


COMPOSITION




DESIGN
COLOR
-
About color: What is a LUT
Read more: About color: What is a LUThttp://www.lightillusion.com/luts.html
https://www.shutterstock.com/blog/how-use-luts-color-grading
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.


-
Tim Kang – calibrated white light values in sRGB color space
Read more: Tim Kang – calibrated white light values in sRGB color space8bit sRGB encoded
2000K 255 139 22
2700K 255 172 89
3000K 255 184 109
3200K 255 190 122
4000K 255 211 165
4300K 255 219 178
D50 255 235 205
D55 255 243 224
D5600 255 244 227
D6000 255 249 240
D65 255 255 255
D10000 202 221 255
D20000 166 196 2558bit Rec709 Gamma 2.4
2000K 255 145 34
2700K 255 177 97
3000K 255 187 117
3200K 255 193 129
4000K 255 214 170
4300K 255 221 182
D50 255 236 208
D55 255 243 226
D5600 255 245 229
D6000 255 250 241
D65 255 255 255
D10000 204 222 255
D20000 170 199 2558bit Display P3 encoded
2000K 255 154 63
2700K 255 185 109
3000K 255 195 127
3200K 255 201 138
4000K 255 219 176
4300K 255 225 187
D50 255 239 212
D55 255 245 228
D5600 255 246 231
D6000 255 251 242
D65 255 255 255
D10000 208 223 255
D20000 175 199 25510bit Rec2020 PQ (100 nits)
2000K 520 435 273
2700K 520 466 358
3000K 520 475 384
3200K 520 480 399
4000K 520 495 446
4300K 520 500 458
D50 520 510 482
D55 520 514 497
D5600 520 514 500
D6000 520 517 509
D65 520 520 520
D10000 479 489 520
D20000 448 464 520
-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
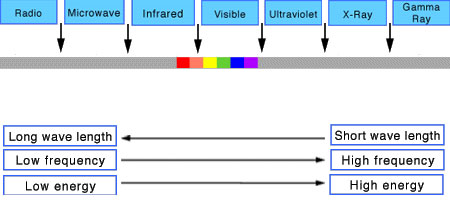
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
OpenColorIO standard
Read more: OpenColorIO standardhttps://www.provideocoalition.com/color-management-part-11-introducing-opencolorio/
OpenColorIO (OCIO) is a new open source project from Sony Imageworks.
Based on development started in 2003, OCIO enables color transforms and image display to be handled in a consistent manner across multiple graphics applications. Unlike other color management solutions, OCIO is geared towards motion-picture post production, with an emphasis on visual effects and animation color pipelines.

-
colorhunt.co
Read more: colorhunt.coColor Hunt is a free and open platform for color inspiration with thousands of trendy hand-picked color palettes.

