


COMPOSITION
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
What type of lighting?-> High key lighting.
Features bright, even illumination and few conspicuous shadows. This lighting key is often used in musicals and comedies.Low key lighting
Features diffused shadows and atmospheric pools of light. This lighting key is often used in mysteries and thrillers.High contrast lighting
Features harsh shafts of lights and dramatic streaks of blackness. This type of lighting is often used in tragedies and melodramas.What type of shot?
Extreme long shot
Taken from a great distance, showing much of the locale. Ifpeople are included in these shots, they usually appear as mere specks-> Long shot
Corresponds to the space between the audience and the stage in a live theater. The long shots show the characters and some of the locale.Full shot
Range with just enough space to contain the human body in full. The full shot shows the character and a minimal amount of the locale.Medium shot
Shows the human figure from the knees or waist up.Close-Up
Concentrates on a relatively small object and show very little if any locale.Extreme close-up
Focuses on an unnaturally small portion of an object, giving that part great detail and symbolic significance.What angle?
Bird’s-eye view.
The shot is photographed directly from above. This type of shot can be disorienting, and the people photographed seem insignificant.High angle.
This angle reduces the size of the objects photographed. A person photographed from this angle seems harmless and insignificant, but to a lesser extent than with the bird’s-eye view.-> Eye-level shot.
The clearest view of an object, but seldom intrinsically dramatic, because it tends to be the norm.Low angle.
This angle increases high and a sense of verticality, heightening the importance of the object photographed. A person shot from this angle is given a sense of power and respect.Oblique angle.
For this angle, the camera is tilted laterally, giving the image a slanted appearance. Oblique angles suggest tension, transition, a impending movement. They are also called canted or dutch angles.What is the dominant color?
The use of color in this shot is symbolic. The scene is set in warehouse. Both the set and characters are blues, blacks and whites.
This was intentional allowing for the scenes and shots with blood to have a great level of contrast.
What is the Lens/Filter/Stock?
Telephoto lens.
A lens that draws objects closer but also diminishes the illusion of depth.Wide-angle lens.
A lens that takes in a broad area and increases the illusion of depth but sometimes distorts the edges of the image.Fast film stock.
Highly sensitive to light, it can register an image with little illumination. However, the final product tends to be grainy.Slow film stock.
Relatively insensitive to light, it requires a great deal of illumination. The final product tends to look polished.The lens is not wide-angle because there isn’t a great sense of depth, nor are several planes in focus. The lens is probably long but not necessarily a telephoto lens because the depth isn’t inordinately compressed.
The stock is fast because of the grainy quality of the image.
Subsidiary Contrast; where does the eye go next?
The two guns.
How much visual information is packed into the image? Is the texture stark, moderate, or highly detailed?
Minimalist clutter in the warehouse allows a focus on a character driven thriller.
What is the Composition?
Horizontal.
Compositions based on horizontal lines seem visually at rest and suggest placidity or peacefulness.Vertical.
Compositions based on vertical lines seem visually at rest and suggest strength.-> Diagonal.
Compositions based on diagonal, or oblique, lines seem dynamic and suggest tension or anxiety.-> Binary. Binary structures emphasize parallelism.
Triangle.
Triadic compositions stress the dynamic interplay among three mainCircle.
Circular compositions suggest security and enclosure.Is the form open or closed? Does the image suggest a window that arbitrarily isolates a fragment of the scene? Or a proscenium arch, in which the visual elements are carefully arranged and held in balance?
The most nebulous of all the categories of mise en scene, the type of form is determined by how consciously structured the mise en scene is. Open forms stress apparently simple techniques, because with these unself-conscious methods the filmmaker is able to emphasize the immediate, the familiar, the intimate aspects of reality. In open-form images, the frame tends to be deemphasized. In closed form images, all the necessary information is carefully structured within the confines of the frame. Space seems enclosed and self-contained rather than continuous.
Could argue this is a proscenium arch because this is such a classic shot with parallels and juxtapositions.
Is the framing tight or loose? Do the character have no room to move around, or can they move freely without impediments?
Shots where the characters are placed at the edges of the frame and have little room to move around within the frame are considered tight.
Longer shots, in which characters have room to move around within the frame, are considered loose and tend to suggest freedom.
Center-framed giving us the entire scene showing isolation, place and struggle.
Depth of Field. On how many planes is the image composed (how many are in focus)? Does the background or foreground comment in any way on the mid-ground?
Standard DOF, one background and clearly defined foreground.
Which way do the characters look vis-a-vis the camera?
An actor can be photographed in any of five basic positions, each conveying different psychological overtones.
Full-front (facing the camera):
the position with the most intimacy. The character is looking in our direction, inviting our complicity.Quarter Turn:
the favored position of most filmmakers. This position offers a high degree of intimacy but with less emotional involvement than the full-front.-> Profile (looking of the frame left or right):
More remote than the quarter turn, the character in profile seems unaware of being observed, lost in his or her own thoughts.Three-quarter Turn:
More anonymous than the profile, this position is useful for conveying a character’s unfriendly or antisocial feelings, for in effect, the character is partially turning his or her back on us, rejecting our interest.Back to Camera:
The most anonymous of all positions, this position is often used to suggest a character’s alienation from the world. When a character has his or her back to the camera, we can only guess what’s taking place internally, conveying a sense of concealment, or mystery.How much space is there between the characters?
Extremely close, for a gunfight.
The way people use space can be divided into four proxemic patterns.
Intimate distances.
The intimate distance ranges from skin contact to about eighteen inches away. This is the distance of physical involvement–of love, comfort, and tenderness between individuals.-> Personal distances.
The personal distance ranges roughly from eighteen inches away to about four feet away. These distances tend to be reserved for friends and acquaintances. Personal distances preserve the privacy between individuals, yet these rages don’t necessarily suggest exclusion, as intimate distances often do.Social distances.
The social distance rages from four feet to about twelve feet. These distances are usually reserved for impersonal business and casual social gatherings. It’s a friendly range in most cases, yet somewhat more formal than the personal distance.Public distances.
The public distance extends from twelve feet to twenty-five feet or more. This range tends to be formal and rather detached. -
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects














DESIGN











COLOR
-
What is a Gamut or Color Space and why do I need to know about CIE
Read more: What is a Gamut or Color Space and why do I need to know about CIE

