


COMPOSITION
-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)














DESIGN
-
How to paint a boardgame miniatures
Read more: How to paint a boardgame miniatures
Steps:
- soap wash cleaning
- primer
- base-coat layer (black/white)
- detailing
- washing aka shade (could be done after highlighting)
- highlights aka dry brushing (could be done after washing)
- varnish (gloss/satin/matte)









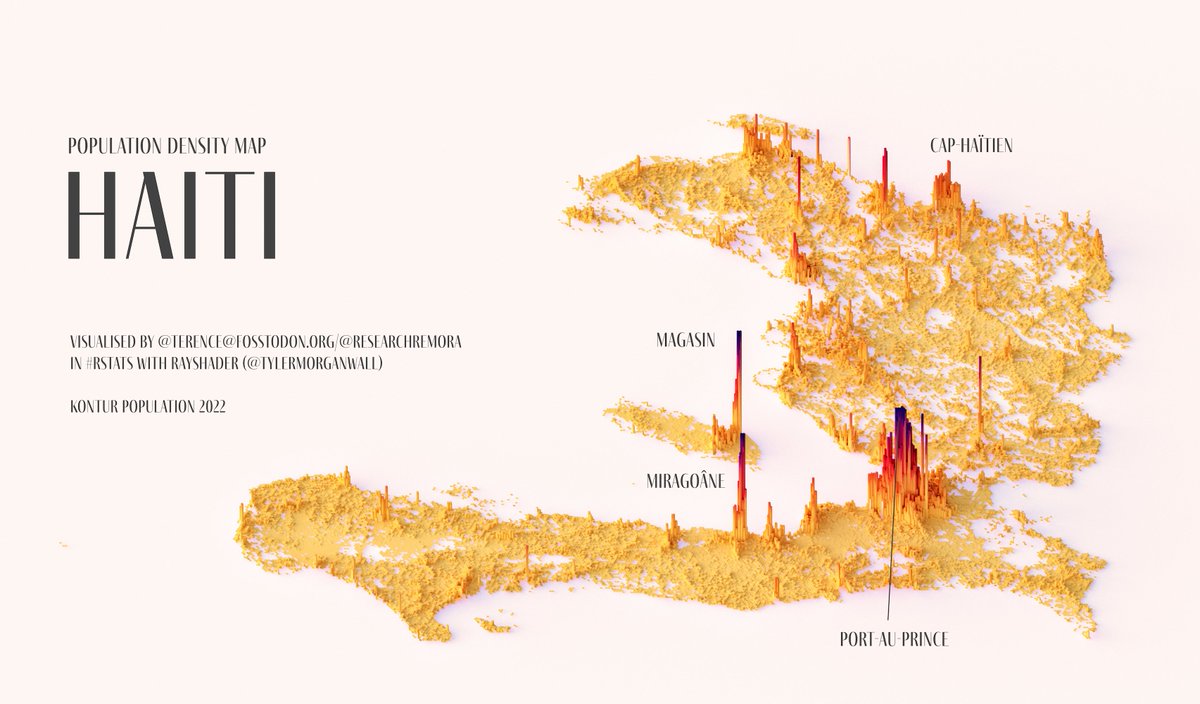
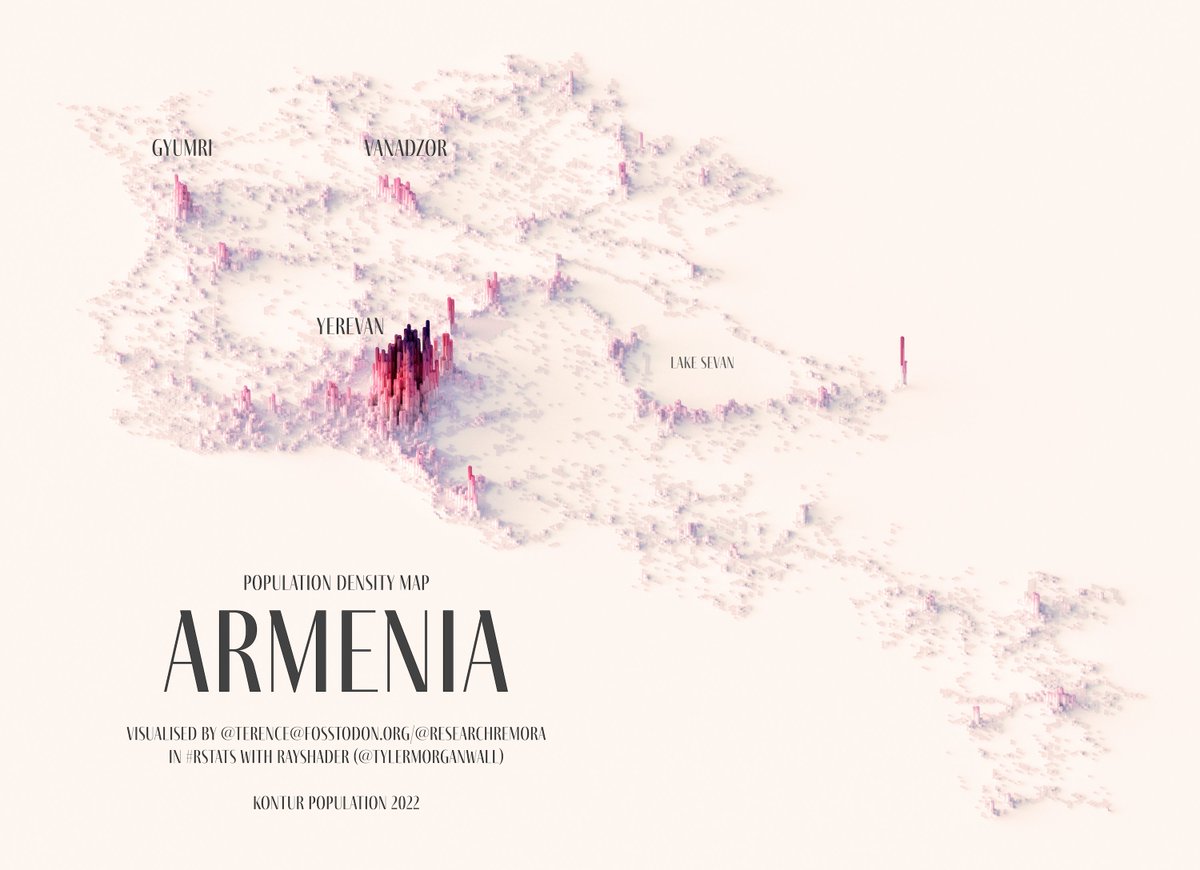

