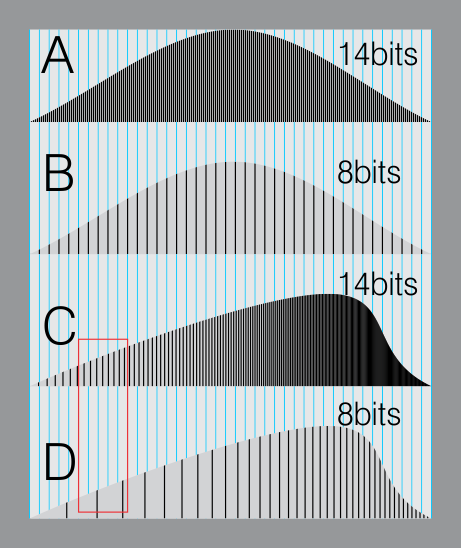
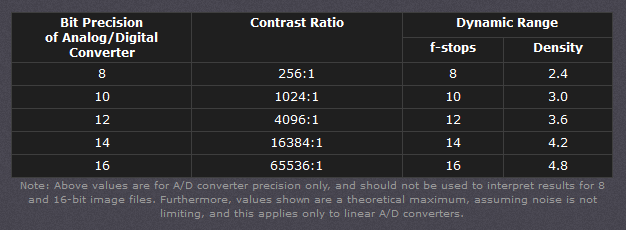
For reference, 8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.
https://www.cambridgeincolour.com/tutorials/dynamic-range.htm
https://www.hdrsoft.com/resources/dri.html#bit-depth
Note that the number of bits itself may be a misleading indication of the real dynamic range that the image reproduces — converting a Low Dynamic Range image to a higher bit depth does not change its dynamic range, of course.
- 8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
- 16-bit images (i.e. 48 bits per pixel for a color image) resulting from RAW conversion are still considered Low Dynamic Range, even though the range of values they can encode is significantly higher than for 8-bit images (65536 versus 256). Note that converting a RAW file involves applying a tonal curve that compresses the dynamic range of the RAW data so that the converted image shows correctly on low dynamic range monitors. The need to adapt the output image file to the dynamic range of the display is the factor that dictates how much the dynamic range is compressed, not the output bit-depth. By using 16 instead of 8 bits, you will gain precision but you will not gain dynamic range.
- 32-bit images (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range.Unlike 8- and 16-bit images which can take a finite number of values, 32-bit images are coded using floating point numbers, which means the values they can take is unlimited.It is important to note, though, that storing an image in a 32-bit HDR format is a necessary condition for an HDR image but not a sufficient one. When an image comes from a single capture with a standard camera, it will remain a Low Dynamic Range image,
Also note that bit depth and dynamic range are often confused as one, but are indeed separate concepts and there is no direct one to one relationship between them. Bit depth is about capacity, dynamic range is about the actual ratio of data stored.
The bit depth of a capturing or displaying device gives you an indication of its dynamic range capacity. That is, the highest dynamic range that the device would be capable of reproducing if all other constraints are eliminated.https://rawpedia.rawtherapee.com/Bit_Depth
Finally, note that there are two ways to “count” bits for an image — either the number of bits per color channel (BPC) or the number of bits per pixel (BPP). A bit (0,1) is the smallest unit of data stored in a computer.
For a grayscale image, 8-bit means that each pixel can be one of 256 levels of gray (256 is 2 to the power 8).
For an RGB color image, 8-bit means that each one of the three color channels can be one of 256 levels of color.
Since each pixel is represented by 3 colors in this case, 8-bit per color channel actually means 24-bit per pixel.Similarly, 16-bit for an RGB image means 65,536 levels per color channel and 48-bit per pixel.
To complicate matters, when an image is classified as 16-bit, it just means that it can store a maximum 65,535 values. It does not necessarily mean that it actually spans that range. If the camera sensors can not capture more than 12 bits of tonal values, the actual bit depth of the image will be at best 12-bit and probably less because of noise.
The following table attempts to summarize the above for the case of an RGB color image.