http://www.xdcam-user.com/2014/05/what-is-a-gamut-or-color-space-and-why-do-i-need-to-know-about-it/
In video terms gamut is normally related to as the full range of colours and brightness that can be either captured or displayed.
Generally speaking all color gamuts recommendations are trying to define a reasonable level of color representation based on available technology and hardware. REC-601 represents the old TVs. REC-709 is currently the most distributed solution. P3 is mainly available in movie theaters and is now being adopted in some of the best new 4K HDR TVs. Rec2020 (a wider space than P3 that improves on visibke color representation) and ACES (the full coverage of visible color) are other common standards which see major hardware development these days.
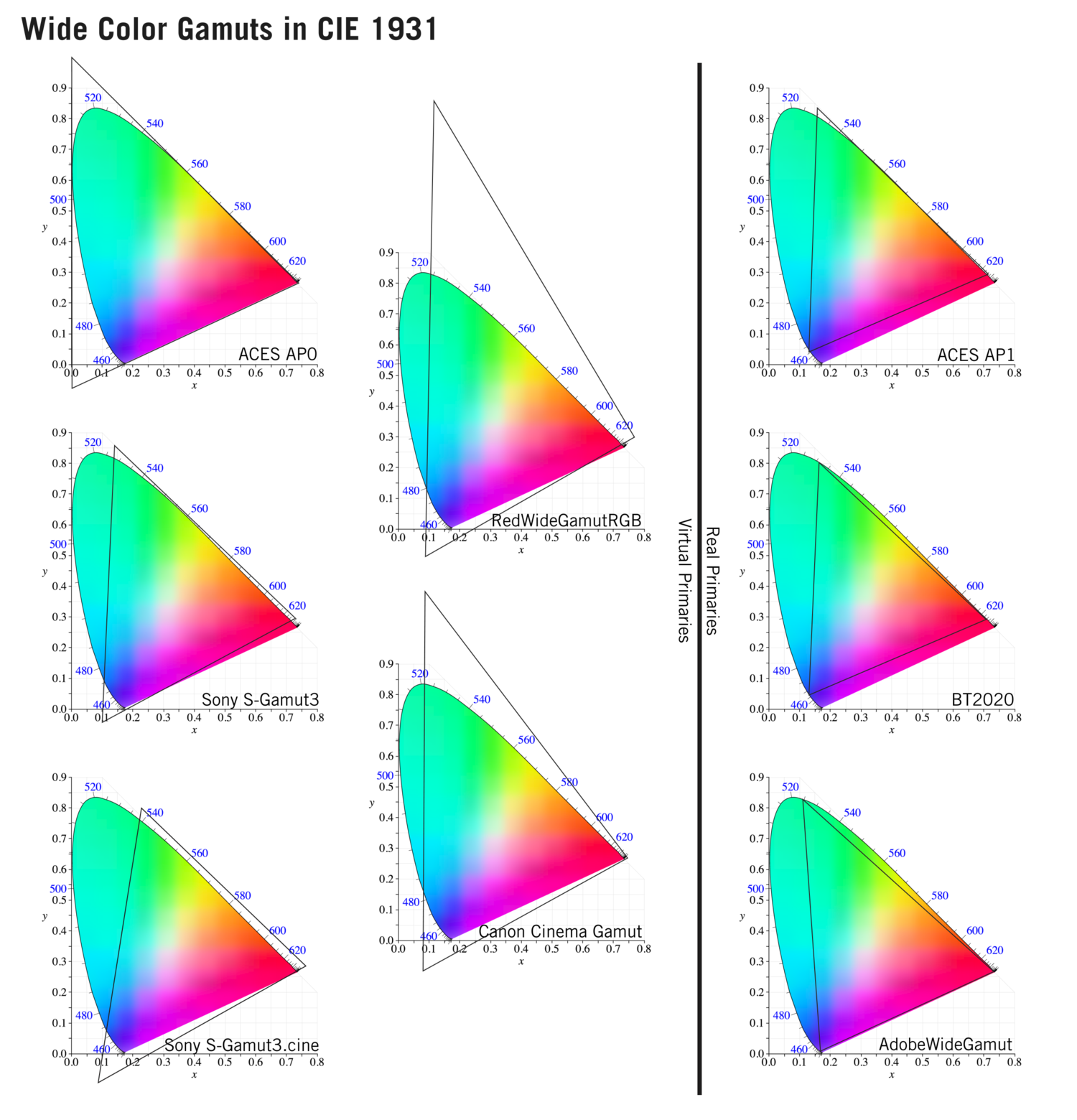
To compare and visualize different solution (across video and printing solutions), most developers use the CIE color model chart as a reference.
The CIE color model is a color space model created by the International Commission on Illumination known as the Commission Internationale de l’Elcairage (CIE) in 1931. It is also known as the CIE XYZ color space or the CIE 1931 XYZ color space.
This chart represents the first defined quantitative link between distributions of wavelengths in the electromagnetic visible spectrum, and physiologically perceived colors in human color vision. Or basically, the range of color a typical human eye can perceive through visible light.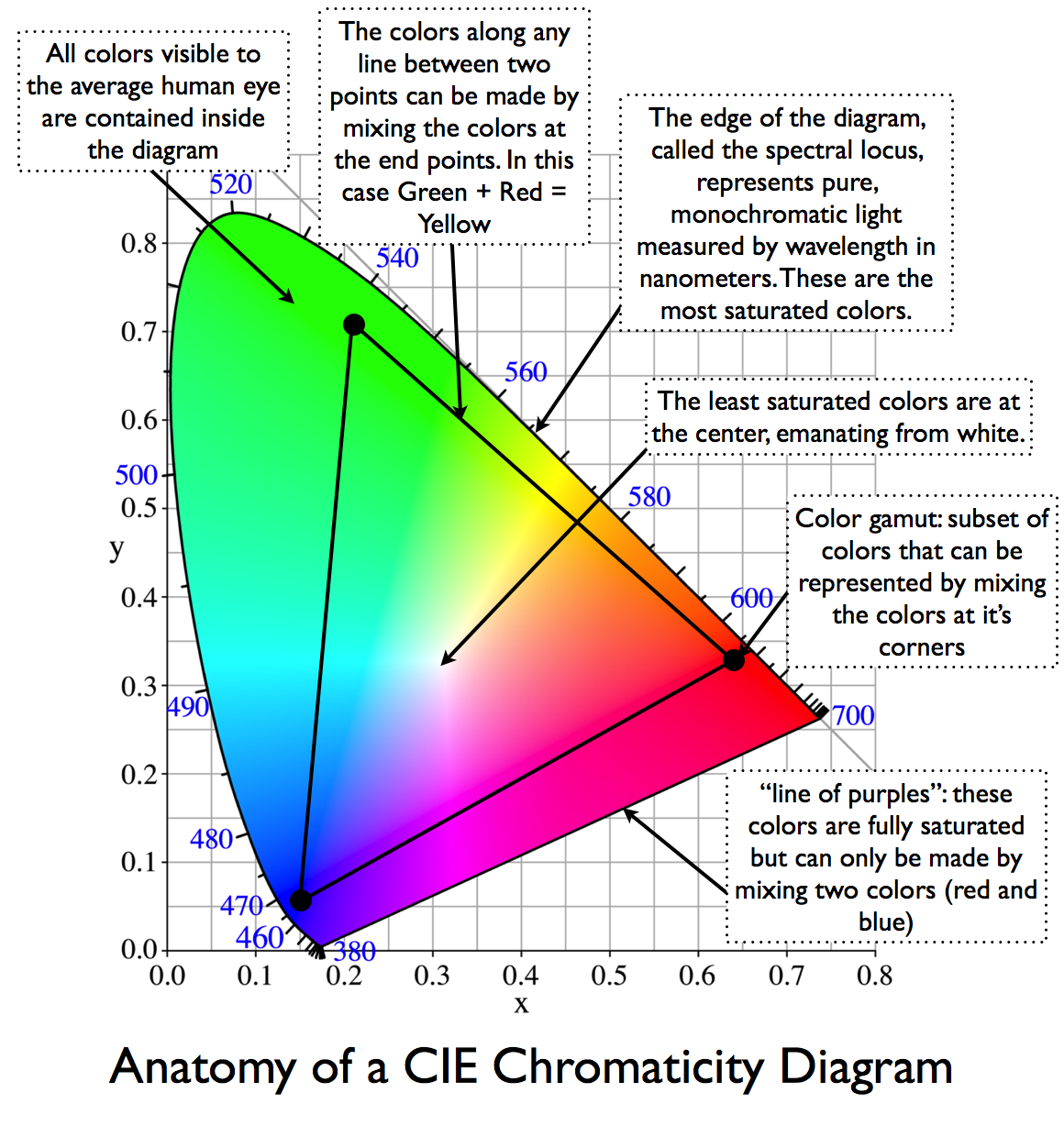
Note that while the human perception is quite wide, and generally speaking biased towards greens (we are apes after all), the amount of colors available through nature, generated through light reflection, tend to be a much smaller section. This is defined by the Pointer’s Chart.
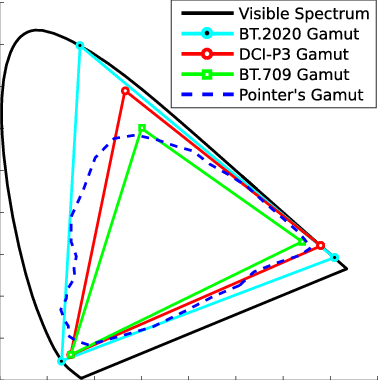

In short. Color gamut is a representation of color coverage, used to describe data stored in images against available hardware and viewer technologies.
Camera color encoding from
https://www.slideshare.net/hpduiker/acescg-a-common-color-encoding-for-visual-effects-applications
CIE 1976
http://bernardsmith.eu/computatrum/scan_and_restore_archive_and_print/scanning/
https://store.yujiintl.com/blogs/high-cri-led/understanding-cie1931-and-cie-1976
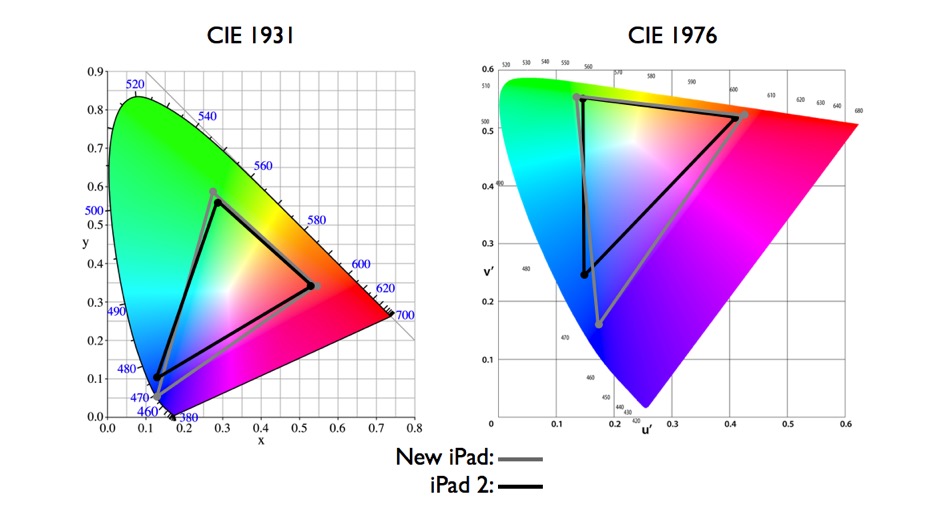
The CIE 1931 standard has been replaced by a CIE 1976 standard. Below we can see the significance of this.
People have observed that the biggest issue with CIE 1931 is the lack of uniformity with chromaticity, the three dimension color space in rectangular coordinates is not visually uniformed.
The CIE 1976 (also called CIELUV) was created by the CIE in 1976. It was put forward in an attempt to provide a more uniform color spacing than CIE 1931 for colors at approximately the same luminance
The CIE 1976 standard colour space is more linear and variations in perceived colour between different people has also been reduced. The disproportionately large green-turquoise area in CIE 1931, which cannot be generated with existing computer screens, has been reduced.
If we move from CIE 1931 to the CIE 1976 standard colour space we can see that the improvements made in the gamut for the “new” iPad screen (as compared to the “old” iPad 2) are more evident in the CIE 1976 colour space than in the CIE 1931 colour space, particularly in the blues from aqua to deep blue.
https://dot-color.com/2012/08/14/color-space-confusion/
Despite its age, CIE 1931, named for the year of its adoption, remains a well-worn and familiar shorthand throughout the display industry. CIE 1931 is the primary language of customers. When a customer says that their current display “can do 72% of NTSC,” they implicitly mean 72% of NTSC 1953 color gamut as mapped against CIE 1931.
-
Polarised vs unpolarized filtering
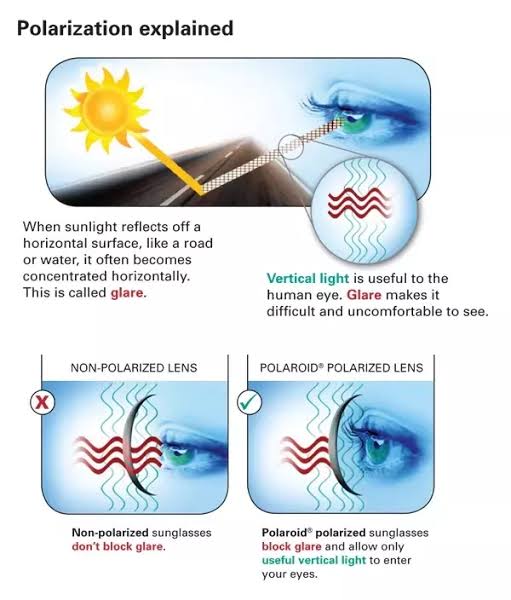
Read more: Polarised vs unpolarized filteringA light wave that is vibrating in more than one plane is referred to as unpolarized light. …
Polarized light waves are light waves in which the vibrations occur in a single plane. The process of transforming unpolarized light into polarized light is known as polarization.

