


COMPOSITION
-
Photography basics: Depth of Field and composition
Read more: Photography basics: Depth of Field and compositionDepth of field is the range within which focusing is resolved in a photo.
Aperture has a huge affect on to the depth of field.
Changing the f-stops (f/#) of a lens will change aperture and as such the DOF.
f-stops are a just certain number which is telling you the size of the aperture. That’s how f-stop is related to aperture (and DOF).
If you increase f-stops, it will increase DOF, the area in focus (and decrease the aperture). On the other hand, decreasing the f-stop it will decrease DOF (and increase the aperture).
The red cone in the figure is an angular representation of the resolution of the system. Versus the dotted lines, which indicate the aperture coverage. Where the lines of the two cones intersect defines the total range of the depth of field.
This image explains why the longer the depth of field, the greater the range of clarity.

-
StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
Read more: StudioBinder – Roger Deakins on How to Choose a Camera Lens — Cinematography Composition Techniques
https://www.studiobinder.com/blog/camera-lens-buying-guide/
https://www.studiobinder.com/blog/e-books/camera-lenses-explained-volume-1-ebook
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/






















DESIGN
-
Realistic Avengers action figures
Read more: Realistic Avengers action figureshttp://kotaku.com/5911846/these-avengers-action-figures-look-so-real-youll-think-theyre-tiny-actors
http://www.sideshowtoy.com/?page_id=37555&ref=Avengers2012
http://www.sideshowtoy.com/?page_id=4489&sku=9017301&ref=ref=avengersLP_9017301#!prettyPhoto/0/
http://animagetoyznews.blogspot.co.nz/






COLOR
-
Sensitivity of human eye
Read more: Sensitivity of human eyehttp://www.wikilectures.eu/index.php/Spectral_sensitivity_of_the_human_eye
http://www.normankoren.com/Human_spectral_sensitivity_small.jpg
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
http://weeklysciencequiz.blogspot.com/2013/01/violet-skies-are-for-birds.html

Sensitivity of human eye Sensitivity of human eyes to light increase with the decrease in light intensity. In day-light condition, the cones cell is responding to this condition. And the eye is most sensitive at 555 nm. In darkness condition, the rod cell is responding to this condition. And the eye is most sensitive at 507 nm.
As light intensity decreases, cone function changes more effective way. And when decrease the light intensity, it prompt to accumulation of rhodopsin. Furthermore, in activates rods, it allow to respond to stimuli of light in much lower intensity.
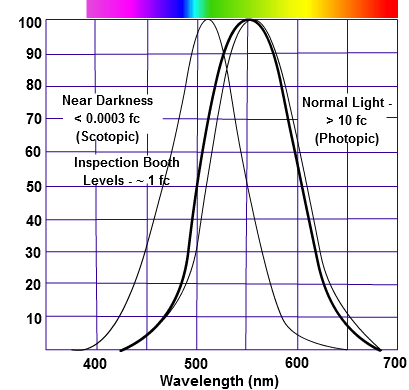
The three curves in the figure above shows the normalized response of an average human eye to various amounts of ambient light. The shift in sensitivity occurs because two types of photoreceptors called cones and rods are responsible for the eye’s response to light. The curve on the right shows the eye’s response under normal lighting conditions and this is called the photopic response. The cones respond to light under these conditions.
As mentioned previously, cones are composed of three different photo pigments that enable color perception. This curve peaks at 555 nanometers, which means that under normal lighting conditions, the eye is most sensitive to a yellowish-green color. When the light levels drop to near total darkness, the response of the eye changes significantly as shown by the scotopic response curve on the left. At this level of light, the rods are most active and the human eye is more sensitive to the light present, and less sensitive to the range of color. Rods are highly sensitive to light but are comprised of a single photo pigment, which accounts for the loss in ability to discriminate color. At this very low light level, sensitivity to blue, violet, and ultraviolet is increased, but sensitivity to yellow and red is reduced. The heavier curve in the middle represents the eye’s response at the ambient light level found in a typical inspection booth. This curve peaks at 550 nanometers, which means the eye is most sensitive to yellowish-green color at this light level. Fluorescent penetrant inspection materials are designed to fluoresce at around 550 nanometers to produce optimal sensitivity under dim lighting conditions.