Type of digital support Bit depth per color channel Bit depth per pixel FStops Theoretical maximum Dynamic Range Reality 8-bit 8 24 8 256:1 most consumer images 12-bit CCD 12 36 12 4,096:1 real maximum limited by noise 14-bit CCD 14 42 14 16,384:1 real maximum limited by noise 16-bit TIFF (integer) 16 48 16 65,536:1 bit-depth in this case is not directly related to the dynamic range captured 16-bit float EXR 16 48 30 65,536:1 values are distributed more closely in the (lower) darker tones than in the (higher) lighter ones, thus allowing for a more accurate description of the tones more significant to humans. The range of normalized 16-bit floats can represent thirty stops of information with 1024 steps per stop. We have eighteen and a half stops over middle gray, and eleven and a half below. The denormalized numbers provide an additional ten stops with decreasing precision per stop.
http://download.nvidia.com/developer/GPU_Gems/CD_Image/Image_Processing/OpenEXR/OpenEXR-1.0.6/doc/#recsHDR image (e.g. Radiance format) 32 96 “infinite” 4.3 billion:1 real maximum limited by the captured dynamic range 32-bit floats are often called “single-precision” floats, and 64-bit floats are often called “double-precision” floats. 16-bit floats therefore are called “half-precision” floats, or just “half floats”.
https://petapixel.com/2018/09/19/8-12-14-vs-16-bit-depth-what-do-you-really-need
On a separate note, even Photoshop does not handle 16bit per channel. Photoshop does actually use 16-bits per channel. However, it treats the 16th digit differently – it is simply added to the value created from the first 15-digits. This is sometimes called 15+1 bits. This means that instead of 216 possible values (which would be 65,536 possible values) there are only 215+1 possible values (which is 32,768 +1 = 32,769 possible values).
Rec-601 (for the older SDTV format, very similar to rec-709) and Rec-709 (the HDTV’s recommended set of color standards, at times also referred to sRGB, although not exactly the same) are currently the most spread color formats and hardware configurations in the world.