en.wikipedia.org/wiki/Polarizing_filter_(photography)
The most common use of polarized technology is to reduce lighting complexity on the subject.
Details such as glare and hard edges are not removed, but greatly reduced.This method is usually used in VFX to capture raw images with the least amount of specular diffusion or pollution, thus allowing artists to infer detail back through typical shading and rendering techniques and on demand.
Light reflected from a non-metallic surface becomes polarized; this effect is maximum at Brewster’s angle, about 56° from the vertical for common glass.
A polarizer rotated to pass only light polarized in the direction perpendicular to the reflected light will absorb much of it. This absorption allows glare reflected from, for example, a body of water or a road to be reduced. Reflections from shiny surfaces (e.g. vegetation, sweaty skin, water surfaces, glass) are also reduced. This allows the natural color and detail of what is beneath to come through. Reflections from a window into a dark interior can be much reduced, allowing it to be seen through. (The same effects are available for vision by using polarizing sunglasses.)

www.physicsclassroom.com/class/light/u12l1e.cfm
Some of the light coming from the sky is polarized (bees use this phenomenon for navigation). The electrons in the air molecules cause a scattering of sunlight in all directions. This explains why the sky is not dark during the day. But when looked at from the sides, the light emitted from a specific electron is totally polarized.[3] Hence, a picture taken in a direction at 90 degrees from the sun can take advantage of this polarization.

Use of a polarizing filter, in the correct direction, will filter out the polarized component of skylight, darkening the sky; the landscape below it, and clouds, will be less affected, giving a photograph with a darker and more dramatic sky, and emphasizing the clouds.

There are two types of polarizing filters readily available, linear and “circular”, which have exactly the same effect photographically. But the metering and auto-focus sensors in certain cameras, including virtually all auto-focus SLRs, will not work properly with linear polarizers because the beam splitters used to split off the light for focusing and metering are polarization-dependent.
Polarizing filters reduce the light passed through to the film or sensor by about one to three stops (2–8×) depending on how much of the light is polarized at the filter angle selected. Auto-exposure cameras will adjust for this by widening the aperture, lengthening the time the shutter is open, and/or increasing the ASA/ISO speed of the camera.
www.adorama.com/alc/nd-filter-vs-polarizer-what%25e2%2580%2599s-the-difference
Neutral Density (ND) filters help control image exposure by reducing the light that enters the camera so that you can have more control of your depth of field and shutter speed. Polarizers or polarizing filters work in a similar way, but the difference is that they selectively let light waves of a certain polarization pass through. This effect helps create more vivid colors in an image, as well as manage glare and reflections from water surfaces. Both are regarded as some of the best filters for landscape and travel photography as they reduce the dynamic range in high-contrast images, thus enabling photographers to capture more realistic and dramatic sceneries.
shopfelixgray.com/blog/polarized-vs-non-polarized-sunglasses/
www.eyebuydirect.com/blog/difference-polarized-nonpolarized-sunglasses/
-
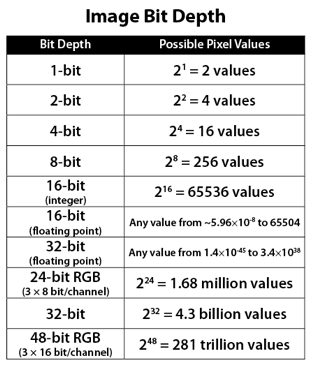
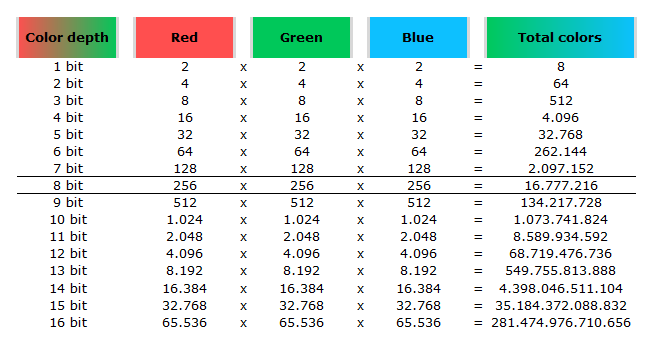
Image rendering bit depth
Read more: Image rendering bit depthThe terms 8-bit, 16-bit, 16-bit float, and 32-bit refer to different data formats used to store and represent image information, as bits per pixel.
https://en.wikipedia.org/wiki/Color_depth
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.

Here’s a simple explanation of each.
8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.16-bit: This format is commonly referred to as “half-precision.” It uses 16 bits of data to represent color values for each pixel. With 16 bits, you can have 65,536 discrete levels of color, allowing for relatively high precision and smooth gradients. However, it has a limited dynamic range, meaning it cannot accurately represent extremely bright or dark values. It is commonly used for regular images and textures.
16-bit float: This format is an extension of the 16-bit format but uses floating-point numbers instead of fixed integers. Floating-point numbers allow for more precise calculations and a larger dynamic range. In this case, the 16 bits are used to store both the color value and the exponent, which controls the range of values that can be represented. The 16-bit float format provides better accuracy and a wider dynamic range than regular 16-bit, making it useful for high-dynamic-range imaging (HDRI) and computations that require more precision.
32-bit: (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range. This format, also known as “full-precision” or “float,” uses 32 bits to represent color values and offers the highest precision and dynamic range among the three options. With 32 bits, you have a significantly larger number of discrete levels, allowing for extremely accurate color representation, smooth gradients, and a wide range of brightness values. It is commonly used for professional rendering, visual effects, and scientific applications where maximum precision is required.
Bits and HDR coverage
High Dynamic Range (HDR) images are designed to capture a wide range of luminance values, from the darkest shadows to the brightest highlights, in order to reproduce a scene with more accuracy and detail. The bit depth of an image refers to the number of bits used to represent each pixel’s color information. When comparing 32-bit float and 16-bit float HDR images, the drop in accuracy primarily relates to the precision of the color information.
A 32-bit float HDR image offers a higher level of precision compared to a 16-bit float HDR image. In a 32-bit float format, each color channel (red, green, and blue) is represented by 32 bits, allowing for a larger range of values to be stored. This increased precision enables the image to retain more details and subtleties in color and luminance.
On the other hand, a 16-bit float HDR image utilizes 16 bits per color channel, resulting in a reduced range of values that can be represented. This lower precision leads to a loss of fine details and color nuances, especially in highly contrasted areas of the image where there are significant differences in luminance.
The drop in accuracy between 32-bit and 16-bit float HDR images becomes more noticeable as the exposure range of the scene increases. Exposure range refers to the span between the darkest and brightest areas of an image. In scenes with a limited exposure range, where the luminance differences are relatively small, the loss of accuracy may not be as prominent or perceptible. These images usually are around 8-10 exposure levels.
However, in scenes with a wide exposure range, such as a landscape with deep shadows and bright highlights, the reduced precision of a 16-bit float HDR image can result in visible artifacts like color banding, posterization, and loss of detail in both shadows and highlights. The image may exhibit abrupt transitions between tones or colors, which can appear unnatural and less realistic.
To provide a rough estimate, it is often observed that exposure values beyond approximately ±6 to ±8 stops from the middle gray (18% reflectance) may be more prone to accuracy issues in a 16-bit float format. This range may vary depending on the specific implementation and encoding scheme used.
To summarize, the drop in accuracy between 32-bit and 16-bit float HDR images is mainly related to the reduced precision of color information. This decrease in precision becomes more apparent in scenes with a wide exposure range, affecting the representation of fine details and leading to visible artifacts in the image.
In practice, this means that exposure values beyond a certain range will experience a loss of accuracy and detail when stored in a 16-bit float format. The exact range at which this loss occurs depends on the encoding scheme and the specific implementation. However, in general, extremely bright or extremely dark values that fall outside the representable range may be subject to quantization errors, resulting in loss of detail, banding, or other artifacts.
HDRs used for lighting purposes are usually slightly convolved to improve on sampling speed and removing specular artefacts. To that extent, 16 bit float HDRIs tend to me most used in CG cycles.

