


COMPOSITION
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
What type of lighting?-> High key lighting.
Features bright, even illumination and few conspicuous shadows. This lighting key is often used in musicals and comedies.Low key lighting
Features diffused shadows and atmospheric pools of light. This lighting key is often used in mysteries and thrillers.High contrast lighting
Features harsh shafts of lights and dramatic streaks of blackness. This type of lighting is often used in tragedies and melodramas.What type of shot?
Extreme long shot
Taken from a great distance, showing much of the locale. Ifpeople are included in these shots, they usually appear as mere specks-> Long shot
Corresponds to the space between the audience and the stage in a live theater. The long shots show the characters and some of the locale.Full shot
Range with just enough space to contain the human body in full. The full shot shows the character and a minimal amount of the locale.Medium shot
Shows the human figure from the knees or waist up.Close-Up
Concentrates on a relatively small object and show very little if any locale.Extreme close-up
Focuses on an unnaturally small portion of an object, giving that part great detail and symbolic significance.What angle?
Bird’s-eye view.
The shot is photographed directly from above. This type of shot can be disorienting, and the people photographed seem insignificant.High angle.
This angle reduces the size of the objects photographed. A person photographed from this angle seems harmless and insignificant, but to a lesser extent than with the bird’s-eye view.-> Eye-level shot.
The clearest view of an object, but seldom intrinsically dramatic, because it tends to be the norm.Low angle.
This angle increases high and a sense of verticality, heightening the importance of the object photographed. A person shot from this angle is given a sense of power and respect.Oblique angle.
For this angle, the camera is tilted laterally, giving the image a slanted appearance. Oblique angles suggest tension, transition, a impending movement. They are also called canted or dutch angles.What is the dominant color?
The use of color in this shot is symbolic. The scene is set in warehouse. Both the set and characters are blues, blacks and whites.
This was intentional allowing for the scenes and shots with blood to have a great level of contrast.
What is the Lens/Filter/Stock?
Telephoto lens.
A lens that draws objects closer but also diminishes the illusion of depth.Wide-angle lens.
A lens that takes in a broad area and increases the illusion of depth but sometimes distorts the edges of the image.Fast film stock.
Highly sensitive to light, it can register an image with little illumination. However, the final product tends to be grainy.Slow film stock.
Relatively insensitive to light, it requires a great deal of illumination. The final product tends to look polished.The lens is not wide-angle because there isn’t a great sense of depth, nor are several planes in focus. The lens is probably long but not necessarily a telephoto lens because the depth isn’t inordinately compressed.
The stock is fast because of the grainy quality of the image.
Subsidiary Contrast; where does the eye go next?
The two guns.
How much visual information is packed into the image? Is the texture stark, moderate, or highly detailed?
Minimalist clutter in the warehouse allows a focus on a character driven thriller.
What is the Composition?
Horizontal.
Compositions based on horizontal lines seem visually at rest and suggest placidity or peacefulness.Vertical.
Compositions based on vertical lines seem visually at rest and suggest strength.-> Diagonal.
Compositions based on diagonal, or oblique, lines seem dynamic and suggest tension or anxiety.-> Binary. Binary structures emphasize parallelism.
Triangle.
Triadic compositions stress the dynamic interplay among three mainCircle.
Circular compositions suggest security and enclosure.Is the form open or closed? Does the image suggest a window that arbitrarily isolates a fragment of the scene? Or a proscenium arch, in which the visual elements are carefully arranged and held in balance?
The most nebulous of all the categories of mise en scene, the type of form is determined by how consciously structured the mise en scene is. Open forms stress apparently simple techniques, because with these unself-conscious methods the filmmaker is able to emphasize the immediate, the familiar, the intimate aspects of reality. In open-form images, the frame tends to be deemphasized. In closed form images, all the necessary information is carefully structured within the confines of the frame. Space seems enclosed and self-contained rather than continuous.
Could argue this is a proscenium arch because this is such a classic shot with parallels and juxtapositions.
Is the framing tight or loose? Do the character have no room to move around, or can they move freely without impediments?
Shots where the characters are placed at the edges of the frame and have little room to move around within the frame are considered tight.
Longer shots, in which characters have room to move around within the frame, are considered loose and tend to suggest freedom.
Center-framed giving us the entire scene showing isolation, place and struggle.
Depth of Field. On how many planes is the image composed (how many are in focus)? Does the background or foreground comment in any way on the mid-ground?
Standard DOF, one background and clearly defined foreground.
Which way do the characters look vis-a-vis the camera?
An actor can be photographed in any of five basic positions, each conveying different psychological overtones.
Full-front (facing the camera):
the position with the most intimacy. The character is looking in our direction, inviting our complicity.Quarter Turn:
the favored position of most filmmakers. This position offers a high degree of intimacy but with less emotional involvement than the full-front.-> Profile (looking of the frame left or right):
More remote than the quarter turn, the character in profile seems unaware of being observed, lost in his or her own thoughts.Three-quarter Turn:
More anonymous than the profile, this position is useful for conveying a character’s unfriendly or antisocial feelings, for in effect, the character is partially turning his or her back on us, rejecting our interest.Back to Camera:
The most anonymous of all positions, this position is often used to suggest a character’s alienation from the world. When a character has his or her back to the camera, we can only guess what’s taking place internally, conveying a sense of concealment, or mystery.How much space is there between the characters?
Extremely close, for a gunfight.
The way people use space can be divided into four proxemic patterns.
Intimate distances.
The intimate distance ranges from skin contact to about eighteen inches away. This is the distance of physical involvement–of love, comfort, and tenderness between individuals.-> Personal distances.
The personal distance ranges roughly from eighteen inches away to about four feet away. These distances tend to be reserved for friends and acquaintances. Personal distances preserve the privacy between individuals, yet these rages don’t necessarily suggest exclusion, as intimate distances often do.Social distances.
The social distance rages from four feet to about twelve feet. These distances are usually reserved for impersonal business and casual social gatherings. It’s a friendly range in most cases, yet somewhat more formal than the personal distance.Public distances.
The public distance extends from twelve feet to twenty-five feet or more. This range tends to be formal and rather detached.





