-
VES Cinematic Color – Motion-Picture Color Management
Read more: VES Cinematic Color – Motion-Picture Color ManagementThis paper presents an introduction to the color pipelines behind modern feature-film visual-effects and animation.
Authored by Jeremy Selan, and reviewed by the members of the VES Technology Committee including Rob Bredow, Dan Candela, Nick Cannon, Paul Debevec, Ray Feeney, Andy Hendrickson, Gautham Krishnamurti, Sam Richards, Jordan Soles, and Sebastian Sylwan.
-
The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t See
Read more: The Forbidden colors – Red-Green & Blue-Yellow: The Stunning Colors You Can’t Seewww.livescience.com/17948-red-green-blue-yellow-stunning-colors.html

While the human eye has red, green, and blue-sensing cones, those cones are cross-wired in the retina to produce a luminance channel plus a red-green and a blue-yellow channel, and it’s data in that color space (known technically as “LAB”) that goes to the brain. That’s why we can’t perceive a reddish-green or a yellowish-blue, whereas such colors can be represented in the RGB color space used by digital cameras.
https://en.rockcontent.com/blog/the-use-of-yellow-in-data-design
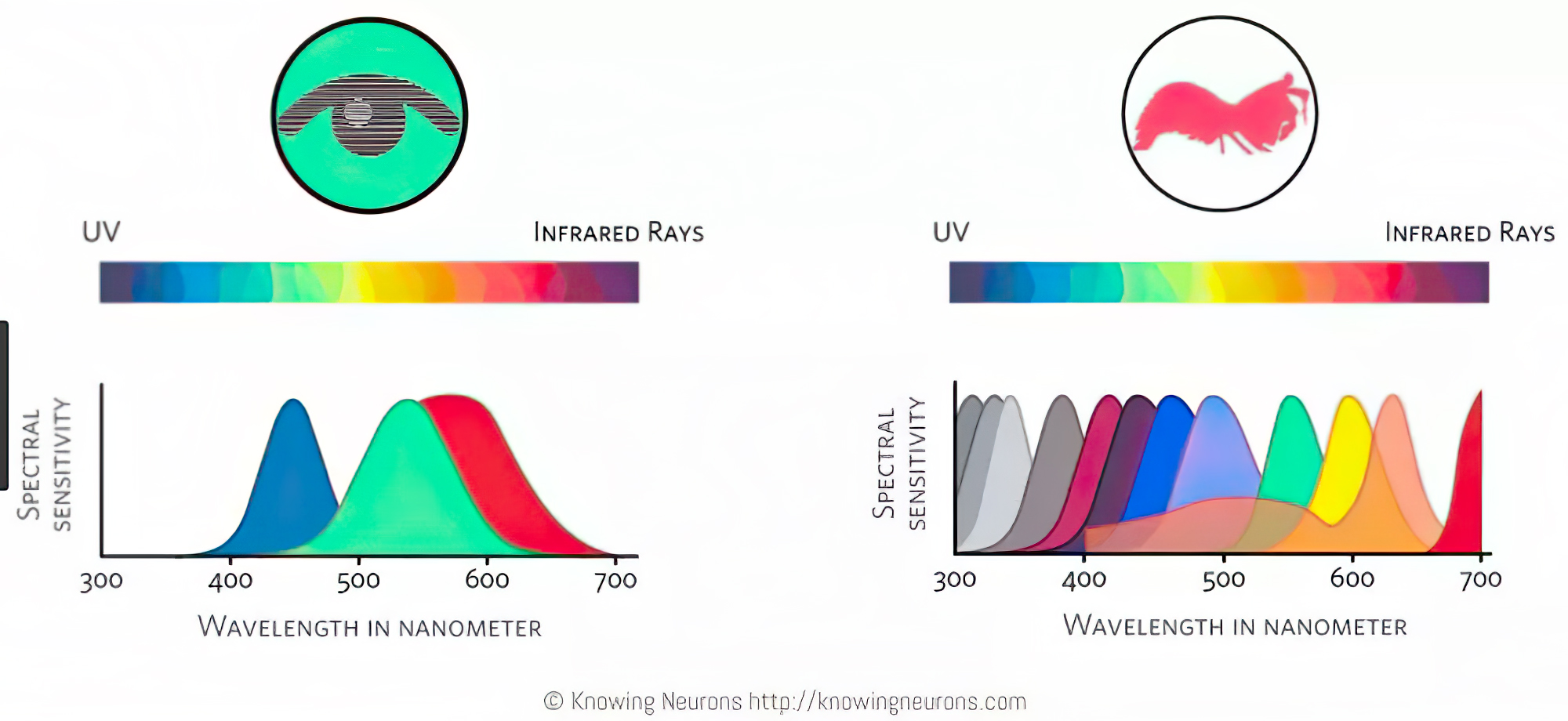
The back of the retina is covered in light-sensitive neurons known as cone cells and rod cells. There are three types of cone cells, each sensitive to different ranges of light. These ranges overlap, but for convenience the cones are referred to as blue (short-wavelength), green (medium-wavelength), and red (long-wavelength). The rod cells are primarily used in low-light situations, so we’ll ignore those for now.
When light enters the eye and hits the cone cells, the cones get excited and send signals to the brain through the visual cortex. Different wavelengths of light excite different combinations of cones to varying levels, which generates our perception of color. You can see that the red cones are most sensitive to light, and the blue cones are least sensitive. The sensitivity of green and red cones overlaps for most of the visible spectrum.