-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
Read more: Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminancehttps://www.translatorscafe.com/unit-converter/en-US/illumination/1-11/

The power output of a light source is measured using the unit of watts W. This is a direct measure to calculate how much power the light is going to drain from your socket and it is not relatable to the light brightness itself.
The amount of energy emitted from it per second. That energy comes out in a form of photons which we can crudely represent with rays of light coming out of the source. The higher the power the more rays emitted from the source in a unit of time.
Not all energy emitted is visible to the human eye, so we often rely on photometric measurements, which takes in account the sensitivity of human eye to different wavelenghts


Details in the post
(more…) -
Is it possible to get a dark yellow
Read more: Is it possible to get a dark yellowhttps://www.patreon.com/posts/102660674
https://www.linkedin.com/posts/stephenwestland_here-is-a-post-about-the-dark-yellow-problem-activity-7187131643764092929-7uCL



-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.

-
No one could see the colour blue until modern times
Read more: No one could see the colour blue until modern timeshttps://www.businessinsider.com/what-is-blue-and-how-do-we-see-color-2015-2

The way that humans see the world… until we have a way to describe something, even something so fundamental as a colour, we may not even notice that something it’s there.
Ancient languages didn’t have a word for blue — not Greek, not Chinese, not Japanese, not Hebrew, not Icelandic cultures. And without a word for the colour, there’s evidence that they may not have seen it at all.
https://www.wnycstudios.org/story/211119-colors
Every language first had a word for black and for white, or dark and light. The next word for a colour to come into existence — in every language studied around the world — was red, the colour of blood and wine.
After red, historically, yellow appears, and later, green (though in a couple of languages, yellow and green switch places). The last of these colours to appear in every language is blue.
The only ancient culture to develop a word for blue was the Egyptians — and as it happens, they were also the only culture that had a way to produce a blue dye.
https://mymodernmet.com/shades-of-blue-color-history/
Considered to be the first ever synthetically produced color pigment, Egyptian blue (also known as cuprorivaite) was created around 2,200 B.C. It was made from ground limestone mixed with sand and a copper-containing mineral, such as azurite or malachite, which was then heated between 1470 and 1650°F. The result was an opaque blue glass which then had to be crushed and combined with thickening agents such as egg whites to create a long-lasting paint or glaze.

If you think about it, blue doesn’t appear much in nature — there aren’t animals with blue pigments (except for one butterfly, Obrina Olivewing, all animals generate blue through light scattering), blue eyes are rare (also blue through light scattering), and blue flowers are mostly human creations. There is, of course, the sky, but is that really blue?

So before we had a word for it, did people not naturally see blue? Do you really see something if you don’t have a word for it?
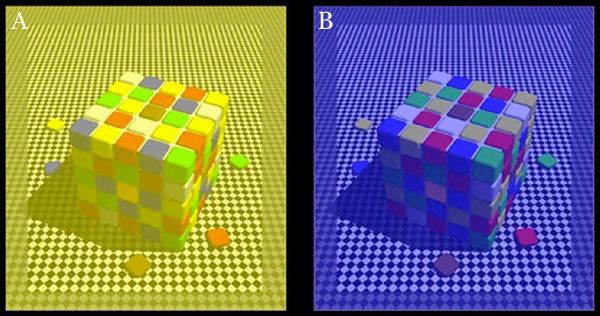
A researcher named Jules Davidoff traveled to Namibia to investigate this, where he conducted an experiment with the Himba tribe, who speak a language that has no word for blue or distinction between blue and green. When shown a circle with 11 green squares and one blue, they couldn’t pick out which one was different from the others.
When looking at a circle of green squares with only one slightly different shade, they could immediately spot the different one. Can you?


Davidoff says that without a word for a colour, without a way of identifying it as different, it’s much harder for us to notice what’s unique about it — even though our eyes are physically seeing the blocks it in the same way.
Further research brought to wider discussions about color perception in humans. Everything that we make is based on the fact that humans are trichromatic. The television only has 3 colors. Our color printers have 3 different colors. But some people, and in specific some women seemed to be more sensible to color differences… mainly because they’re just more aware or – because of the job that they do.
Eventually this brought to the discovery of a small percentage of the population, referred to as tetrachromats, which developed an extra cone sensitivity to yellow, likely due to gene modifications.
The interesting detail about these is that even between tetrachromats, only the ones that had a reason to develop, label and work with extra color sensitivity actually developed the ability to use their native skills.
So before blue became a common concept, maybe humans saw it. But it seems they didn’t know they were seeing it.
If you see something yet can’t see it, does it exist? Did colours come into existence over time? Not technically, but our ability to notice them… may have…







LIGHTING
-
Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmic
Read more: Light and Matter : The 2018 theory of Physically-Based Rendering and Shading by Allegorithmicacademy.substance3d.com/courses/the-pbr-guide-part-1
academy.substance3d.com/courses/the-pbr-guide-part-2

 Local copy:
Local copy:
-
Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurements
Read more: Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurementsAlso see: https://www.pixelsham.com/2015/05/16/how-aperture-shutter-speed-and-iso-affect-your-photos/
In photography, exposure value (EV) is a number that represents a combination of a camera’s shutter speed and f-number, such that all combinations that yield the same exposure have the same EV (for any fixed scene luminance).

