COMPOSITION
-
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.





DESIGN
-
Magic Carpet by artist Daniel Wurtzel
Read more: Magic Carpet by artist Daniel Wurtzelhttps://www.youtube.com/watch?v=1C_40B9m4tI http://www.danielwurtzel.com




COLOR
-
What causes color
Read more: What causes colorwww.webexhibits.org/causesofcolor/5.html
Water itself has an intrinsic blue color that is a result of its molecular structure and its behavior.
-
If a blind person gained sight, could they recognize objects previously touched?
Read more: If a blind person gained sight, could they recognize objects previously touched?Blind people who regain their sight may find themselves in a world they don’t immediately comprehend. “It would be more like a sighted person trying to rely on tactile information,” Moore says.
Learning to see is a developmental process, just like learning language, Prof Cathleen Moore continues. “As far as vision goes, a three-and-a-half year old child is already a well-calibrated system.”
-
Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipeline
Read more: Weta Digital – Manuka Raytracer and Gazebo GPU renderers – pipelinehttps://jo.dreggn.org/home/2018_manuka.pdf
http://www.fxguide.com/featured/manuka-weta-digitals-new-renderer/

The Manuka rendering architecture has been designed in the spirit of the classic reyes rendering architecture. In its core, reyes is based on stochastic rasterisation of micropolygons, facilitating depth of field, motion blur, high geometric complexity,and programmable shading.
This is commonly achieved with Monte Carlo path tracing, using a paradigm often called shade-on-hit, in which the renderer alternates tracing rays with running shaders on the various ray hits. The shaders take the role of generating the inputs of the local material structure which is then used bypath sampling logic to evaluate contributions and to inform what further rays to cast through the scene.
Over the years, however, the expectations have risen substantially when it comes to image quality. Computing pictures which are indistinguishable from real footage requires accurate simulation of light transport, which is most often performed using some variant of Monte Carlo path tracing. Unfortunately this paradigm requires random memory accesses to the whole scene and does not lend itself well to a rasterisation approach at all.
Manuka is both a uni-directional and bidirectional path tracer and encompasses multiple importance sampling (MIS). Interestingly, and importantly for production character skin work, it is the first major production renderer to incorporate spectral MIS in the form of a new ‘Hero Spectral Sampling’ technique, which was recently published at Eurographics Symposium on Rendering 2014.
Manuka propose a shade-before-hit paradigm in-stead and minimise I/O strain (and some memory costs) on the system, leveraging locality of reference by running pattern generation shaders before we execute light transport simulation by path sampling, “compressing” any bvh structure as needed, and as such also limiting duplication of source data.
The difference with reyes is that instead of baking colors into the geometry like in Reyes, manuka bakes surface closures. This means that light transport is still calculated with path tracing, but all texture lookups etc. are done up-front and baked into the geometry.The main drawback with this method is that geometry has to be tessellated to its highest, stable topology before shading can be evaluated properly. As such, the high cost to first pixel. Even a basic 4 vertices square becomes a much more complex model with this approach.

Manuka use the RenderMan Shading Language (rsl) for programmable shading [Pixar Animation Studios 2015], but we do not invoke rsl shaders when intersecting a ray with a surface (often called shade-on-hit). Instead, we pre-tessellate and pre-shade all the input geometry in the front end of the renderer.
This way, we can efficiently order shading computations to sup-port near-optimal texture locality, vectorisation, and parallelism. This system avoids repeated evaluation of shaders at the same surface point, and presents a minimal amount of memory to be accessed during light transport time. An added benefit is that the acceleration structure for ray tracing (abounding volume hierarchy, bvh) is built once on the final tessellated geometry, which allows us to ray trace more efficiently than multi-level bvhs and avoids costly caching of on-demand tessellated micropolygons and the associated scheduling issues.For the shading reasons above, in terms of AOVs, the studio approach is to succeed at combining complex shading with ray paths in the render rather than pass a multi-pass render to compositing.