-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
Read more: Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacynofilmschool.com/types-of-film-lights
“Not every light performs the same way. Lights and lighting are tricky to handle. You have to plan for every circumstance. But the good news is, lighting can be adjusted. Let’s look at different factors that affect lighting in every scene you shoot. “
Use CRI, Luminous Efficacy and color temperature controls to match your needs.
Color Temperature
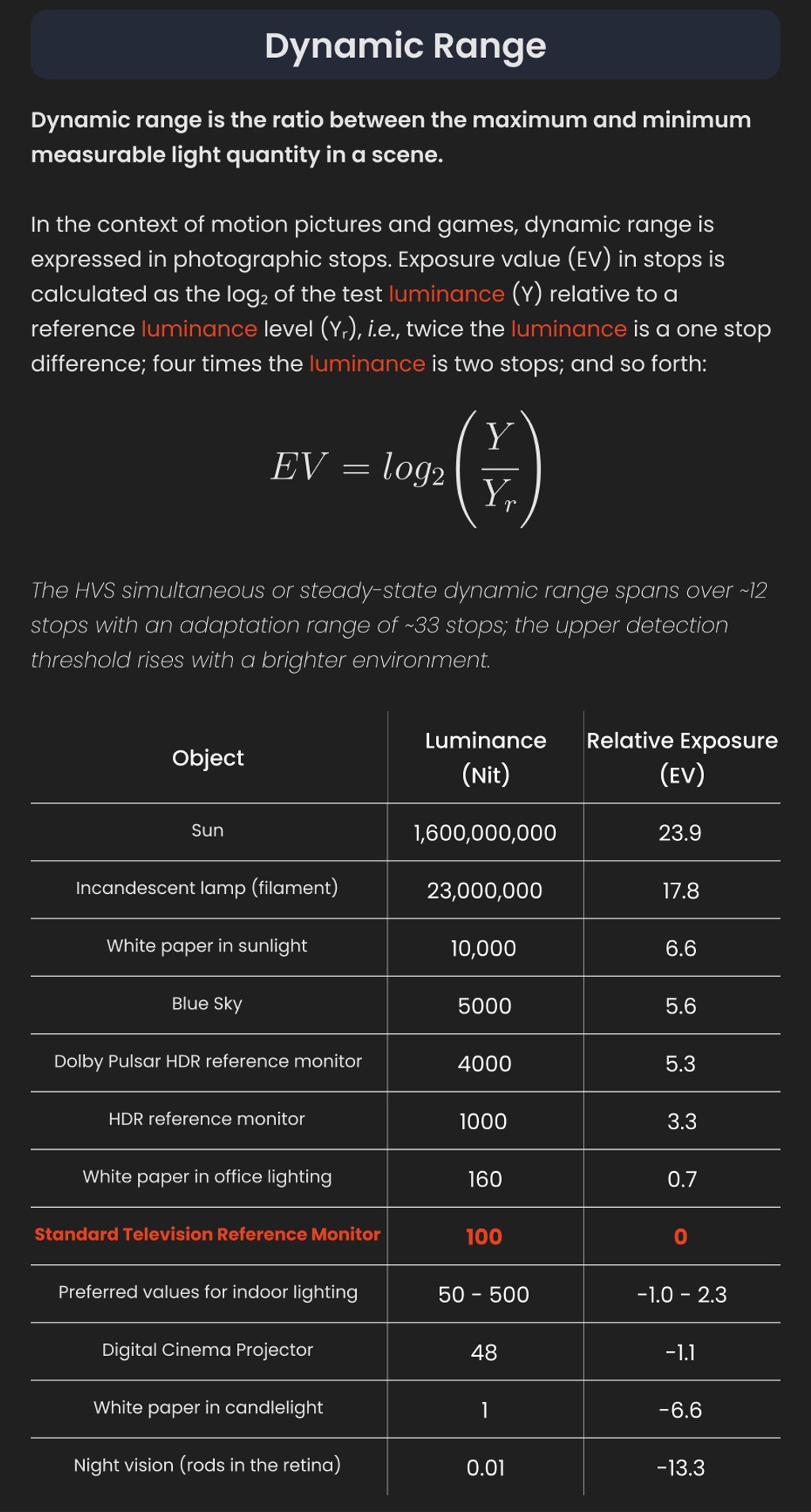
Color temperature describes the “color” of white light by a light source radiated by a perfect black body at a given temperature measured in degrees Kelvinhttps://www.pixelsham.com/2019/10/18/color-temperature/
CRI
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. “https://www.studiobinder.com/blog/what-is-color-rendering-index
(more…)









LIGHTING
-
Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
Read more: Composition – 5 tips for creating perfect cinematic lighting and making your work look stunning
http://www.diyphotography.net/5-tips-creating-perfect-cinematic-lighting-making-work-look-stunning/
1. Learn the rules of lighting
2. Learn when to break the rules
3. Make your key light larger
4. Reverse keying
5. Always be backlighting
-
Neural Microfacet Fields for Inverse Rendering
Read more: Neural Microfacet Fields for Inverse Renderinghttps://half-potato.gitlab.io/posts/nmf/













COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
3D Gaussian Splatting step by step beginner course
-
Google – Artificial Intelligence free courses
-
JavaScript how-to free resources
-
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
-
SourceTree vs Github Desktop – Which one to use
-
Photography basics: Color Temperature and White Balance
-
AI Data Laundering: How Academic and Nonprofit Researchers Shield Tech Companies from Accountability
-
Daniele Tosti Interview for the magazine InCG, Taiwan, Issue 28, 201609
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