The EV concept was developed in an attempt to simplify choosing among combinations of equivalent camera settings. Although all camera settings with the same EV nominally give the same exposure, they do not necessarily give the same picture. EV is also used to indicate an interval on the photographic exposure scale. 1 EV corresponding to a standard power-of-2 exposure step, commonly referred to as a stop
EV 0 corresponds to an exposure time of 1 sec and a relative aperture of f/1.0. If the EV is known, it can be used to select combinations of exposure time and f-number.
Note EV does not equal to photographic exposure. Photographic Exposure is defined as how much light hits the camera’s sensor. It depends on the camera settings mainly aperture and shutter speed. Exposure value (known as EV) is a number that represents the exposure setting of the camera.
Thus, strictly, EV is not a measure of luminance (indirect or reflected exposure) or illuminance (incidental exposure); rather, an EV corresponds to a luminance (or illuminance) for which a camera with a given ISO speed would use the indicated EV to obtain the nominally correct exposure. Nonetheless, it is common practice among photographic equipment manufacturers to express luminance in EV for ISO 100 speed, as when specifying metering range or autofocus sensitivity.
The exposure depends on two things: how much light gets through the lenses to the camera’s sensor and for how long the sensor is exposed. The former is a function of the aperture value while the latter is a function of the shutter speed. Exposure value is a number that represents this potential amount of light that could hit the sensor. It is important to understand that exposure value is a measure of how exposed the sensor is to light and not a measure of how much light actually hits the sensor. The exposure value is independent of how lit the scene is. For example a pair of aperture value and shutter speed represents the same exposure value both if the camera is used during a very bright day or during a dark night.
Each exposure value number represents all the possible shutter and aperture settings that result in the same exposure. Although the exposure value is the same for different combinations of aperture values and shutter speeds the resulting photo can be very different (the aperture controls the depth of field while shutter speed controls how much motion is captured).
EV 0.0 is defined as the exposure when setting the aperture to f-number 1.0 and the shutter speed to 1 second. All other exposure values are relative to that number. Exposure values are on a base two logarithmic scale. This means that every single step of EV – plus or minus 1 – represents the exposure (actual light that hits the sensor) being halved or doubled.
https://www.streetdirectory.com/travel_guide/141307/photography/exposure_value_ev_and_exposure_compensation.html
Formula
https://en.wikipedia.org/wiki/Exposure_value
https://www.scantips.com/lights/math.html
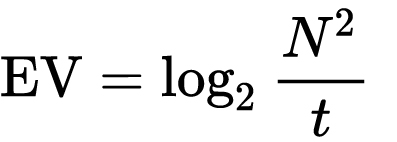
which means 2EV = N² / t
where
- N is the relative aperture (f-number) Important: Note that f/stop values must first be squared in most calculations
- t is the exposure time (shutter speed) in seconds
EV 0 corresponds to an exposure time of 1 sec and an aperture of f/1.0.
Example: If f/16 and 1/4 second, then this is:
(N² / t) = (16 × 16 ÷ 1/4) = (16 × 16 × 4) = 1024.
Log₂(1024) is EV 10. Meaning, 210 = 1024.
Collecting photographic exposure using Light Meters
The exposure meter in the camera does not know whether the subject itself is bright or not. It simply measures the amount of light that comes in, and makes a guess based on that. The camera will aim for 18% gray, meaning if you take a photo of an entirely white surface, and an entirely black surface you should get two identical images which both are gray (at least in theory)
https://en.wikipedia.org/wiki/Light_meter
For reflected-light meters, camera settings are related to ISO speed and subject luminance by the reflected-light exposure equation:
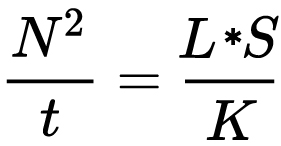
where
- N is the relative aperture (f-number)
- t is the exposure time (“shutter speed”) in seconds
- L is the average scene luminance
- S is the ISO arithmetic speed
- K is the reflected-light meter calibration constant
For incident-light meters, camera settings are related to ISO speed and subject illuminance by the incident-light exposure equation:
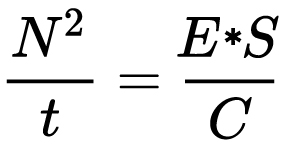
where
- E is the illuminance (in lux)
- C is the incident-light meter calibration constant
Two values for K are in common use: 12.5 (Canon, Nikon, and Sekonic) and 14 (Minolta, Kenko, and Pentax); the difference between the two values is approximately 1/6 EV.
For C a value of 250 is commonly used.Nonetheless, it is common practice among photographic equipment manufacturers to also express luminance in EV for ISO 100 speed. Using K = 12.5, the relationship between EV at ISO 100 and luminance L is then :
L = 2(EV-3)
The situation with incident-light meters is more complicated than that for reflected-light meters, because the calibration constant C depends on the sensor type. Illuminance is measured with a flat sensor; a typical value for C is 250 with illuminance in lux. Using C = 250, the relationship between EV at ISO 100 and illuminance E is then :
E = 2.5 * 2(EV)
https://nofilmschool.com/2018/03/want-easier-and-faster-way-calculate-exposure-formula
Three basic factors go into the exposure formula itself instead: aperture, shutter, and ISO. Plus a light meter calibration constant.
f-stop²/shutter (in seconds) = lux * ISO/C
If you at least know four of those variables, you’ll be able to calculate the missing value.
So, say you want to figure out how much light you’re going to need in order to shoot at a certain f-stop. Well, all you do is plug in your values (you should know the f-stop, ISO, and your light meter calibration constant) into the formula below:
lux = C (f-stop²/shutter (in seconds))/ISO
Exposure Value Calculator:
https://snapheadshots.com/resources/exposure-and-light-calculator
https://www.scantips.com/lights/exposurecalc.html
https://www.pointsinfocus.com/tools/exposure-settings-ev-calculator/#google_vignette
From that perspective, an exposure stop is a measurement of Exposure and provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso & f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo.
1 EV is just another way to say one stop of exposure change.One major use of EV (Exposure Value) is just to measure any change of exposure, where one EV implies a change of one stop of exposure. Like when we compensate our picture in the camera.
If the picture comes out too dark, our manual exposure could correct the next one by directly adjusting one of the three exposure controls (f/stop, shutter speed, or ISO). Or if using camera automation, the camera meter is controlling it, but we might apply +1 EV exposure compensation (or +1 EV flash compensation) to make the result goal brighter, as desired. This use of 1 EV is just another way to say one stop of exposure change.
On a perfect day the difference from sampling the sky vs the sun exposure with diffusing spot meters is about 3.2 exposure difference.
~15.4 EV for the sun ~12.2 EV for the sky
That is as a ballpark. All still influenced by surroundings, accuracy parameters, fov of the sensor…
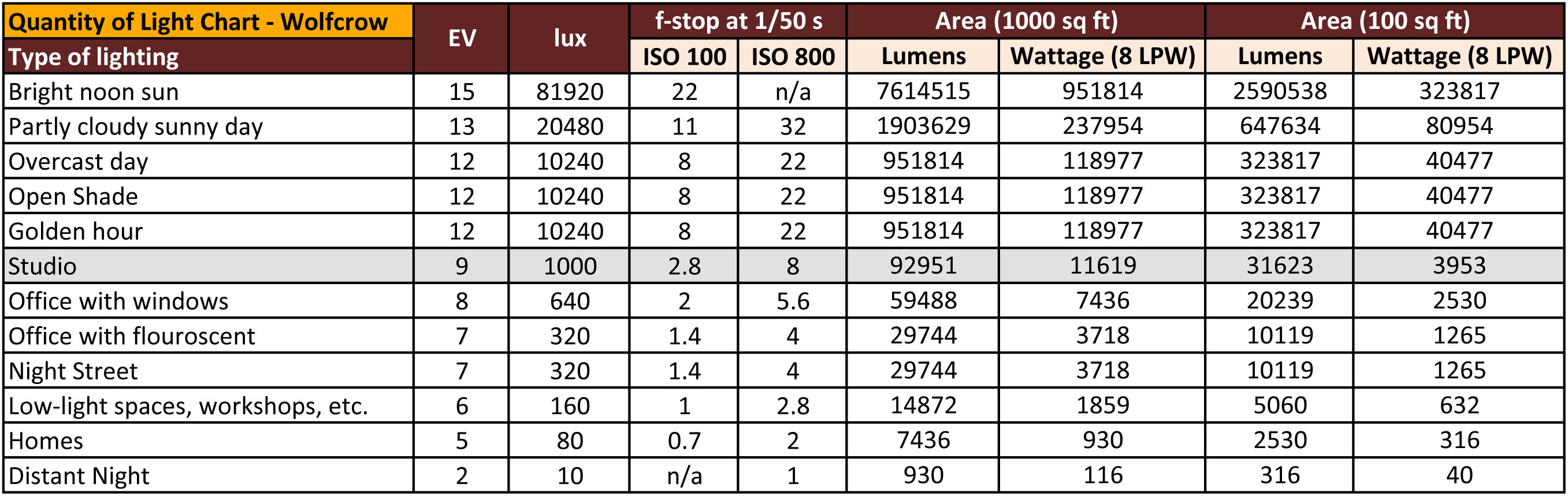
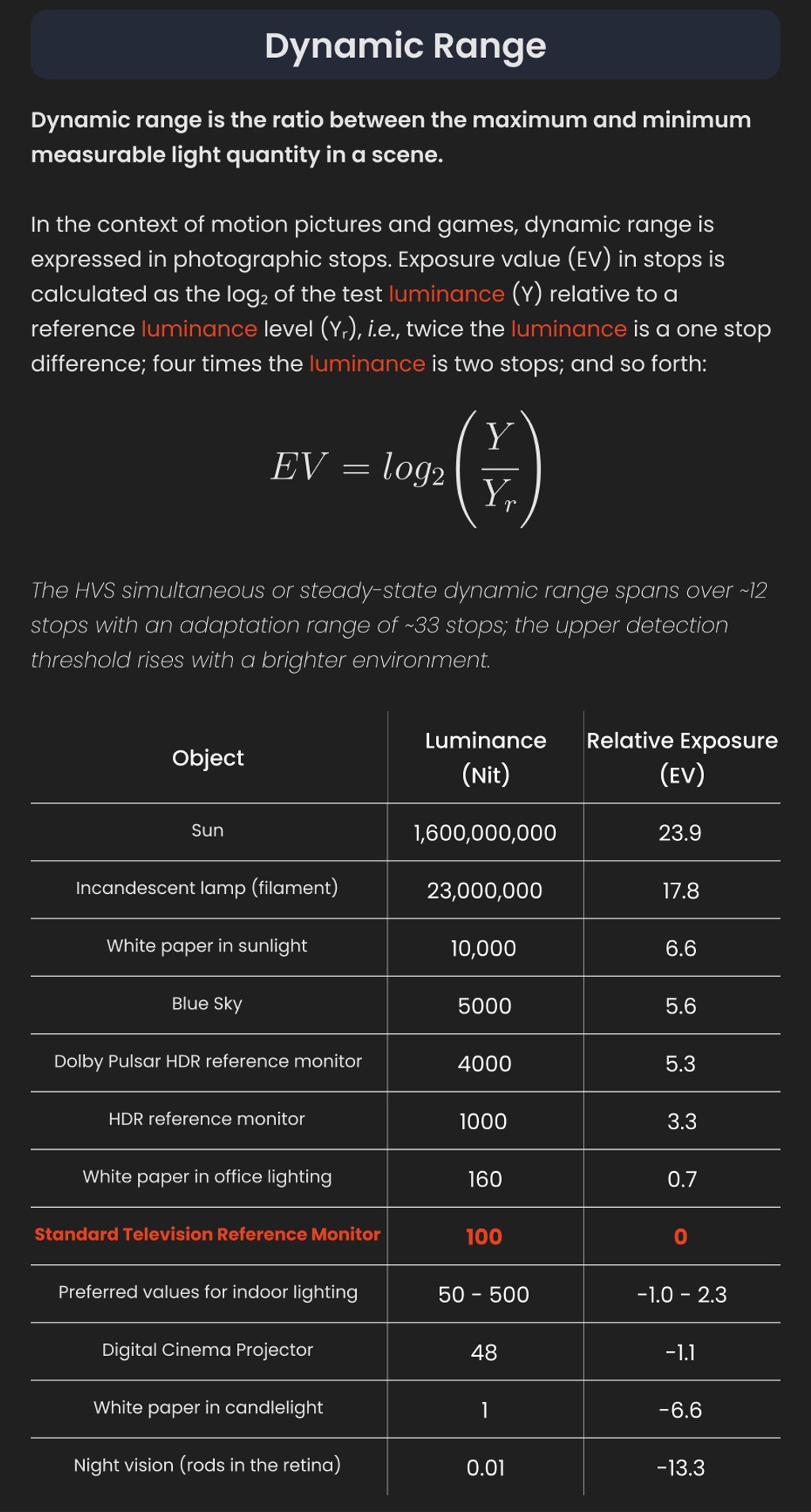
EV calculator
https://www.scantips.com/lights/evchart.html#calc
http://www.fredparker.com/ultexp1.htm
Exposure value is basically used to indicate an interval on the photographic exposure scale, with a difference of 1 EV corresponding to a standard power-of-2 exposure step, also commonly referred to as a “stop”.
https://contrastly.com/a-guide-to-understanding-exposure-value-ev/
Retrieving photographic exposure from an image
All you can hope to measure with your camera and some images is the relative reflected luminance. Even if you have the camera settings. https://en.wikipedia.org/wiki/Relative_luminance
If you REALLY want to know the amount of light in absolute radiometric units, you’re going to need to use some kind of absolute light meter or measured light source to calibrate your camera. For references on how to do this, see: Section 2.5 Obtaining Absolute Radiance from http://www.pauldebevec.com/Research/HDR/debevec-siggraph97.pdf
IF you are still trying to gauge relative brightness, the level of the sun in Nuke can vary, but it should be in the thousands. Ie: between 30,000 and 65,0000 rgb value depending on time of the day, season and atmospherics.
The values for a 12 o’clock sun, with the sun sampled at EV 15.5 (shutter 1/30, ISO 100, F22) is 32.000 RGB max values (or 32,000 pixel luminance).
The thing to keep an eye for is the level of contrast between sunny side/fill side. The terminator should be quite obvious, there can be up to 3 stops difference between fill/key in sunny lit objects.Note: In Foundry’s Nuke, the software will map 18% gray to whatever your center f/stop is set to in the viewer settings (f/8 by default… change that to EV by following the instructions below).
You can experiment with this by attaching an Exposure node to a Constant set to 0.18, setting your viewer read-out to Spotmeter, and adjusting the stops in the node up and down. You will see that a full stop up or down will give you the respective next value on the aperture scale (f8, f11, f16 etc.).
One stop doubles or halves the amount or light that hits the filmback/ccd, so everything works in powers of 2.
So starting with 0.18 in your constant, you will see that raising it by a stop will give you .36 as a floating point number (in linear space), while your f/stop will be f/11 and so on.If you set your center stop to 0 (see below) you will get a relative readout in EVs, where EV 0 again equals 18% constant gray.
Note: make sure to set your Nuke read node to ‘raw data’
In other words. Setting the center f-stop to 0 means that in a neutral plate, the middle gray in the macbeth chart will equal to exposure value 0. EV 0 corresponds to an exposure time of 1 sec and an aperture of f/1.0.
To switch Foundry’s Nuke’s SpotMeter to return the EV of an image, click on the main viewport, and then press s, this opens the viewer’s properties. Now set the center f-stop to 0 in there. And the SpotMeter in the viewport will change from aperture and fstops to EV.
If you are trying to gauge the EV from the pixel luminance in the image:
– Setting the center f-stop to 0 means that in a neutral plate, the middle 18% gray will equal to exposure value 0.
– So if EV 0 = 0.18 middle gray in nuke which equal to a pixel luminance of 0.18, doubling that value, doubles the EV..18 pixel luminance = 0EV .36 pixel luminance = 1EV .72 pixel luminance = 2EV 1.46 pixel luminance = 3EV ...
This is a Geometric Progression function: xn = ar(n-1)
The most basic example of this function is 1,2,4,8,16,32,… The sequence starts at 1 and doubles each time, so
- a=1 (the first term)
- r=2 (the “common ratio” between terms is a doubling)
And we get:
{a, ar, ar2, ar3, … }
= {1, 1×2, 1×22, 1×23, … }
= {1, 2, 4, 8, … }
In this example the function translates to: n = 2(n-1)
You can graph this curve through this expression: x = 2(y-1) :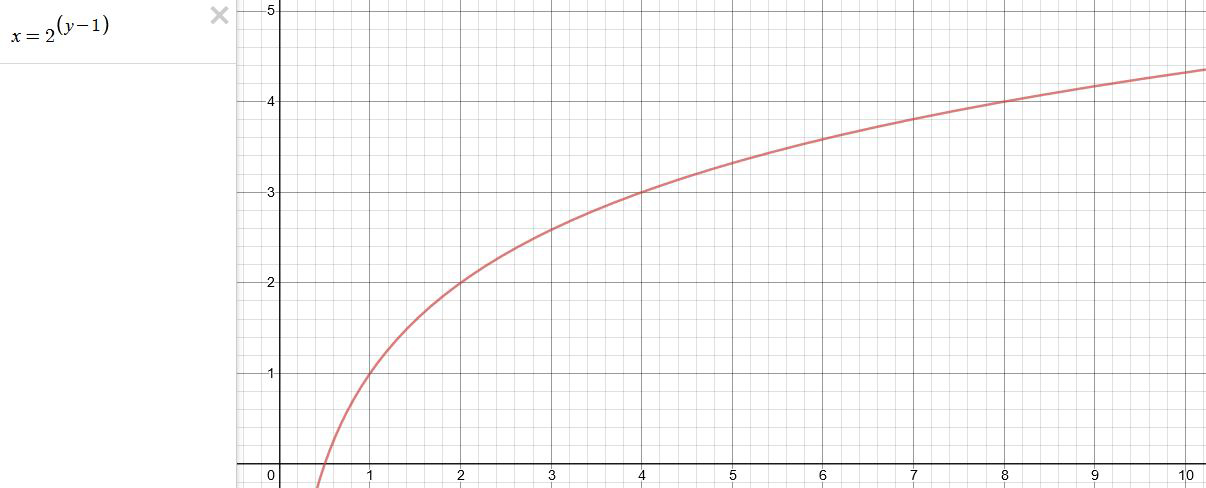
You can go back and forth between the two values through a geometric progression function and a log function:
(Note: in a spreadsheet this is: = POWER(2; cell# -1) and =LOG(cell#, 2)+1) )
2(y-1) log2(x)+1 x y 1 1 2 2 4 3 8 4 16 5 32 6 64 7 128 8 256 9 512 10 1024 11 2048 12 4096 13 Translating this into a geometric progression between an image pixel luminance and EV:
-
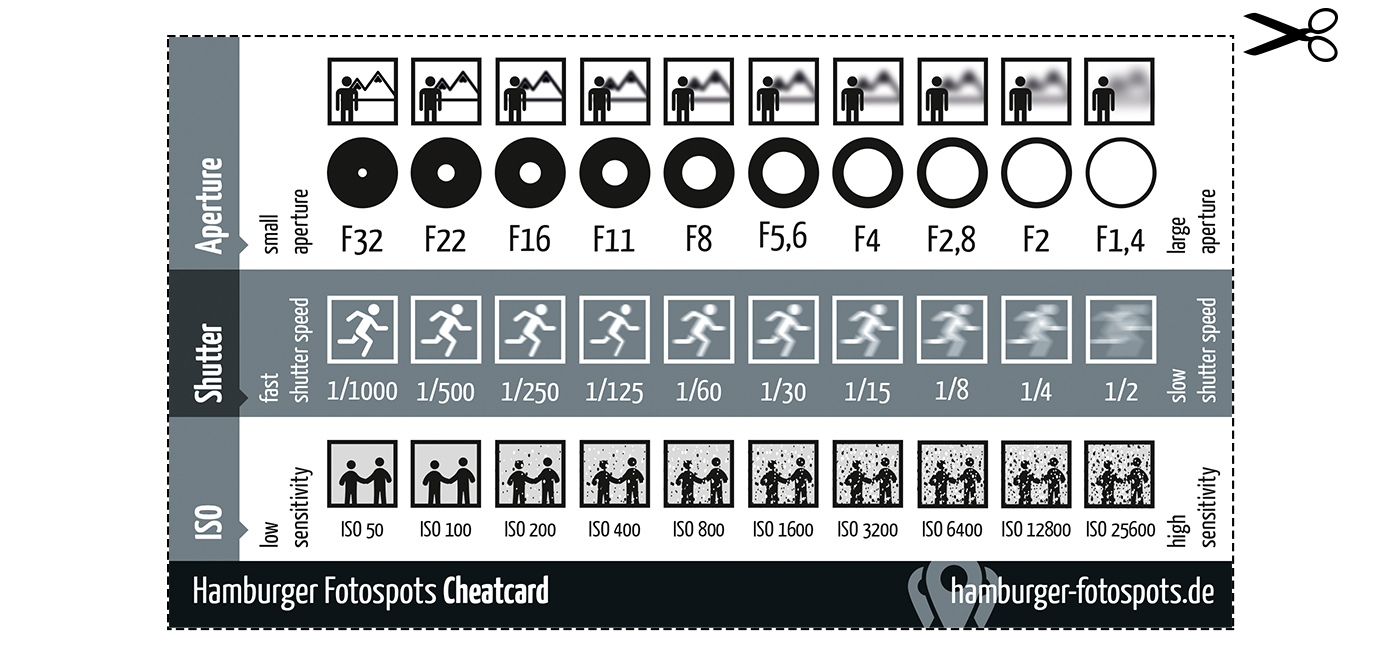
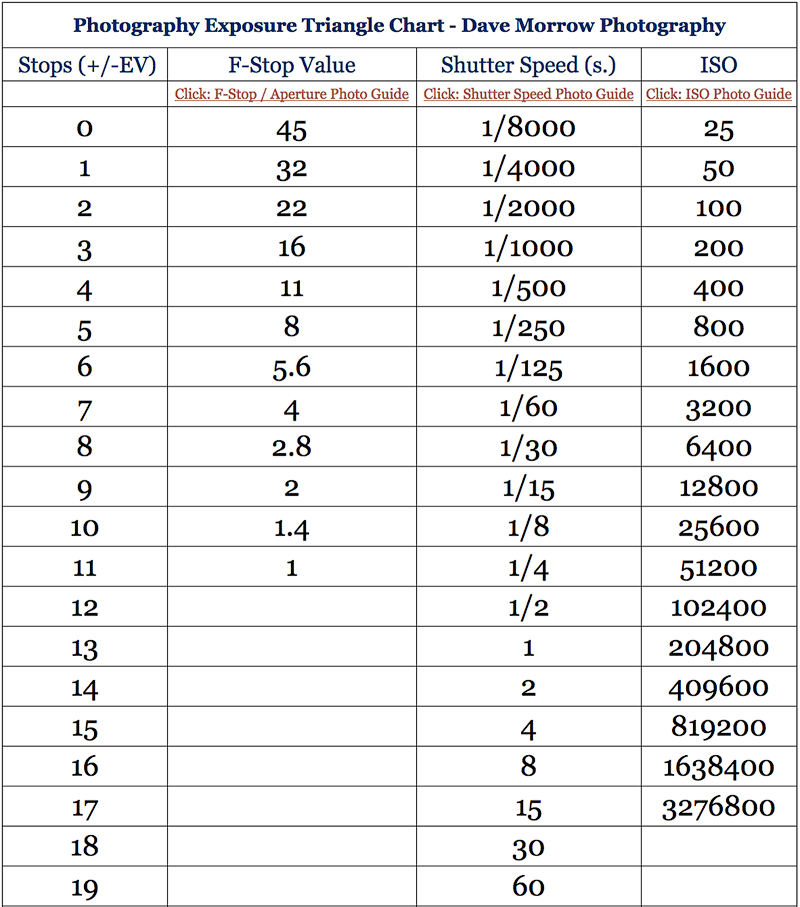
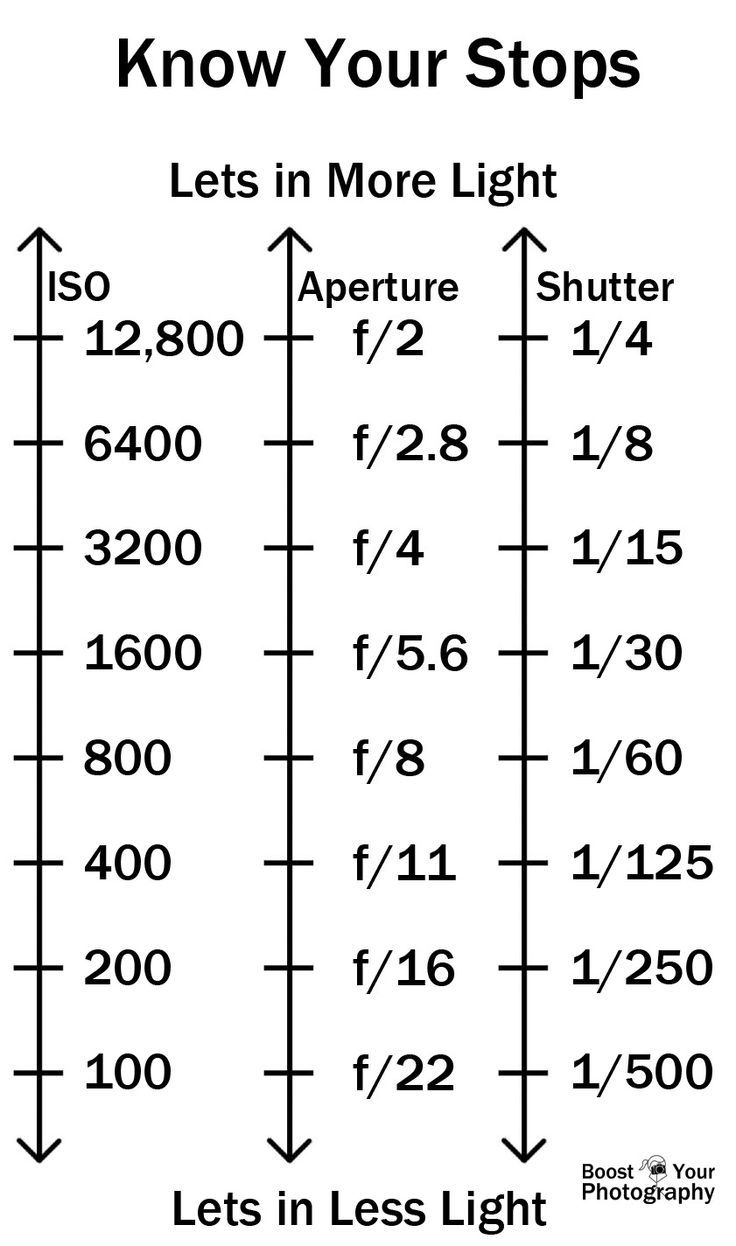
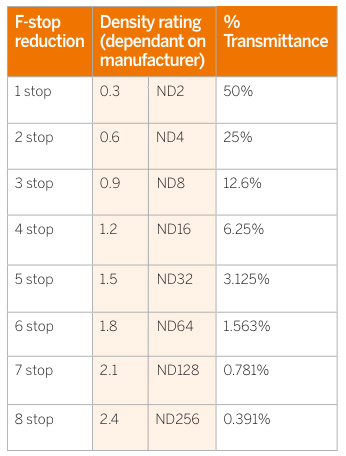
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
Read more: Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cardsAlso see:
https://www.pixelsham.com/2018/11/22/exposure-value-measurements/
https://www.pixelsham.com/2016/03/03/f-stop-vs-t-stop/