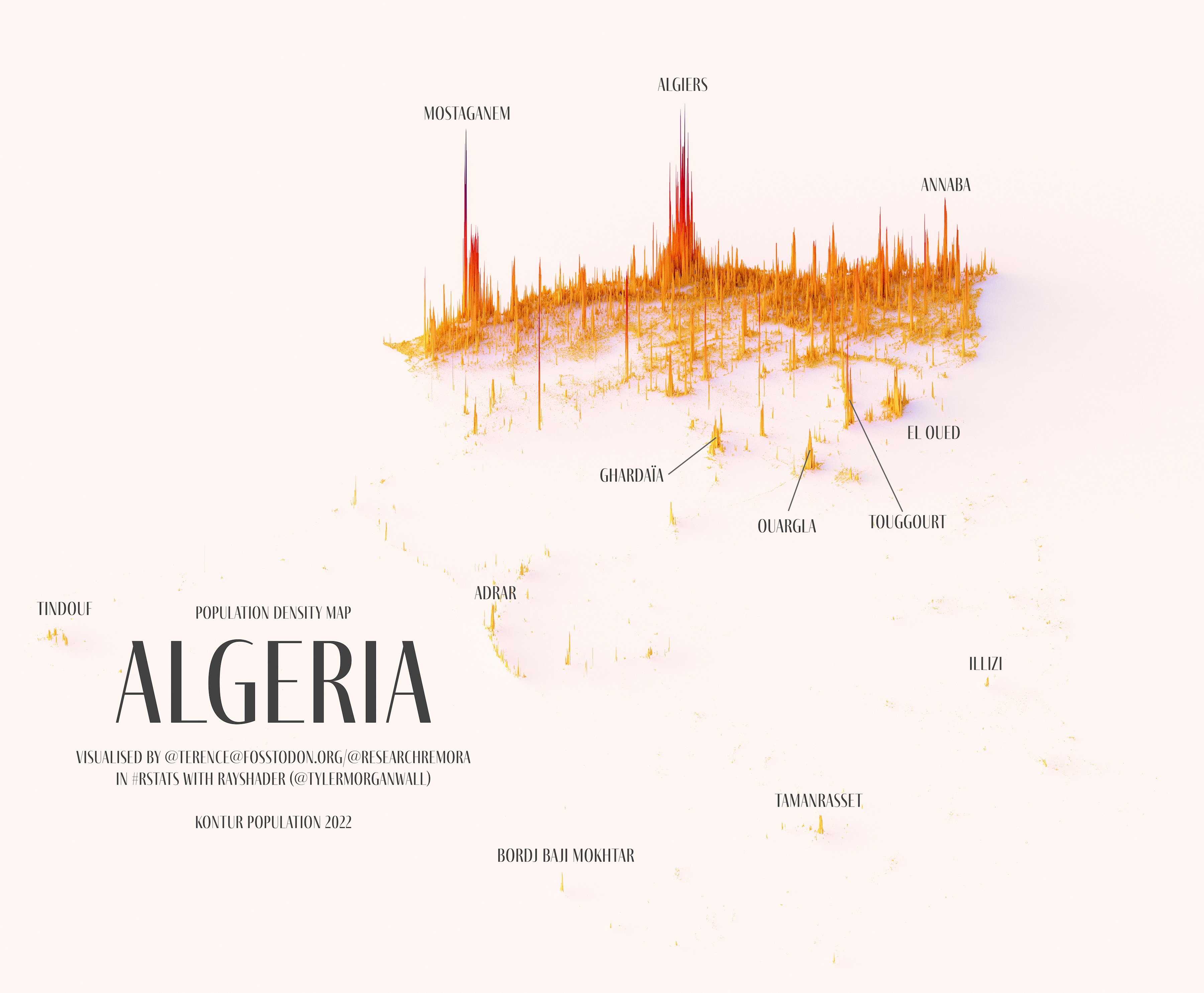




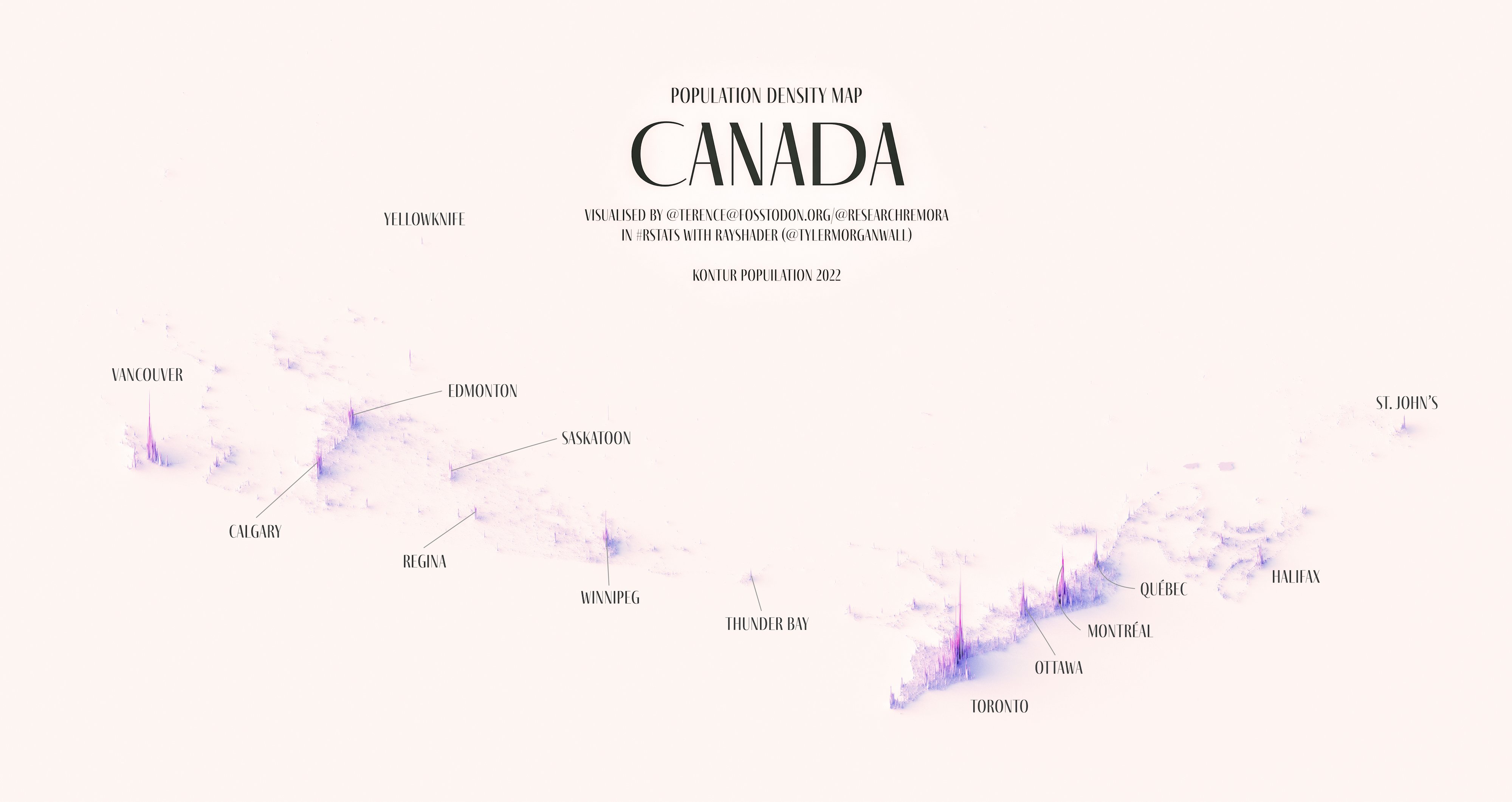




































COLOR
-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements

-
Björn Ottosson – OKlch color space
Read more: Björn Ottosson – OKlch color spaceBjörn Ottosson proposed OKlch in 2020 to create a color space that can closely mimic how color is perceived by the human eye, predicting perceived lightness, chroma, and hue.
The OK in OKLCH stands for Optimal Color.
- L: Lightness (the perceived brightness of the color)
- C: Chroma (the intensity or saturation of the color)
- H: Hue (the actual color, such as red, blue, green, etc.)

Also read:
-
Photography Basics : Spectral Sensitivity Estimation Without a Camera
Read more: Photography Basics : Spectral Sensitivity Estimation Without a Camerahttps://color-lab-eilat.github.io/Spectral-sensitivity-estimation-web/
A number of problems in computer vision and related fields would be mitigated if camera spectral sensitivities were known. As consumer cameras are not designed for high-precision visual tasks, manufacturers do not disclose spectral sensitivities. Their estimation requires a costly optical setup, which triggered researchers to come up with numerous indirect methods that aim to lower cost and complexity by using color targets. However, the use of color targets gives rise to new complications that make the estimation more difficult, and consequently, there currently exists no simple, low-cost, robust go-to method for spectral sensitivity estimation that non-specialized research labs can adopt. Furthermore, even if not limited by hardware or cost, researchers frequently work with imagery from multiple cameras that they do not have in their possession.
