


COMPOSITION
-
StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
Read more: StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
https://www.studiobinder.com/blog/camera-lens-buying-guide/
https://www.studiobinder.com/blog/e-books/camera-lenses-explained-volume-1-ebook
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
















DESIGN
-
Turn Yourself Into an Action Figure Using ChatGPT
Read more: Turn Yourself Into an Action Figure Using ChatGPT
ChatGPT Action Figure Prompts:
Create an action figure from the photo. It must be visualised in a realistic way. There should be accessories next to the figure like a UX designer have, Macbook Pro, a camera, drawing tablet, headset etc. Add a hole to the top of the box in the action figure. Also write the text “UX Mate” and below it “Keep Learning! Keep Designing
Use this image to create a picture of a action figure toy of a construction worker in a blister package from head to toe with accessories including a hammer, a staple gun and a ladder. The package should read “Kirk The Handy Man”
Create a realistic image of a toy action figure box. The box should be designed in a toy-equipment/action-figure style, with a cut-out window at the top like classic action figure packaging. The main color of the box and moleskine notebook should match the color of my jacket (referenced visually). Add colorful Mexican skull decorations across the box for a vibrant and artistic flair. Inside the box, include a “Your name” action figure, posed heroically. Next to the figure, arrange the following “equipment” in a stylized layout: • item 1 • item 2 … On the box, write: “Your name” (bold title font) Underneath: “Your role or anything else” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. On the box, write: “Your name” (bold title font) Underneath: “Your role or description” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. Prompt on Kling AI The figure steps out of its toy packaging and begins walking forward. As he continues to walk, the camera gradually zooms out in sync with his movement.
“Create image. Create a toy of the person in the photo. Let it be an action figure. Next to the figure, there should be the toy’s equipment, each in its individual blisters. 1) a book called “Tecnoforma”. 2) A 3-headed dog with a tag that says “Troika” and a bone at its feet with word “austerity” written on it. 3) a three-headed Hydra with with a tag called “Geringonça”. 4) a book titled “D. Sebastião”. Don’t repeat the equipment under any circumstance. The card holding the blister should be strong orange. Also, on top of the box, write ‘Pedro Passos Coelho’ and underneath it, ‘PSD action figure’. The figure and equipment must all be inside blisters. Visualize this in a realistic way.”


















COLOR
-
THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
Read more: THOMAS MANSENCAL – The Apparent Simplicity of RGB Rendering
https://thomasmansencal.substack.com/p/the-apparent-simplicity-of-rgb-rendering
The primary goal of physically-based rendering (PBR) is to create a simulation that accurately reproduces the imaging process of electro-magnetic spectrum radiation incident to an observer. This simulation should be indistinguishable from reality for a similar observer.
Because a camera is not sensitive to incident light the same way than a human observer, the images it captures are transformed to be colorimetric. A project might require infrared imaging simulation, a portion of the electro-magnetic spectrum that is invisible to us. Radically different observers might image the same scene but the act of observing does not change the intrinsic properties of the objects being imaged. Consequently, the physical modelling of the virtual scene should be independent of the observer.
-
Willem Zwarthoed – Aces gamut in VFX production pdf
Read more: Willem Zwarthoed – Aces gamut in VFX production pdfhttps://www.provideocoalition.com/color-management-part-12-introducing-aces/
Local copy:
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications










![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")