Here’s how your brain takes the signals of light intensity from the cones and turns it into color information. To see red or green, your brain finds the difference between the levels of excitement in your red and green cones. This is the red-green channel.
To get “brightness,” your brain combines the excitement of your red and green cones. This creates the luminance, or black-white, channel. To see yellow or blue, your brain then finds the difference between this luminance signal and the excitement of your blue cones. This is the yellow-blue channel.
From the calculations made in the brain along those three channels, we get four basic colors: blue, green, yellow, and red. Seeing blue is what you experience when low-wavelength light excites the blue cones more than the green and red.
Seeing green happens when light excites the green cones more than the red cones. Seeing red happens when only the red cones are excited by high-wavelength light.
Here’s where it gets interesting. Seeing yellow is what happens when BOTH the green AND red cones are highly excited near their peak sensitivity. This is the biggest collective excitement that your cones ever have, aside from seeing pure white.
Notice that yellow occurs at peak intensity in the graph to the right. Further, the lens and cornea of the eye happen to block shorter wavelengths, reducing sensitivity to blue and violet light.










LIGHTING
-
HDRI Median Cut plugin
Read more: HDRI Median Cut pluginwww.hdrlabs.com/picturenaut/plugins.html

Note. The Median Cut algorithm is typically used for color quantization, which involves reducing the number of colors in an image while preserving its visual quality. It doesn’t directly provide a way to identify the brightest areas in an image. However, if you’re interested in identifying the brightest areas, you might want to look into other methods like thresholding, histogram analysis, or edge detection, through openCV for example.
Here is an openCV example:
# bottom left coordinates = 0,0 import numpy as np import cv2 # Load the HDR or EXR image image = cv2.imread('your_image_path.exr', cv2.IMREAD_UNCHANGED) # Load as-is without modification # Calculate the luminance from the HDR channels (assuming RGB format) luminance = np.dot(image[..., :3], [0.299, 0.587, 0.114]) # Set a threshold value based on estimated EV threshold_value = 2.4 # Estimated threshold value based on 4.8 EV # Apply the threshold to identify bright areas # Theluminancearray contains the calculated luminance values for each pixel in the image. # Thethreshold_valueis a user-defined value that represents a cutoff point, separating "bright" and "dark" areas in terms of perceived luminance.thresholded = (luminance > threshold_value) * 255 # Convert the thresholded image to uint8 for contour detection thresholded = thresholded.astype(np.uint8) # Find contours of the bright areas contours, _ = cv2.findContours(thresholded, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) # Create a list to store the bounding boxes of bright areas bright_areas = [] # Iterate through contours and extract bounding boxes for contour in contours: x, y, w, h = cv2.boundingRect(contour) # Adjust y-coordinate based on bottom-left origin y_bottom_left_origin = image.shape[0] - (y + h) bright_areas.append((x, y_bottom_left_origin, x + w, y_bottom_left_origin + h)) # Store as (x1, y1, x2, y2) # Print the identified bright areas print("Bright Areas (x1, y1, x2, y2):") for area in bright_areas: print(area)More details
Luminance and Exposure in an EXR Image:
- An EXR (Extended Dynamic Range) image format is often used to store high dynamic range (HDR) images that contain a wide range of luminance values, capturing both dark and bright areas.
- Luminance refers to the perceived brightness of a pixel in an image. In an RGB image, luminance is often calculated using a weighted sum of the red, green, and blue channels, where different weights are assigned to each channel to account for human perception.