DESIGN




























































COLOR
-
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.
-
Scene Referred vs Display Referred color workflows
Read more: Scene Referred vs Display Referred color workflowsDisplay Referred it is tied to the target hardware, as such it bakes color requirements into every type of media output request.
Scene Referred uses a common unified wide gamut and targeting audience through CDL and DI libraries instead.
So that color information stays untouched and only “transformed” as/when needed.



Sources:
– Victor Perez – Color Management Fundamentals & ACES Workflows in Nuke
– https://z-fx.nl/ColorspACES.pdf
– Wicus
-
StudioBinder.com – CRI color rendering index
Read more: StudioBinder.com – CRI color rendering indexwww.studiobinder.com/blog/what-is-color-rendering-index
“The Color Rendering Index is a measurement of how faithfully a light source reveals the colors of whatever it illuminates, it describes the ability of a light source to reveal the color of an object, as compared to the color a natural light source would provide. The highest possible CRI is 100. A CRI of 100 generally refers to a perfect black body, like a tungsten light source or the sun. ”


www.pixelsham.com/2021/04/28/types-of-film-lights-and-their-efficiency
-
Capturing the world in HDR for real time projects – Call of Duty: Advanced Warfare
Read more: Capturing the world in HDR for real time projects – Call of Duty: Advanced WarfareReal-World Measurements for Call of Duty: Advanced Warfare
www.activision.com/cdn/research/Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf
Local version
Real_World_Measurements_for_Call_of_Duty_Advanced_Warfare.pdf

-
Colour – MacBeth Chart Checker Detection
Read more: Colour – MacBeth Chart Checker Detectiongithub.com/colour-science/colour-checker-detection
A Python package implementing various colour checker detection algorithms and related utilities.

-
Björn Ottosson – OKHSV and OKHSL – Two new color spaces for color picking
Read more: Björn Ottosson – OKHSV and OKHSL – Two new color spaces for color pickinghttps://bottosson.github.io/misc/colorpicker
https://bottosson.github.io/posts/colorpicker/
https://www.smashingmagazine.com/2024/10/interview-bjorn-ottosson-creator-oklab-color-space/
One problem with sRGB is that in a gradient between blue and white, it becomes a bit purple in the middle of the transition. That’s because sRGB really isn’t created to mimic how the eye sees colors; rather, it is based on how CRT monitors work. That means it works with certain frequencies of red, green, and blue, and also the non-linear coding called gamma. It’s a miracle it works as well as it does, but it’s not connected to color perception. When using those tools, you sometimes get surprising results, like purple in the gradient.

There were also attempts to create simple models matching human perception based on XYZ, but as it turned out, it’s not possible to model all color vision that way. Perception of color is incredibly complex and depends, among other things, on whether it is dark or light in the room and the background color it is against. When you look at a photograph, it also depends on what you think the color of the light source is. The dress is a typical example of color vision being very context-dependent. It is almost impossible to model this perfectly.
I based Oklab on two other color spaces, CIECAM16 and IPT. I used the lightness and saturation prediction from CIECAM16, which is a color appearance model, as a target. I actually wanted to use the datasets used to create CIECAM16, but I couldn’t find them.
IPT was designed to have better hue uniformity. In experiments, they asked people to match light and dark colors, saturated and unsaturated colors, which resulted in a dataset for which colors, subjectively, have the same hue. IPT has a few other issues but is the basis for hue in Oklab.
In the Munsell color system, colors are described with three parameters, designed to match the perceived appearance of colors: Hue, Chroma and Value. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. The parameters are designed to be independent and each have a uniform scale. This results in a color solid with an irregular shape. Modern color spaces and models, such as CIELAB, Cam16 and Björn Ottosson own Oklab, are very similar in their construction.