LIGHTING
-
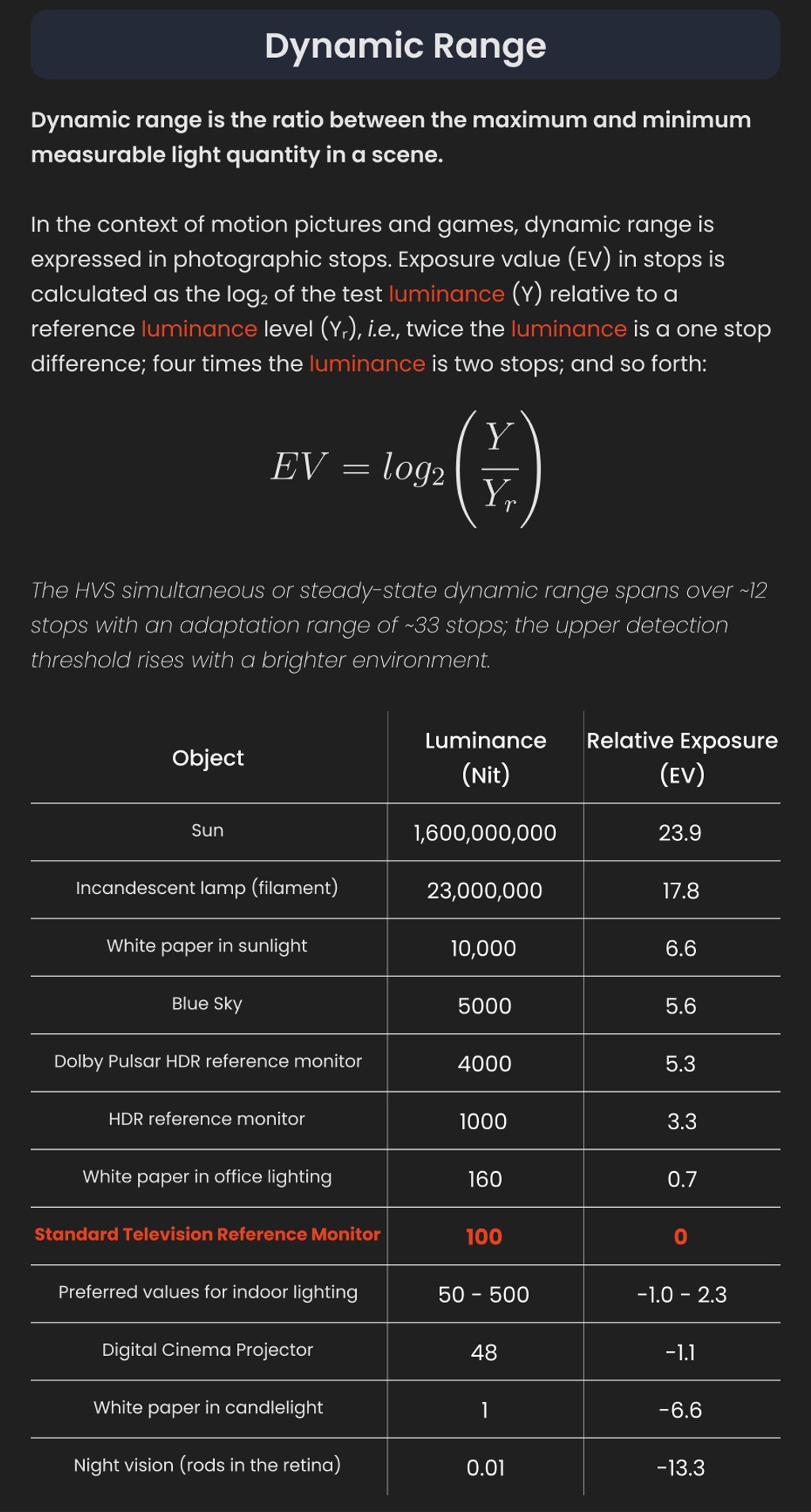
Convert between light exposure and intensity
Read more: Convert between light exposure and intensityimport math,sys def Exposure2Intensity(exposure): exp = float(exposure) result = math.pow(2,exp) print(result) Exposure2Intensity(0) def Intensity2Exposure(intensity): inarg = float(intensity) if inarg == 0: print("Exposure of zero intensity is undefined.") return if inarg < 1e-323: inarg = max(inarg, 1e-323) print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)") result = math.log(inarg, 2) print(result) Intensity2Exposure(0.1)Why Exposure?
Exposure is a stop value that multiplies the intensity by 2 to the power of the stop. Increasing exposure by 1 results in double the amount of light.
Artists think in “stops.” Doubling or halving brightness is easy math and common in grading and look-dev.
Exposure counts doublings in whole stops:- +1 stop = ×2 brightness
- −1 stop = ×0.5 brightness
This gives perceptually even controls across both bright and dark values.
Why Intensity?
Intensity is linear.
It’s what render engines and compositors expect when:- Summing values
- Averaging pixels
- Multiplying or filtering pixel data
Use intensity when you need the actual math on pixel/light data.
Formulas (from your Python)
- Intensity from exposure: intensity = 2**exposure
- Exposure from intensity: exposure = log₂(intensity)
Guardrails:
- Intensity must be > 0 to compute exposure.
- If intensity = 0 → exposure is undefined.
- Clamp tiny values (e.g.
1e−323) before using log₂.
Use Exposure (stops) when…
- You want artist-friendly sliders (−5…+5 stops)
- Adjusting look-dev or grading in even stops
- Matching plates with quick ±1 stop tweaks
- Tweening brightness changes smoothly across ranges
Use Intensity (linear) when…
- Storing raw pixel/light values
- Multiplying textures or lights by a gain
- Performing sums, averages, and filters
- Feeding values to render engines expecting linear data
Examples
- +2 stops → 2**2 = 4.0 (×4)
- +1 stop → 2**1 = 2.0 (×2)
- 0 stop → 2**0 = 1.0 (×1)
- −1 stop → 2**(−1) = 0.5 (×0.5)
- −2 stops → 2**(−2) = 0.25 (×0.25)
- Intensity 0.1 → exposure = log₂(0.1) ≈ −3.32
Rule of thumb
Think in stops (exposure) for controls and matching.
Compute in linear (intensity) for rendering and math. -
7 Easy Portrait Lighting Setups
Read more: 7 Easy Portrait Lighting Setups
Butterfly
Loop
Rembrandt
Split
Rim
Broad
Short
-
About green screens
Read more: About green screenshackaday.com/2015/02/07/how-green-screen-worked-before-computers/
www.newtek.com/blog/tips/best-green-screen-materials/
www.chromawall.com/blog//chroma-key-green

Chroma Key Green, the color of green screens is also known as Chroma Green and is valued at approximately 354C in the Pantone color matching system (PMS).
Chroma Green can be broken down in many different ways. Here is green screen green as other values useful for both physical and digital production:
Green Screen as RGB Color Value: 0, 177, 64
Green Screen as CMYK Color Value: 81, 0, 92, 0
Green Screen as Hex Color Value: #00b140
Green Screen as Websafe Color Value: #009933Chroma Key Green is reasonably close to an 18% gray reflectance.
Illuminate your green screen with an uniform source with less than 2/3 EV variation.
The level of brightness at any given f-stop should be equivalent to a 90% white card under the same lighting. -
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…)













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
-
Cinematographers Blueprint 300dpi poster
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Advanced Computer Vision with Python OpenCV and Mediapipe
-
Godot Cheat Sheets
-
4dv.ai – Remote Interactive 3D Holographic Presentation Technology and System running on the PlayCanvas engine
-
The Public Domain Is Working Again — No Thanks To Disney
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