- In an EXR image, the pixel values can represent radiometrically accurate scene values, including actual radiance or irradiance levels. These values are directly related to the amount of light emitted or reflected by objects in the scene.
The luminance line is calculating the luminance of each pixel in the image using a weighted sum of the red, green, and blue channels. The three float values [0.299, 0.587, 0.114] are the weights used to perform this calculation.
These weights are based on the concept of luminosity, which aims to approximate the perceived brightness of a color by taking into account the human eye’s sensitivity to different colors. The values are often derived from the NTSC (National Television System Committee) standard, which is used in various color image processing operations.
Here’s the breakdown of the float values:
- 0.299: Weight for the red channel.
- 0.587: Weight for the green channel.
- 0.114: Weight for the blue channel.
The weighted sum of these channels helps create a grayscale image where the pixel values represent the perceived brightness. This technique is often used when converting a color image to grayscale or when calculating luminance for certain operations, as it takes into account the human eye’s sensitivity to different colors.
For the threshold, remember that the exact relationship between EV values and pixel values can depend on the tone-mapping or normalization applied to the HDR image, as well as the dynamic range of the image itself.
To establish a relationship between exposure and the threshold value, you can consider the relationship between linear and logarithmic scales:
- Linear and Logarithmic Scales:
- Exposure values in an EXR image are often represented in logarithmic scales, such as EV (exposure value). Each increment in EV represents a doubling or halving of the amount of light captured.
- Threshold values for luminance thresholding are usually linear, representing an actual luminance level.
- Conversion Between Scales:
- To establish a mathematical relationship, you need to convert between the logarithmic exposure scale and the linear threshold scale.
- One common method is to use a power function. For instance, you can use a power function to convert EV to a linear intensity value.
threshold_value = base_value * (2 ** EV)Here,
EVis the exposure value,base_valueis a scaling factor that determines the relationship between EV and threshold_value, and2 ** EVis used to convert the logarithmic EV to a linear intensity value. - Choosing the Base Value:
- The
base_valuefactor should be determined based on the dynamic range of your EXR image and the specific luminance values you are dealing with. - You may need to experiment with different values of
base_valueto achieve the desired separation of bright areas from the rest of the image.
- The
Let’s say you have an EXR image with a dynamic range of 12 EV, which is a common range for many high dynamic range images. In this case, you want to set a threshold value that corresponds to a certain number of EV above the middle gray level (which is often considered to be around 0.18).
Here’s an example of how you might determine a
base_valueto achieve this:# Define the dynamic range of the image in EV dynamic_range = 12 # Choose the desired number of EV above middle gray for thresholding desired_ev_above_middle_gray = 2 # Calculate the threshold value based on the desired EV above middle gray threshold_value = 0.18 * (2 ** (desired_ev_above_middle_gray / dynamic_range)) print("Threshold Value:", threshold_value) -
IES Light Profiles and editing software
Read more: IES Light Profiles and editing softwarehttp://www.derekjenson.com/3d-blog/ies-light-profiles
https://ieslibrary.com/en/browse#ies
https://leomoon.com/store/shaders/ies-lights-pack
https://docs.arnoldrenderer.com/display/a5afmug/ai+photometric+light
IES profiles are useful for creating life-like lighting, as they can represent the physical distribution of light from any light source.
The IES format was created by the Illumination Engineering Society, and most lighting manufacturers provide IES profile for the lights they manufacture.