By far the most used color spaces today for color picking are HSL and HSV, two representations introduced in the classic 1978 paper “Color Spaces for Computer Graphics”. HSL and HSV designed to roughly correlate with perceptual color properties while being very simple and cheap to compute.
Today HSL and HSV are most commonly used together with the sRGB color space.

One of the main advantages of HSL and HSV over the different Lab color spaces is that they map the sRGB gamut to a cylinder. This makes them easy to use since all parameters can be changed independently, without the risk of creating colors outside of the target gamut.

The main drawback on the other hand is that their properties don’t match human perception particularly well.
Reconciling these conflicting goals perfectly isn’t possible, but given that HSV and HSL don’t use anything derived from experiments relating to human perception, creating something that makes a better tradeoff does not seem unreasonable.
With this new lightness estimate, we are ready to look into the construction of Okhsv and Okhsl.












LIGHTING
-
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”

-
Disney’s Moana Island Scene – Free data set
Read more: Disney’s Moana Island Scene – Free data sethttps://www.disneyanimation.com/resources/moana-island-scene/
This data set contains everything necessary to render a version of the Motunui island featured in the 2016 film Moana.

-
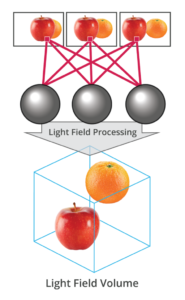
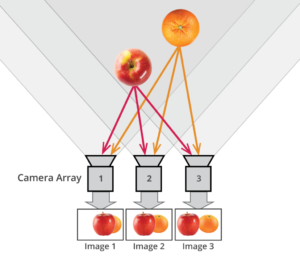
What is the Light Field?
Read more: What is the Light Field?http://lightfield-forum.com/what-is-the-lightfield/
The light field consists of the total of all light rays in 3D space, flowing through every point and in every direction.
How to Record a Light Field
- a single, robotically controlled camera
- a rotating arc of cameras
- an array of cameras or camera modules
- a single camera or camera lens fitted with a microlens array
-
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
# bottom left coordinates = 0,0 import numpy as np import cv2 # Load the HDR or EXR image image = cv2.imread('your_image_path.exr', cv2.IMREAD_UNCHANGED) # Load as-is without modification # Calculate the luminance from the HDR channels (assuming RGB format) luminance = np.dot(image[..., :3], [0.299, 0.587, 0.114]) # Set a threshold value based on estimated EV threshold_value = 2.4 # Estimated threshold value based on 4.8 EV # Apply the threshold to identify bright areas # Theluminancearray contains the calculated luminance values for each pixel in the image. # Thethreshold_valueis a user-defined value that represents a cutoff point, separating "bright" and "dark" areas in terms of perceived luminance.thresholded = (luminance > threshold_value) * 255 # Convert the thresholded image to uint8 for contour detection thresholded = thresholded.astype(np.uint8) # Find contours of the bright areas contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # Create a list to store the bounding boxes of bright areas bright_areas = [] # Iterate through contours and extract bounding boxes for contour in contours: x, y, w, h = cv2.boundingRect(contour) # Adjust y-coordinate based on bottom-left origin y_bottom_left_origin = image.shape[0] - (y + h) bright_areas.append((x, y_bottom_left_origin, x + w, y_bottom_left_origin + h)) # Store as (x1, y1, x2, y2) # Print the identified bright areas print("Bright Areas (x1, y1, x2, y2):") for area in bright_areas: print(area)More details
Luminance and Exposure in an EXR Image:
- An EXR (Extended Dynamic Range) image format is often used to store high dynamic range (HDR) images that contain a wide range of luminance values, capturing both dark and bright areas.
- Luminance refers to the perceived brightness of a pixel in an image. In an RGB image, luminance is often calculated using a weighted sum of the red, green, and blue channels, where different weights are assigned to each channel to account for human perception.
- In an EXR image, the pixel values can represent radiometrically accurate scene values, including actual radiance or irradiance levels. These values are directly related to the amount of light emitted or reflected by objects in the scene.