An exposure stop is a unit measurement of Exposure as such it provides a universal linear scale to measure the increase and decrease in light, exposed to the image sensor, due to changes in shutter speed, iso and f-stop.
+-1 stop is a doubling or halving of the amount of light let in when taking a photo
1 EV (exposure value) is just another way to say one stop of exposure change.
https://www.photographymad.com/pages/view/what-is-a-stop-of-exposure-in-photography
Same applies to shutter speed, iso and aperture.
Doubling or halving your shutter speed produces an increase or decrease of 1 stop of exposure.
Doubling or halving your iso speed produces an increase or decrease of 1 stop of exposure.


Because of the way f-stop numbers are calculated (ratio of focal length/lens diameter, where focal length is the distance between the lens and the sensor), an f-stop doesn’t relate to a doubling or halving of the value, but to the doubling/halving of the area coverage of a lens in relation to its focal length. And as such, to a multiplying or dividing by 1.41 (the square root of 2). For example, going from f/2.8 to f/4 is a decrease of 1 stop because 4 = 2.8 * 1.41. Changing from f/16 to f/11 is an increase of 1 stop because 11 = 16 / 1.41.
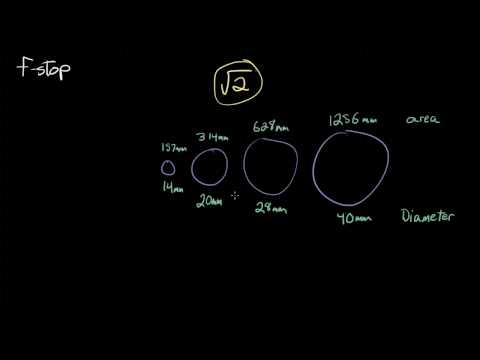
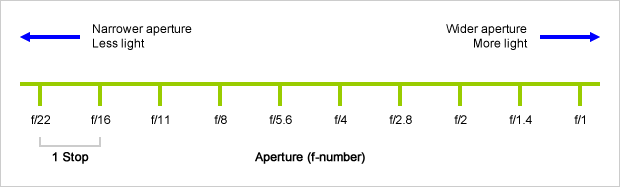
A wider aperture means that light proceeding from the foreground, subject, and background is entering at more oblique angles than the light entering less obliquely.
Consider that absolutely everything is bathed in light, therefore light bouncing off of anything is effectively omnidirectional. Your camera happens to be picking up a tiny portion of the light that’s bouncing off into infinity.
Now consider that the wider your iris/aperture, the more of that omnidirectional light you’re picking up:
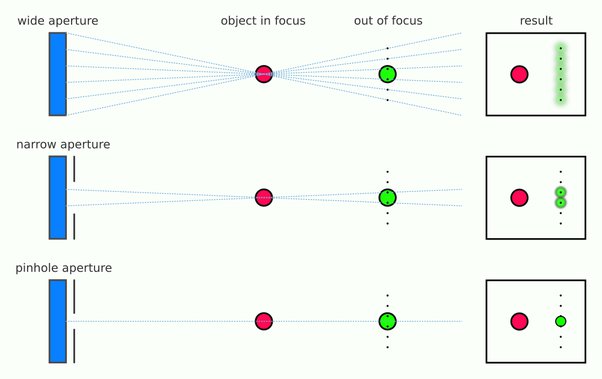
When you have a very narrow iris you are eliminating a lot of oblique light. Whatever light enters, from whatever distance, enters moderately parallel as a whole. When you have a wide aperture, much more light is entering at a multitude of angles. Your lens can only focus the light from one depth – the foreground/background appear blurred because it cannot be focused on.
https://frankwhitephotography.com/index.php?id=28:what-is-a-stop-in-photography
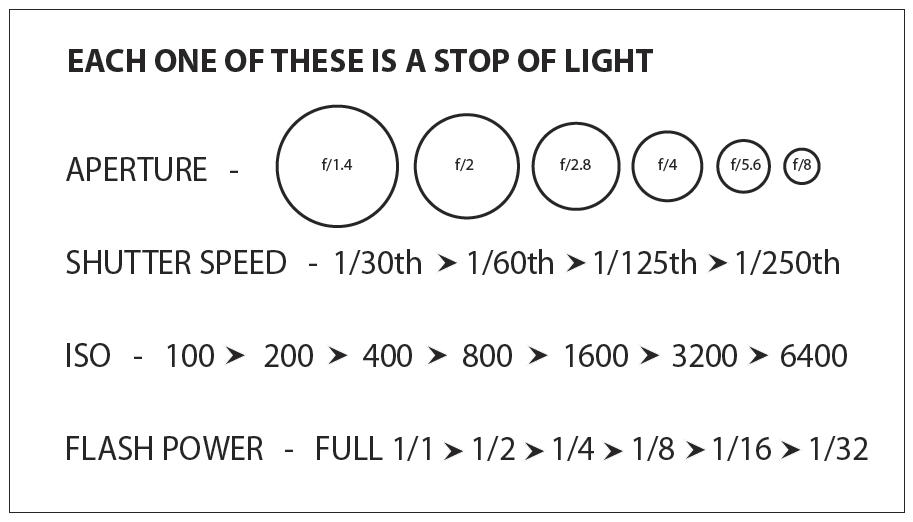
The great thing about stops is that they give us a way to directly compare shutter speed, aperture diameter, and ISO speed. This means that we can easily swap these three components about while keeping the overall exposure the same.
http://lifehacker.com/how-aperture-shutter-speed-and-iso-affect-pictures-sh-1699204484
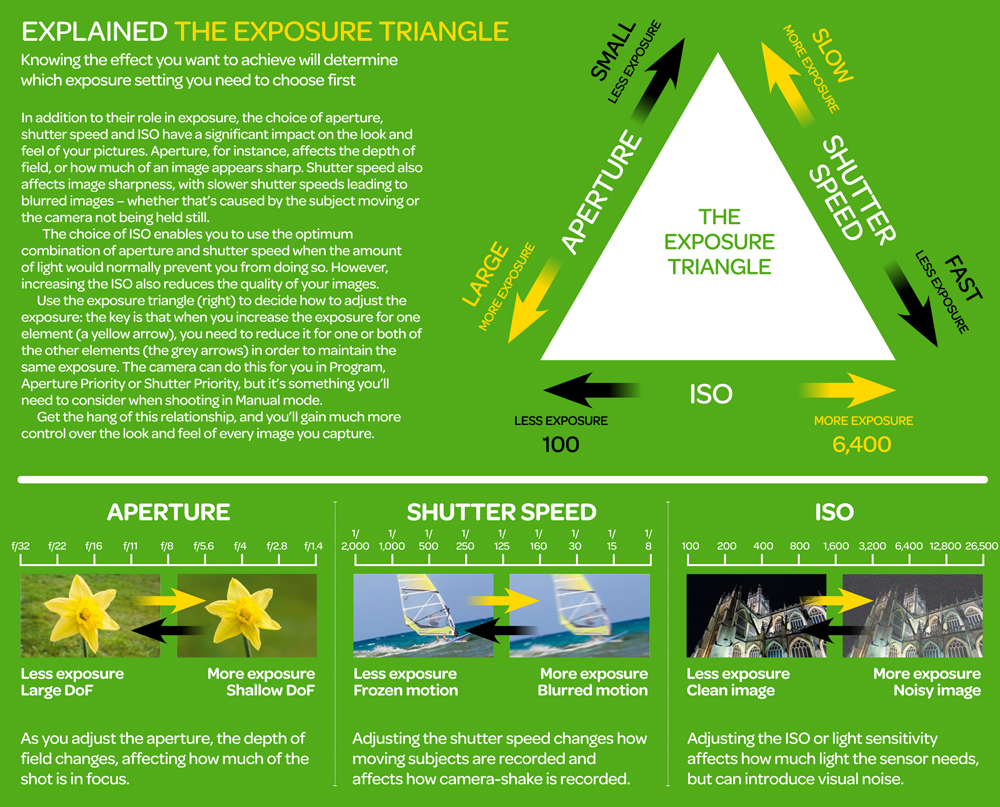
https://www.techradar.com/how-to/the-exposure-triangle