For the Spectral Rendering component. The light transport stage is fully spectral, using a continuously sampled wavelength which is traced with each path and used to apply the spectral camera sensitivity of the sensor. This allows for faithfully support any degree of observer metamerism as the camera footage they are intended to match as well as complex materials which require wavelength dependent phenomena such as diffraction, dispersion, interference, iridescence, or chromatic extinction and Rayleigh scattering in participating media.
As opposed to the original reyes paper, we use bilinear interpolation of these bsdf inputs later when evaluating bsdfs per pathv ertex during light transport4. This improves temporal stability of geometry which moves very slowly with respect to the pixel raster
In terms of the pipeline, everything rendered at Weta was already completely interwoven with their deep data pipeline. Manuka very much was written with deep data in mind. Here, Manuka not so much extends the deep capabilities, rather it fully matches the already extremely complex and powerful setup Weta Digital already enjoy with RenderMan. For example, an ape in a scene can be selected, its ID is available and a NUKE artist can then paint in 3D say a hand and part of the way up the neutral posed ape.
We called our system Manuka, as a respectful nod to reyes: we had heard a story froma former ILM employee about how reyes got its name from how fond the early Pixar people were of their lunches at Point Reyes, and decided to name our system after our surrounding natural environment, too. Manuka is a kind of tea tree very common in New Zealand which has very many very small leaves, in analogy to micropolygons ina tree structure for ray tracing. It also happens to be the case that Weta Digital’s main site is on Manuka Street.



![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")

LIGHTING
-
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
# bottom left coordinates = 0,0 import numpy as np import cv2 # Load the HDR or EXR image image = cv2.imread('your_image_path.exr', cv2.IMREAD_UNCHANGED) # Load as-is without modification # Calculate the luminance from the HDR channels (assuming RGB format) luminance = np.dot(image[..., :3], [0.299, 0.587, 0.114]) # Set a threshold value based on estimated EV threshold_value = 2.4 # Estimated threshold value based on 4.8 EV # Apply the threshold to identify bright areas # Theluminancearray contains the calculated luminance values for each pixel in the image. # Thethreshold_valueis a user-defined value that represents a cutoff point, separating "bright" and "dark" areas in terms of perceived luminance.thresholded = (luminance > threshold_value) * 255 # Convert the thresholded image to uint8 for contour detection thresholded = thresholded.astype(np.uint8) # Find contours of the bright areas contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # Create a list to store the bounding boxes of bright areas bright_areas = [] # Iterate through contours and extract bounding boxes for contour in contours: x, y, w, h = cv2.boundingRect(contour) # Adjust y-coordinate based on bottom-left origin y_bottom_left_origin = image.shape[0] - (y + h) bright_areas.append((x, y_bottom_left_origin, x + w, y_bottom_left_origin + h)) # Store as (x1, y1, x2, y2) # Print the identified bright areas print("Bright Areas (x1, y1, x2, y2):") for area in bright_areas: print(area)More details
Luminance and Exposure in an EXR Image:
- An EXR (Extended Dynamic Range) image format is often used to store high dynamic range (HDR) images that contain a wide range of luminance values, capturing both dark and bright areas.
- Luminance refers to the perceived brightness of a pixel in an image. In an RGB image, luminance is often calculated using a weighted sum of the red, green, and blue channels, where different weights are assigned to each channel to account for human perception.
- In an EXR image, the pixel values can represent radiometrically accurate scene values, including actual radiance or irradiance levels. These values are directly related to the amount of light emitted or reflected by objects in the scene.
The luminance line is calculating the luminance of each pixel in the image using a weighted sum of the red, green, and blue channels. The three float values [0.299, 0.587, 0.114] are the weights used to perform this calculation.
These weights are based on the concept of luminosity, which aims to approximate the perceived brightness of a color by taking into account the human eye’s sensitivity to different colors. The values are often derived from the NTSC (National Television System Committee) standard, which is used in various color image processing operations.
Here’s the breakdown of the float values:
- 0.299: Weight for the red channel.
- 0.587: Weight for the green channel.
- 0.114: Weight for the blue channel.
The weighted sum of these channels helps create a grayscale image where the pixel values represent the perceived brightness. This technique is often used when converting a color image to grayscale or when calculating luminance for certain operations, as it takes into account the human eye’s sensitivity to different colors.