Following those you can find the larger P3 gamut, more commonly used in theaters and in digital production houses (with small variations and improvements to color coverage), as well as most of best 4K/WCG TVs.
And a new standard is now promoted against P3, referred to Rec-2020 and UHDTV.

It is still debatable if this is going to be adopted at consumer level beyond the P3, mainly due to lack of hardware supporting it. But initial tests do prove that it would be a future proof investment.
www.colour-science.org/anders-langlands/
Rec. 2020 is ultimately designed for television, and not cinema. Therefore, it is to be expected that its properties must behave according to current signal processing standards. In this respect, its foundation is based on current HD and SD video signal characteristics.
As far as color bit depth is concerned, it allows for a maximum of 12 bits, which is more than enough for humans.
Comparing standards, REC-709 covers 35.9% of the human visible spectrum. P3 45.5%. And REC-2020 75.8%.
https://www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.htmlComparing coverage to hardware devices
To note that all the new standards generally score very high on the Pointer’s Gamut chart. But with REC-2020 scoring 99.9% vs P3 at 88.2%.
www.tftcentral.co.uk/articles/pointers_gamut.htmhttps://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
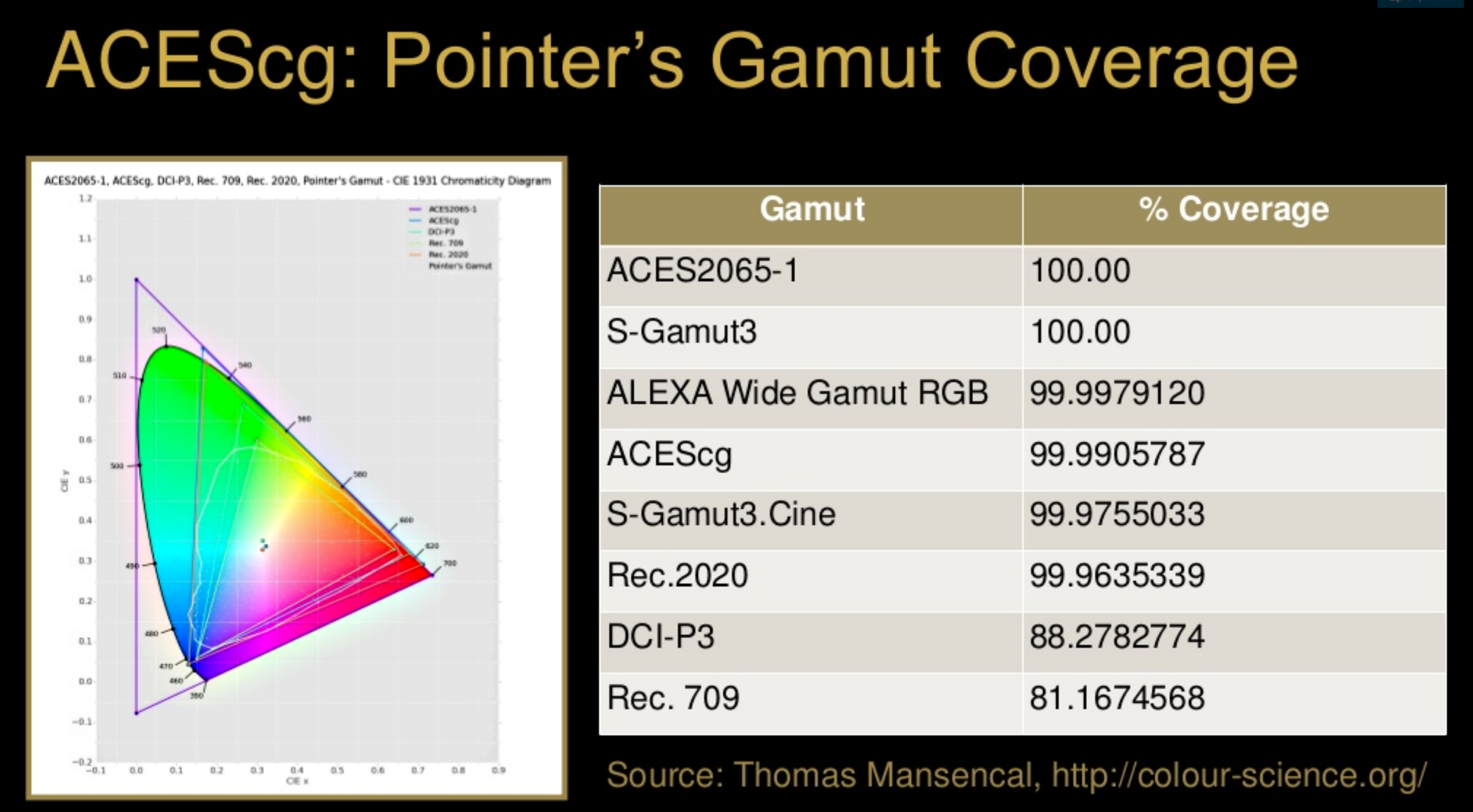
The Pointer’s gamut is (an approximation of) the gamut of real surface colors as can be seen by the human eye, based on the research by Michael R. Pointer (1980). What this means is that every color that can be reflected by the surface of an object of any material is inside the Pointer’s gamut. Basically establishing a widely respected target for color reproduction. Visually, Pointers Gamut represents the colors we see about us in the natural world. Colors outside Pointers Gamut include those that do not occur naturally, such as neon lights and computer-generated colors possible in animation. Which would partially be accounted for with the new gamuts.
cinepedia.com/picture/color-gamut/
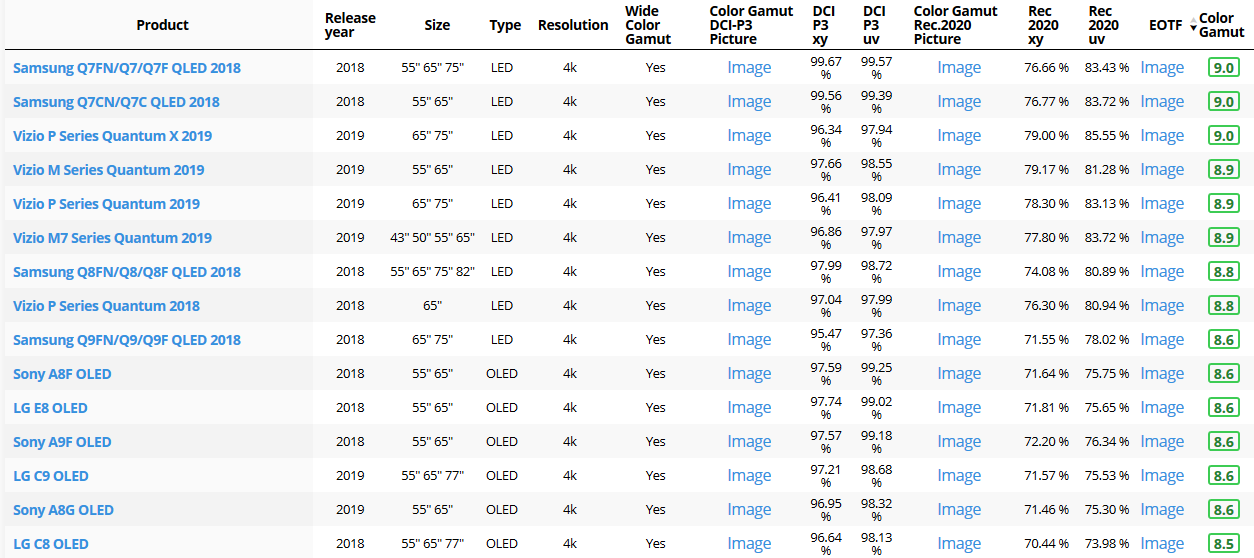
Not all current TVs can support the full spread of the new gamuts. Here is a list of modern TVs’ color coverage in percentage:
www.rtings.com/tv/tests/picture-quality/wide-color-gamut-rec-709-dci-p3-rec-2020There are no TVs that can come close to displaying all the colors within Rec.2020, and there likely won’t be for at least a few years. However, to help future-proof the technology, Rec.2020 support is already baked into the HDR spec. That means that the same genuine HDR media that fills the DCI P3 space on a compatible TV now, will in a few years also fill Rec.2020 on a TV supporting that larger space.
Rec.2020’s main gains are in the number of new tones of green that it will display, though it also offers improvements to the number of blue and red colors as well. Altogether, Rec.2020 will cover about 75% of the visual spectrum, which is a sizeable increase in coverage even over DCI P3.
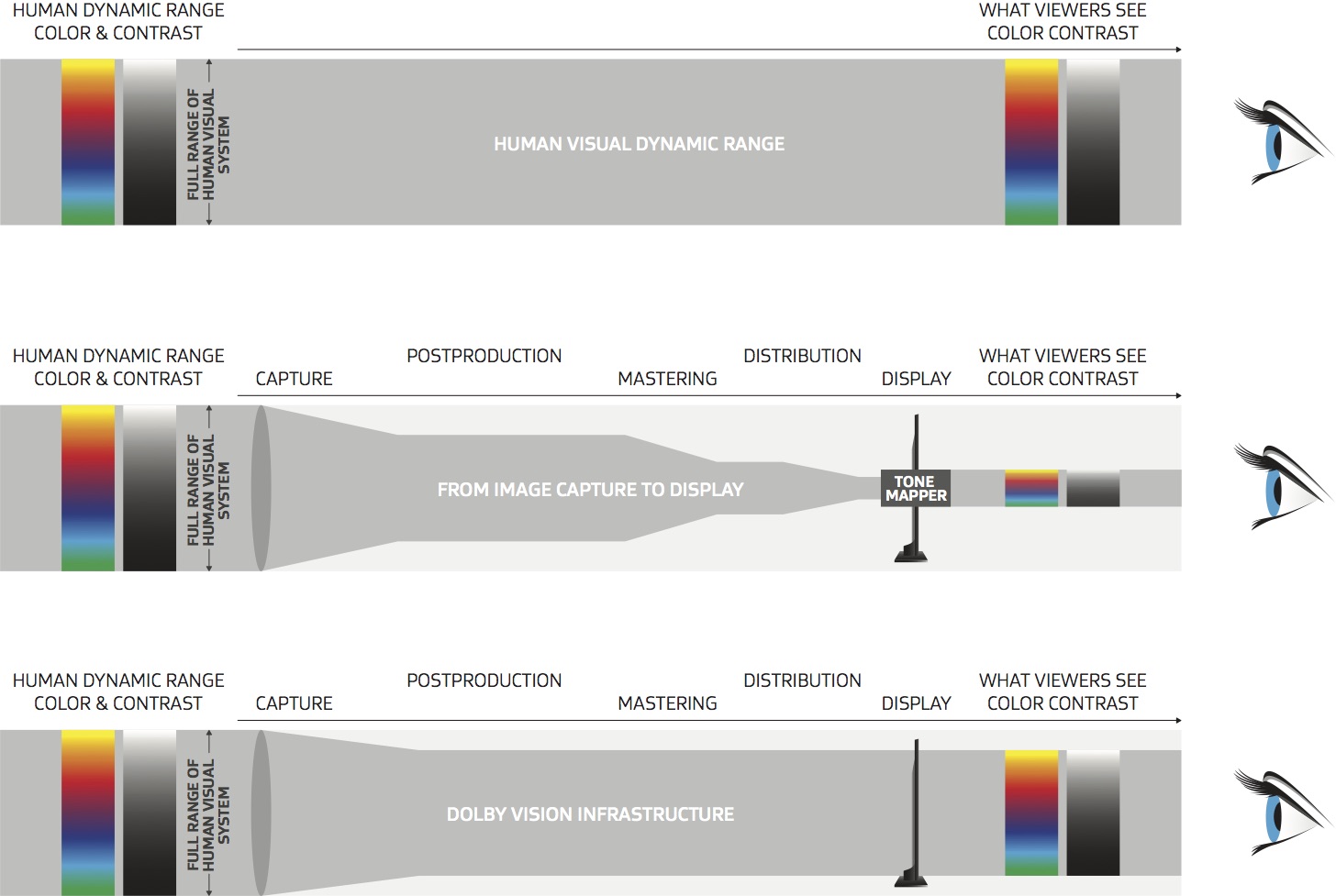
Dolby Vision
https://www.highdefdigest.com/news/show/what-is-dolby-vision/39049
https://www.techhive.com/article/3237232/dolby-vision-vs-hdr10-which-is-best.html
Dolby Vision is a proprietary end-to-end High Dynamic Range (HDR) format that covers content creation and playback through select cinemas, Ultra HD displays, and 4K titles. Like other HDR standards, the process uses expanded brightness to improve contrast between dark and light aspects of an image, bringing out deeper black levels and more realistic details in specular highlights — like the sun reflecting off of an ocean — in specially graded Dolby Vision material.
The iPhone 12 Pro gets the ability to record 4K 10-bit HDR video. According to Apple, it is the very first smartphone that is capable of capturing Dolby Vision HDR.
The iPhone 12 Pro takes two separate exposures and runs them through Apple’s custom image signal processor to create a histogram, which is a graph of the tonal values in each frame. The Dolby Vision metadata is then generated based on that histogram. In Laymen’s terms, it is essentially doing real-time grading while you are shooting. This is only possible due to the A14 Bionic chip.
