


COMPOSITION
-
9 Best Hacks to Make a Cinematic Video with Any Camera
Read more: 9 Best Hacks to Make a Cinematic Video with Any Camerahttps://www.flexclip.com/learn/cinematic-video.html
- Frame Your Shots to Create Depth
- Create Shallow Depth of Field
- Avoid Shaky Footage and Use Flexible Camera Movements
- Properly Use Slow Motion
- Use Cinematic Lighting Techniques
- Apply Color Grading
- Use Cinematic Music and SFX
- Add Cinematic Fonts and Text Effects
- Create the Cinematic Bar at the Top and the Bottom

-
Key/Fill ratios and scene composition using false colors
Read more: Key/Fill ratios and scene composition using false colors
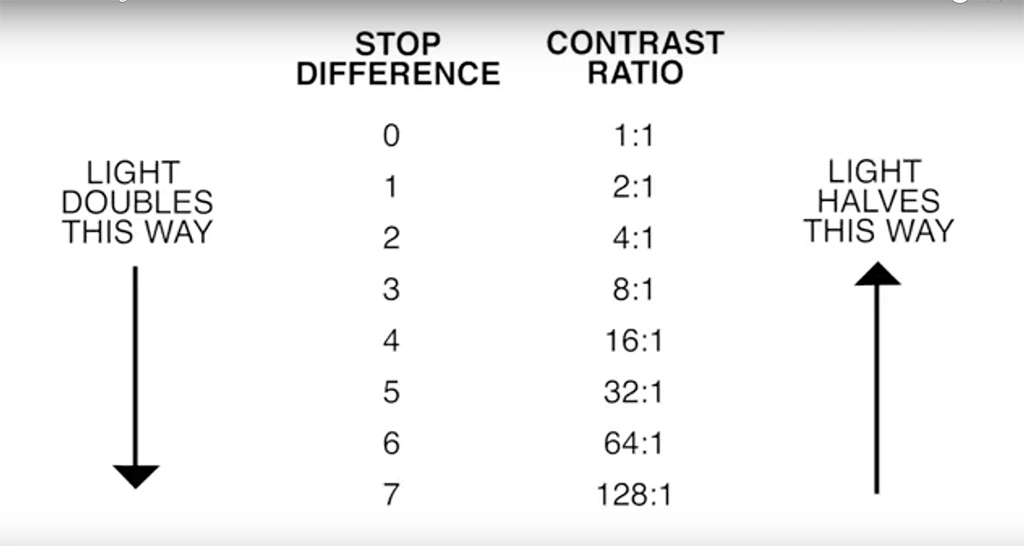
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
Let’s say you grabbed a measurement from your key light of f/8.0. Then, when you measured your fill light area, you get a reading of f/4.0. This will lead you to a contrast ratio of 4:1 because there are two stops between f/4.0 and f/8.0 and each stop doubles the amount of light. In other words, two stops x twice the light per stop = four times as much light at f/8.0 than at f/4.0.

theslantedlens.com/2017/lighting-ratios-photo-video/
Examples in the post
-
HuggingFace ai-comic-factory – a FREE AI Comic Book Creator
Read more: HuggingFace ai-comic-factory – a FREE AI Comic Book Creatorhttps://huggingface.co/spaces/jbilcke-hf/ai-comic-factory

this is the epic story of a group of talented digital artists trying to overcame daily technical challenges to achieve incredibly photorealistic projects of monsters and aliens















DESIGN
-
Kristina Kashtanova – “This is how GPT-4 sees and hears itself”
Read more: Kristina Kashtanova – “This is how GPT-4 sees and hears itself”“I used GPT-4 to describe itself. Then I used its description to generate an image, a video based on this image and a soundtrack.
Tools I used: GPT-4, Midjourney, Kaiber AI, Mubert, RunwayML
This is the description I used that GPT-4 had of itself as a prompt to text-to-image, image-to-video, and text-to-music. I put the video and sound together in RunwayML.
GPT-4 described itself as: “Imagine a sleek, metallic sphere with a smooth surface, representing the vast knowledge contained within the model. The sphere emits a soft, pulsating glow that shifts between various colors, symbolizing the dynamic nature of the AI as it processes information and generates responses. The sphere appears to float in a digital environment, surrounded by streams of data and code, reflecting the complex algorithms and computing power behind the AI”
-
VQGAN + CLIP AI made Music Video for the song Canvas by Resonate
Read more: VQGAN + CLIP AI made Music Video for the song Canvas by Resonate
” In this video, I utilized artificial intelligence to generate an animated music video for the song Canvas by Resonate. This tool allows anyone to generate beautiful images using only text as the input. My question was, what if I used song lyrics as input to the AI, can I make perfect music synchronized videos automatically with the push of a button? Let me know how you think the AI did in this visual interpretation of the song.
After getting caught up in the excitement around DALL·E2 (latest and greatest AI system, it’s INSANE), I searched for any way I could use similar image generation for music synchronization. Since DALL·E2 is not available to the public yet, my search led me to VQGAN + CLIP (Vector Quantized Generative Adversarial Network and Contrastive Language–Image Pre-training), before settling more specifically on Disco Diffusion V5.2 Turbo. If you don’t know what any of these words or acronyms mean, don’t worry, I was just as confused when I first started learning about this technology. I believe we’re reaching a turning point where entire industries are about to shift in reaction to this new process (which is essentially magic!).
DoodleChaos”
-
Interactive Maps of Earthquakes around the world
Read more: Interactive Maps of Earthquakes around the worldhttps://ralucanicola.github.io/JSAPI_demos/earthquakes
https://ralucanicola.github.io/JSAPI_demos/earthquakes-depth
https://ralucanicola.github.io/JSAPI_demos/ridgecrest-earthquake
https://ralucanicola.github.io/JSAPI_demos/last-earthquakes