For the threshold, remember that the exact relationship between EV values and pixel values can depend on the tone-mapping or normalization applied to the HDR image, as well as the dynamic range of the image itself.
To establish a relationship between exposure and the threshold value, you can consider the relationship between linear and logarithmic scales:
- Linear and Logarithmic Scales:
- Exposure values in an EXR image are often represented in logarithmic scales, such as EV (exposure value). Each increment in EV represents a doubling or halving of the amount of light captured.
- Threshold values for luminance thresholding are usually linear, representing an actual luminance level.
- Conversion Between Scales:
- To establish a mathematical relationship, you need to convert between the logarithmic exposure scale and the linear threshold scale.
- One common method is to use a power function. For instance, you can use a power function to convert EV to a linear intensity value.
threshold_value = base_value * (2 ** EV)Here,
EVis the exposure value,base_valueis a scaling factor that determines the relationship between EV and threshold_value, and2 ** EVis used to convert the logarithmic EV to a linear intensity value. - Choosing the Base Value:
- The
base_valuefactor should be determined based on the dynamic range of your EXR image and the specific luminance values you are dealing with. - You may need to experiment with different values of
base_valueto achieve the desired separation of bright areas from the rest of the image.
- The
Let’s say you have an EXR image with a dynamic range of 12 EV, which is a common range for many high dynamic range images. In this case, you want to set a threshold value that corresponds to a certain number of EV above the middle gray level (which is often considered to be around 0.18).
Here’s an example of how you might determine a
base_valueto achieve this:# Define the dynamic range of the image in EV dynamic_range = 12 # Choose the desired number of EV above middle gray for thresholding desired_ev_above_middle_gray = 2 # Calculate the threshold value based on the desired EV above middle gray threshold_value = 0.18 * (2 ** (desired_ev_above_middle_gray / dynamic_range)) print("Threshold Value:", threshold_value) -
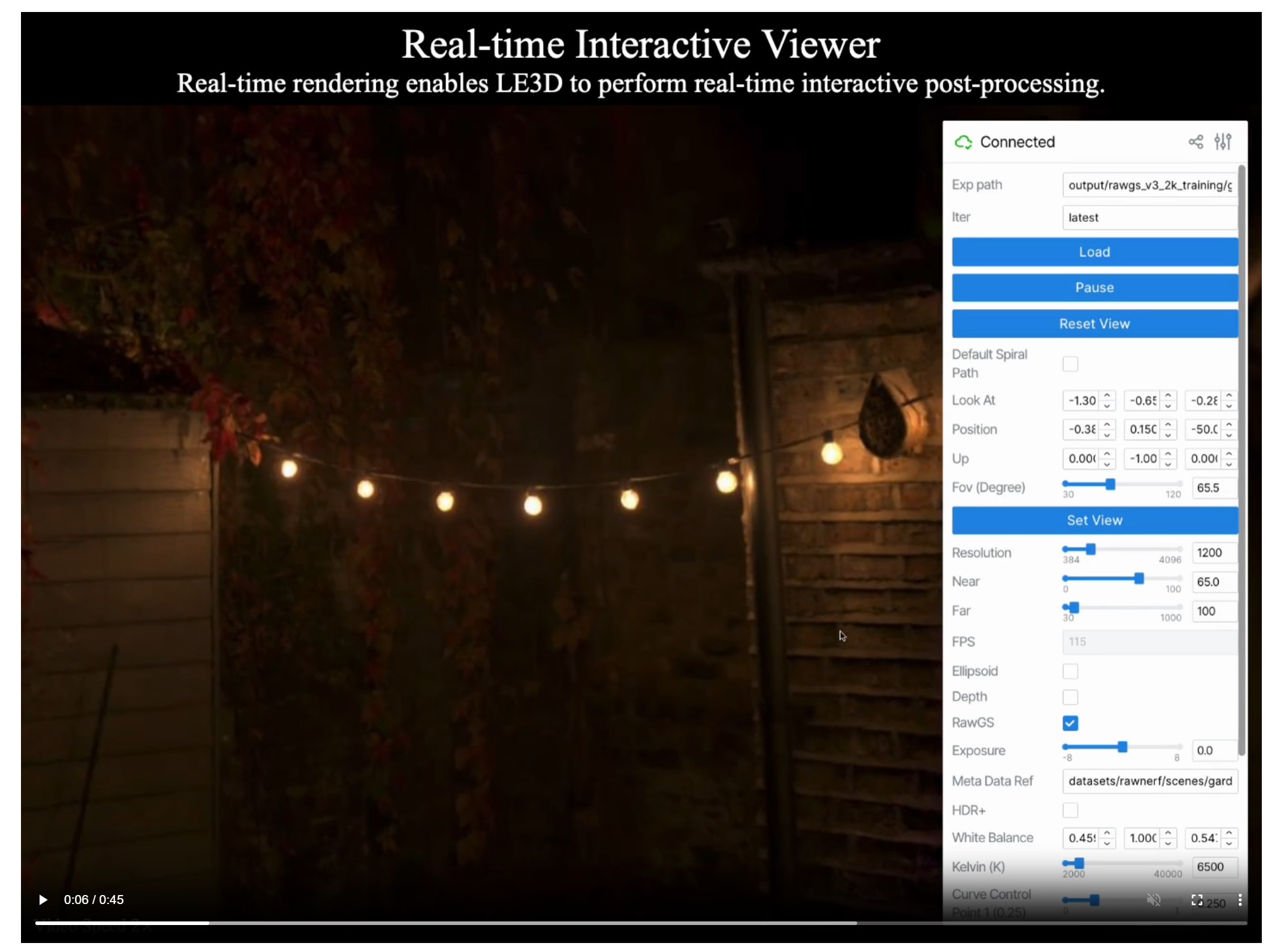
Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesis
Read more: Lighting Every Darkness with 3DGS: Fast Training and Real-Time Rendering and Denoising for HDR View Synthesishttps://srameo.github.io/projects/le3d/
LE3D is a method for real-time HDR view synthesis from RAW images. It is particularly effective for nighttime scenes.