To provide a practical solution to this problem, we propose a framework for spectral sensitivity estimation that not only does not require any hardware (including a color target), but also does not require physical access to the camera itself. Similar to other work, we formulate an optimization problem that minimizes a two-term objective function: a camera-specific term from a system of equations, and a universal term that bounds the solution space.
Different than other work, we utilize publicly available high-quality calibration data to construct both terms. We use the colorimetric mapping matrices provided by the Adobe DNG Converter to formulate the camera-specific system of equations, and constrain the solutions using an autoencoder trained on a database of ground-truth curves. On average, we achieve reconstruction errors as low as those that can arise due to manufacturing imperfections between two copies of the same camera. We provide predicted sensitivities for more than 1,000 cameras that the Adobe DNG Converter currently supports, and discuss which tasks can become trivial when camera responses are available.



-
RawTherapee – a free, open source, cross-platform raw image and HDRi processing program
Read more: RawTherapee – a free, open source, cross-platform raw image and HDRi processing program5.10 of this tool includes excellent tools to clean up cr2 and cr3 used on set to support HDRI processing.
Converting raw to AcesCG 32 bit tiffs with metadata.


-
What light is best to illuminate gems for resale
Read more: What light is best to illuminate gems for resalewww.palagems.com/gem-lighting2
Artificial light sources, not unlike the diverse phases of natural light, vary considerably in their properties. As a result, some lamps render an object’s color better than others do.
The most important criterion for assessing the color-rendering ability of any lamp is its spectral power distribution curve.
Natural daylight varies too much in strength and spectral composition to be taken seriously as a lighting standard for grading and dealing colored stones. For anything to be a standard, it must be constant in its properties, which natural light is not.
For dealers in particular to make the transition from natural light to an artificial light source, that source must offer:
1- A degree of illuminance at least as strong as the common phases of natural daylight.
2- Spectral properties identical or comparable to a phase of natural daylight.A source combining these two things makes gems appear much the same as when viewed under a given phase of natural light. From the viewpoint of many dealers, this corresponds to a naturalappearance.
The 6000° Kelvin xenon short-arc lamp appears closest to meeting the criteria for a standard light source. Besides the strong illuminance this lamp affords, its spectrum is very similar to CIE standard illuminants of similar color temperature.