COLOR
-
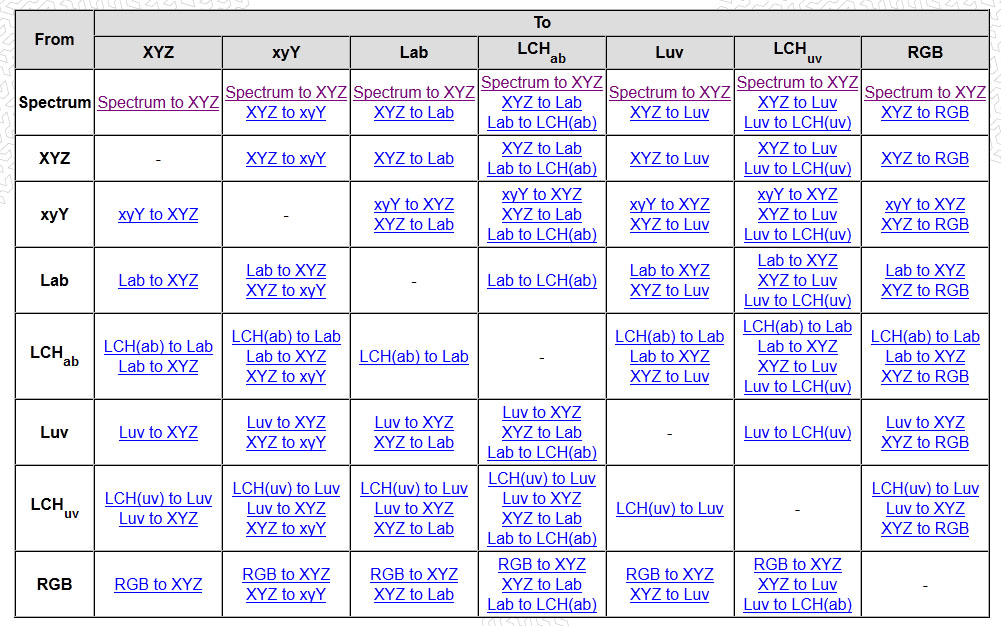
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.


















LIGHTING
-
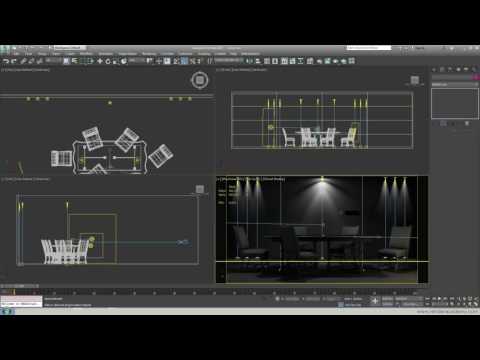
IES Light Profiles and editing software
Read more: IES Light Profiles and editing softwarehttp://www.derekjenson.com/3d-blog/ies-light-profiles
https://ieslibrary.com/en/browse#ies
https://leomoon.com/store/shaders/ies-lights-pack
https://docs.arnoldrenderer.com/display/a5afmug/ai+photometric+light
IES profiles are useful for creating life-like lighting, as they can represent the physical distribution of light from any light source.
The IES format was created by the Illumination Engineering Society, and most lighting manufacturers provide IES profile for the lights they manufacture.


-
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.

-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning














COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Types of AI Explained in a few Minutes – AI Glossary
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
-
Cinematographers Blueprint 300dpi poster
-
HDRI Median Cut plugin
-
The CG Career YouTube channel is live!
-
Want to build a start up company that lasts? Think three-layer cake
-
What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
-
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