https://www.videoschoolonline.com/what-is-an-exposure-stop
Note. All three of these measurements (aperture, shutter, iso) have full stops, half stops and third stops, but if you look at the numbers they aren’t always consistent. For example, a one third stop between ISO100 and ISO 200 would be ISO133, yet most cameras are marked at ISO125.
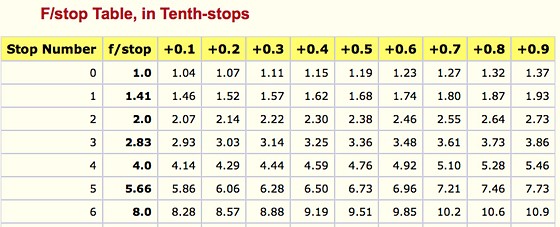
Third-stops are especially important as they’re the increment that most cameras use for their settings. These are just imaginary divisions in each stop.
From a practical standpoint manufacturers only standardize the full stops, meaning that while they try and stay somewhat consistent there is some rounding up going on between the smaller numbers.


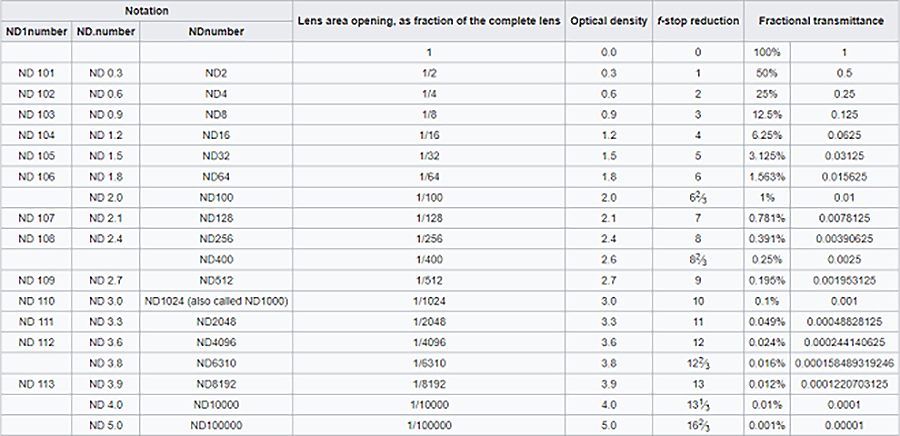
Note that ND Filters directly modify the exposure triangle.
















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
-
Top 3D Printing Website Resources
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
-
How to paint a boardgame miniatures
-
Free fonts
-
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
-
Python and TCL: Tips and Tricks for Foundry Nuke
-
Godot Cheat Sheets
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