https://github.com/Srameo/LE3D

-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
What type of lighting?-> High key lighting.
Features bright, even illumination and few conspicuous shadows. This lighting key is often used in musicals and comedies.Low key lighting
Features diffused shadows and atmospheric pools of light. This lighting key is often used in mysteries and thrillers.High contrast lighting
Features harsh shafts of lights and dramatic streaks of blackness. This type of lighting is often used in tragedies and melodramas.What type of shot?
Extreme long shot
Taken from a great distance, showing much of the locale. Ifpeople are included in these shots, they usually appear as mere specks-> Long shot
Corresponds to the space between the audience and the stage in a live theater. The long shots show the characters and some of the locale.Full shot
Range with just enough space to contain the human body in full. The full shot shows the character and a minimal amount of the locale.Medium shot
Shows the human figure from the knees or waist up.Close-Up
Concentrates on a relatively small object and show very little if any locale.Extreme close-up
Focuses on an unnaturally small portion of an object, giving that part great detail and symbolic significance.What angle?
Bird’s-eye view.
The shot is photographed directly from above. This type of shot can be disorienting, and the people photographed seem insignificant.High angle.
This angle reduces the size of the objects photographed. A person photographed from this angle seems harmless and insignificant, but to a lesser extent than with the bird’s-eye view.-> Eye-level shot.
The clearest view of an object, but seldom intrinsically dramatic, because it tends to be the norm.Low angle.
This angle increases high and a sense of verticality, heightening the importance of the object photographed. A person shot from this angle is given a sense of power and respect.Oblique angle.
For this angle, the camera is tilted laterally, giving the image a slanted appearance. Oblique angles suggest tension, transition, a impending movement. They are also called canted or dutch angles.What is the dominant color?
The use of color in this shot is symbolic. The scene is set in warehouse. Both the set and characters are blues, blacks and whites.
This was intentional allowing for the scenes and shots with blood to have a great level of contrast.
What is the Lens/Filter/Stock?
Telephoto lens.
A lens that draws objects closer but also diminishes the illusion of depth.Wide-angle lens.
A lens that takes in a broad area and increases the illusion of depth but sometimes distorts the edges of the image.Fast film stock.