Dolby Vision also allows for 12-bit color, as opposed to HDR10’s and HDR10+’s 10-bit color. While no retail TV we’re aware of supports 12-bit color, Dolby claims it can be down-sampled in such a way as to render 10-bit color more accurately.

Resources for more reading:
https://www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.html
wolfcrow.com/say-hello-to-rec-2020-the-color-space-of-the-future/
www.cnet.com/news/ultra-hd-tv-color-part-ii-the-future/
-
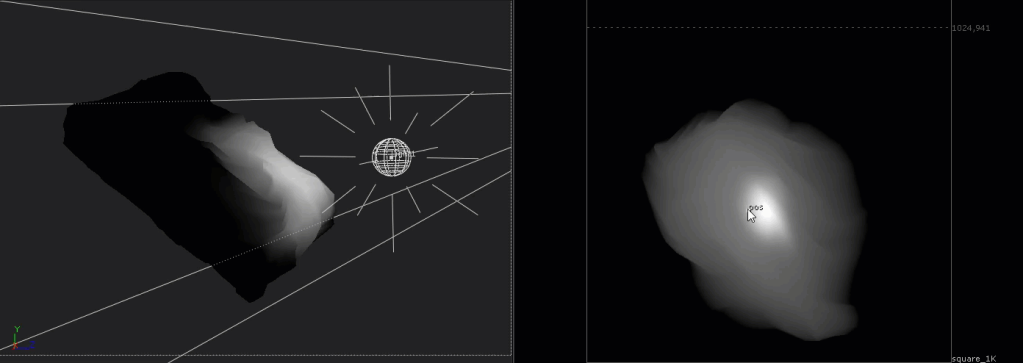
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
# bottom left coordinates = 0,0 import numpy as np import cv2 # Load the HDR or EXR image image = cv2.imread('your_image_path.exr', cv2.IMREAD_UNCHANGED) # Load as-is without modification # Calculate the luminance from the HDR channels (assuming RGB format) luminance = np.dot(image[..., :3], [0.299, 0.587, 0.114]) # Set a threshold value based on estimated EV threshold_value = 2.4 # Estimated threshold value based on 4.8 EV # Apply the threshold to identify bright areas # Theluminancearray contains the calculated luminance values for each pixel in the image. # Thethreshold_valueis a user-defined value that represents a cutoff point, separating "bright" and "dark" areas in terms of perceived luminance.thresholded = (luminance > threshold_value) * 255 # Convert the thresholded image to uint8 for contour detection thresholded = thresholded.astype(np.uint8) # Find contours of the bright areas contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # Create a list to store the bounding boxes of bright areas bright_areas = [] # Iterate through contours and extract bounding boxes for contour in contours: x, y, w, h = cv2.boundingRect(contour) # Adjust y-coordinate based on bottom-left origin y_bottom_left_origin = image.shape[0] - (y + h) bright_areas.append((x, y_bottom_left_origin, x + w, y_bottom_left_origin + h)) # Store as (x1, y1, x2, y2) # Print the identified bright areas print("Bright Areas (x1, y1, x2, y2):") for area in bright_areas: print(area)More details
Luminance and Exposure in an EXR Image:
- An EXR (Extended Dynamic Range) image format is often used to store high dynamic range (HDR) images that contain a wide range of luminance values, capturing both dark and bright areas.