-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
domeble – Hi-Resolution CGI Backplates and 360° HDRI
Read more: domeble – Hi-Resolution CGI Backplates and 360° HDRIWhen collecting hdri make sure the data supports basic metadata, such as:
- Iso
- Aperture
- Exposure time or shutter time
- Color temperature
- Color space Exposure value (what the sensor receives of the sun intensity in lux)
- 7+ brackets (with 5 or 6 being the perceived balanced exposure)
In image processing, computer graphics, and photography, high dynamic range imaging (HDRI or just HDR) is a set of techniques that allow a greater dynamic range of luminances (a Photometry measure of the luminous intensity per unit area of light travelling in a given direction. It describes the amount of light that passes through or is emitted from a particular area, and falls within a given solid angle) between the lightest and darkest areas of an image than standard digital imaging techniques or photographic methods. This wider dynamic range allows HDR images to represent more accurately the wide range of intensity levels found in real scenes ranging from direct sunlight to faint starlight and to the deepest shadows.
The two main sources of HDR imagery are computer renderings and merging of multiple photographs, which in turn are known as low dynamic range (LDR) or standard dynamic range (SDR) images. Tone Mapping (Look-up) techniques, which reduce overall contrast to facilitate display of HDR images on devices with lower dynamic range, can be applied to produce images with preserved or exaggerated local contrast for artistic effect. Photography
In photography, dynamic range is measured in Exposure Values (in photography, exposure value denotes all combinations of camera shutter speed and relative aperture that give the same exposure. The concept was developed in Germany in the 1950s) differences or stops, between the brightest and darkest parts of the image that show detail. An increase of one EV or one stop is a doubling of the amount of light.
The human response to brightness is well approximated by a Steven’s power law, which over a reasonable range is close to logarithmic, as described by the Weber�Fechner law, which is one reason that logarithmic measures of light intensity are often used as well.
HDR is short for High Dynamic Range. It’s a term used to describe an image which contains a greater exposure range than the “black” to “white” that 8 or 16-bit integer formats (JPEG, TIFF, PNG) can describe. Whereas these Low Dynamic Range images (LDR) can hold perhaps 8 to 10 f-stops of image information, HDR images can describe beyond 30 stops and stored in 32 bit images.




















{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Photography basics: Color Temperature and White Balance
-
GretagMacbeth Color Checker Numeric Values and Middle Gray
-
Python and TCL: Tips and Tricks for Foundry Nuke
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
-
Photography basics: Lumens vs Candelas (candle) vs Lux vs FootCandle vs Watts vs Irradiance vs Illuminance
-
Photography basics: Production Rendering Resolution Charts
-
Photography basics: Exposure Value vs Photographic Exposure vs Il/Luminance vs Pixel luminance measurements
-
Convert 2D Images to 3D Models
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