Highly sensitive to light, it can register an image with little illumination. However, the final product tends to be grainy.Slow film stock.
Relatively insensitive to light, it requires a great deal of illumination. The final product tends to look polished.The lens is not wide-angle because there isn’t a great sense of depth, nor are several planes in focus. The lens is probably long but not necessarily a telephoto lens because the depth isn’t inordinately compressed.
The stock is fast because of the grainy quality of the image.
Subsidiary Contrast; where does the eye go next?
The two guns.
How much visual information is packed into the image? Is the texture stark, moderate, or highly detailed?
Minimalist clutter in the warehouse allows a focus on a character driven thriller.
What is the Composition?
Horizontal.
Compositions based on horizontal lines seem visually at rest and suggest placidity or peacefulness.Vertical.
Compositions based on vertical lines seem visually at rest and suggest strength.-> Diagonal.
Compositions based on diagonal, or oblique, lines seem dynamic and suggest tension or anxiety.-> Binary. Binary structures emphasize parallelism.
Triangle.
Triadic compositions stress the dynamic interplay among three mainCircle.
Circular compositions suggest security and enclosure.Is the form open or closed? Does the image suggest a window that arbitrarily isolates a fragment of the scene? Or a proscenium arch, in which the visual elements are carefully arranged and held in balance?
The most nebulous of all the categories of mise en scene, the type of form is determined by how consciously structured the mise en scene is. Open forms stress apparently simple techniques, because with these unself-conscious methods the filmmaker is able to emphasize the immediate, the familiar, the intimate aspects of reality. In open-form images, the frame tends to be deemphasized. In closed form images, all the necessary information is carefully structured within the confines of the frame. Space seems enclosed and self-contained rather than continuous.
Could argue this is a proscenium arch because this is such a classic shot with parallels and juxtapositions.
Is the framing tight or loose? Do the character have no room to move around, or can they move freely without impediments?
Shots where the characters are placed at the edges of the frame and have little room to move around within the frame are considered tight.
Longer shots, in which characters have room to move around within the frame, are considered loose and tend to suggest freedom.
Center-framed giving us the entire scene showing isolation, place and struggle.
Depth of Field. On how many planes is the image composed (how many are in focus)? Does the background or foreground comment in any way on the mid-ground?
Standard DOF, one background and clearly defined foreground.
Which way do the characters look vis-a-vis the camera?
An actor can be photographed in any of five basic positions, each conveying different psychological overtones.
Full-front (facing the camera):
the position with the most intimacy. The character is looking in our direction, inviting our complicity.Quarter Turn:
the favored position of most filmmakers. This position offers a high degree of intimacy but with less emotional involvement than the full-front.-> Profile (looking of the frame left or right):
More remote than the quarter turn, the character in profile seems unaware of being observed, lost in his or her own thoughts.Three-quarter Turn:
More anonymous than the profile, this position is useful for conveying a character’s unfriendly or antisocial feelings, for in effect, the character is partially turning his or her back on us, rejecting our interest.Back to Camera:
The most anonymous of all positions, this position is often used to suggest a character’s alienation from the world. When a character has his or her back to the camera, we can only guess what’s taking place internally, conveying a sense of concealment, or mystery.How much space is there between the characters?
Extremely close, for a gunfight.
The way people use space can be divided into four proxemic patterns.
Intimate distances.
The intimate distance ranges from skin contact to about eighteen inches away. This is the distance of physical involvement–of love, comfort, and tenderness between individuals.-> Personal distances.
The personal distance ranges roughly from eighteen inches away to about four feet away. These distances tend to be reserved for friends and acquaintances. Personal distances preserve the privacy between individuals, yet these rages don’t necessarily suggest exclusion, as intimate distances often do.Social distances.
The social distance rages from four feet to about twelve feet. These distances are usually reserved for impersonal business and casual social gatherings. It’s a friendly range in most cases, yet somewhat more formal than the personal distance.Public distances.
The public distance extends from twelve feet to twenty-five feet or more. This range tends to be formal and rather detached.



Collections
| Explore posts
| Design And Composition
| Featured AI
Popular Searches
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