The luminance line is calculating the luminance of each pixel in the image using a weighted sum of the red, green, and blue channels. The three float values [0.299, 0.587, 0.114] are the weights used to perform this calculation.
These weights are based on the concept of luminosity, which aims to approximate the perceived brightness of a color by taking into account the human eye’s sensitivity to different colors. The values are often derived from the NTSC (National Television System Committee) standard, which is used in various color image processing operations.
Here’s the breakdown of the float values:
- 0.299: Weight for the red channel.
- 0.587: Weight for the green channel.
- 0.114: Weight for the blue channel.
The weighted sum of these channels helps create a grayscale image where the pixel values represent the perceived brightness. This technique is often used when converting a color image to grayscale or when calculating luminance for certain operations, as it takes into account the human eye’s sensitivity to different colors.
For the threshold, remember that the exact relationship between EV values and pixel values can depend on the tone-mapping or normalization applied to the HDR image, as well as the dynamic range of the image itself.
To establish a relationship between exposure and the threshold value, you can consider the relationship between linear and logarithmic scales:
- Linear and Logarithmic Scales:
- Exposure values in an EXR image are often represented in logarithmic scales, such as EV (exposure value). Each increment in EV represents a doubling or halving of the amount of light captured.
- Threshold values for luminance thresholding are usually linear, representing an actual luminance level.
- Conversion Between Scales:
- To establish a mathematical relationship, you need to convert between the logarithmic exposure scale and the linear threshold scale.
- One common method is to use a power function. For instance, you can use a power function to convert EV to a linear intensity value.
threshold_value = base_value * (2 ** EV)Here,
EVis the exposure value,base_valueis a scaling factor that determines the relationship between EV and threshold_value, and2 ** EVis used to convert the logarithmic EV to a linear intensity value. - Choosing the Base Value:
- The
base_valuefactor should be determined based on the dynamic range of your EXR image and the specific luminance values you are dealing with. - You may need to experiment with different values of
base_valueto achieve the desired separation of bright areas from the rest of the image.
- The
Let’s say you have an EXR image with a dynamic range of 12 EV, which is a common range for many high dynamic range images. In this case, you want to set a threshold value that corresponds to a certain number of EV above the middle gray level (which is often considered to be around 0.18).
Here’s an example of how you might determine a
base_valueto achieve this:# Define the dynamic range of the image in EV dynamic_range = 12 # Choose the desired number of EV above middle gray for thresholding desired_ev_above_middle_gray = 2 # Calculate the threshold value based on the desired EV above middle gray threshold_value = 0.18 * (2 ** (desired_ev_above_middle_gray / dynamic_range)) print("Threshold Value:", threshold_value) -
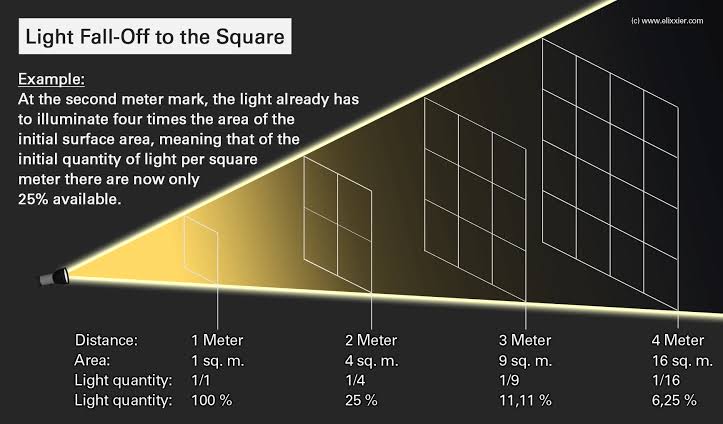
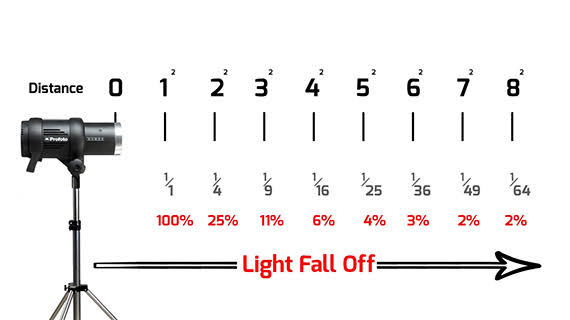
Cinematographers Blueprint 300dpi poster
Read more: Cinematographers Blueprint 300dpi posterThe 300dpi digital poster is now available to all PixelSham.com subscribers.

If you have already subscribed and wish a copy, please send me a note through the contact page.









{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Glossary of Lighting Terms – cheat sheet
-
PixelSham – Introduction to Python 2022
-
What Is The Resolution and view coverage Of The human Eye. And what distance is TV at best?
-
Photography basics: Production Rendering Resolution Charts
-
Types of AI Explained in a few Minutes – AI Glossary
-
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
-
Python and TCL: Tips and Tricks for Foundry Nuke
-
The Perils of Technical Debt – Understanding Its Impact on Security, Usability, and Stability
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