- Luminance refers to the perceived brightness of a pixel in an image. In an RGB image, luminance is often calculated using a weighted sum of the red, green, and blue channels, where different weights are assigned to each channel to account for human perception.
- In an EXR image, the pixel values can represent radiometrically accurate scene values, including actual radiance or irradiance levels. These values are directly related to the amount of light emitted or reflected by objects in the scene.
The luminance line is calculating the luminance of each pixel in the image using a weighted sum of the red, green, and blue channels. The three float values [0.299, 0.587, 0.114] are the weights used to perform this calculation.
These weights are based on the concept of luminosity, which aims to approximate the perceived brightness of a color by taking into account the human eye’s sensitivity to different colors. The values are often derived from the NTSC (National Television System Committee) standard, which is used in various color image processing operations.
Here’s the breakdown of the float values:
- 0.299: Weight for the red channel.
- 0.587: Weight for the green channel.
- 0.114: Weight for the blue channel.
The weighted sum of these channels helps create a grayscale image where the pixel values represent the perceived brightness. This technique is often used when converting a color image to grayscale or when calculating luminance for certain operations, as it takes into account the human eye’s sensitivity to different colors.
For the threshold, remember that the exact relationship between EV values and pixel values can depend on the tone-mapping or normalization applied to the HDR image, as well as the dynamic range of the image itself.
To establish a relationship between exposure and the threshold value, you can consider the relationship between linear and logarithmic scales:
- Linear and Logarithmic Scales:
- Exposure values in an EXR image are often represented in logarithmic scales, such as EV (exposure value). Each increment in EV represents a doubling or halving of the amount of light captured.
- Threshold values for luminance thresholding are usually linear, representing an actual luminance level.
- Conversion Between Scales:
- To establish a mathematical relationship, you need to convert between the logarithmic exposure scale and the linear threshold scale.
- One common method is to use a power function. For instance, you can use a power function to convert EV to a linear intensity value.
threshold_value = base_value * (2 ** EV)Here,
EVis the exposure value,base_valueis a scaling factor that determines the relationship between EV and threshold_value, and2 ** EVis used to convert the logarithmic EV to a linear intensity value. - Choosing the Base Value:
- The
base_valuefactor should be determined based on the dynamic range of your EXR image and the specific luminance values you are dealing with. - You may need to experiment with different values of
base_valueto achieve the desired separation of bright areas from the rest of the image.
- The
Let’s say you have an EXR image with a dynamic range of 12 EV, which is a common range for many high dynamic range images. In this case, you want to set a threshold value that corresponds to a certain number of EV above the middle gray level (which is often considered to be around 0.18).
Here’s an example of how you might determine a
base_valueto achieve this:# Define the dynamic range of the image in EV dynamic_range = 12 # Choose the desired number of EV above middle gray for thresholding desired_ev_above_middle_gray = 2 # Calculate the threshold value based on the desired EV above middle gray threshold_value = 0.18 * (2 ** (desired_ev_above_middle_gray / dynamic_range)) print("Threshold Value:", threshold_value)





{kind=link}
{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