-
OLED vs QLED – What TV is better?
Read more: OLED vs QLED – What TV is better?
Supported by LG, Philips, Panasonic and Sony sell the OLED system TVs.
OLED stands for “organic light emitting diode.”
It is a fundamentally different technology from LCD, the major type of TV today.
OLED is “emissive,” meaning the pixels emit their own light.Samsung is branding its best TVs with a new acronym: “QLED”
QLED (according to Samsung) stands for “quantum dot LED TV.”
It is a variation of the common LED LCD, adding a quantum dot film to the LCD “sandwich.”
QLED, like LCD, is, in its current form, “transmissive” and relies on an LED backlight.OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.
QLED, as an improvement over OLED, significantly improves the picture quality. QLED can produce an even wider range of colors than OLED, which says something about this new tech. QLED is also known to produce up to 40% higher luminance efficiency than OLED technology. Further, many tests conclude that QLED is far more efficient in terms of power consumption than its predecessor, OLED.

When analyzing TVs color, it may be beneficial to consider at least 3 elements:
“Color Depth”, “Color Gamut”, and “Dynamic Range”.Color Depth (or “Bit-Depth”, e.g. 8-bit, 10-bit, 12-bit) determines how many distinct color variations (tones/shades) can be viewed on a given display.
Color Gamut (e.g. WCG) determines which specific colors can be displayed from a given “Color Space” (Rec.709, Rec.2020, DCI-P3) (i.e. the color range).
Dynamic Range (SDR, HDR) determines the luminosity range of a specific color – from its darkest shade (or tone) to its brightest.
The overall brightness range of a color will be determined by a display’s “contrast ratio”, that is, the ratio of luminance between the darkest black that can be produced and the brightest white.
Color Volume is the “Color Gamut” + the “Dynamic/Luminosity Range”.
A TV’s Color Volume will not only determine which specific colors can be displayed (the color range) but also that color’s luminosity range, which will have an affect on its “brightness”, and “colorfulness” (intensity and saturation).The better the colour volume in a TV, the closer to life the colours appear.
QLED TV can express nearly all of the colours in the DCI-P3 colour space, and of those colours, express 100% of the colour volume, thereby producing an incredible range of colours.
With OLED TV, when the image is too bright, the percentage of the colours in the colour volume produced by the TV drops significantly. The colours get washed out and can only express around 70% colour volume, making the picture quality drop too.
Note. OLED TV uses organic material, so it may lose colour expression as it ages.
Resources for more reading and comparison below
www.avsforum.com/forum/166-lcd-flat-panel-displays/2812161-what-color-volume.html
www.newtechnologytv.com/qled-vs-oled/
news.samsung.com/za/qled-tv-vs-oled-tv
www.cnet.com/news/qled-vs-oled-samsungs-tv-tech-and-lgs-tv-tech-are-not-the-same/

-
Tim Kang – calibrated white light values in sRGB color space
Read more: Tim Kang – calibrated white light values in sRGB color space8bit sRGB encoded
2000K 255 139 22
2700K 255 172 89
3000K 255 184 109
3200K 255 190 122
4000K 255 211 165
4300K 255 219 178
D50 255 235 205
D55 255 243 224
D5600 255 244 227
D6000 255 249 240
D65 255 255 255
D10000 202 221 255
D20000 166 196 2558bit Rec709 Gamma 2.4
2000K 255 145 34
2700K 255 177 97
3000K 255 187 117
3200K 255 193 129
4000K 255 214 170
4300K 255 221 182
D50 255 236 208
D55 255 243 226
D5600 255 245 229
D6000 255 250 241
D65 255 255 255
D10000 204 222 255
D20000 170 199 2558bit Display P3 encoded
2000K 255 154 63
2700K 255 185 109
3000K 255 195 127
3200K 255 201 138
4000K 255 219 176
4300K 255 225 187
D50 255 239 212
D55 255 245 228
D5600 255 246 231
D6000 255 251 242
D65 255 255 255
D10000 208 223 255
D20000 175 199 25510bit Rec2020 PQ (100 nits)
2000K 520 435 273
2700K 520 466 358
3000K 520 475 384
3200K 520 480 399
4000K 520 495 446
4300K 520 500 458
D50 520 510 482
D55 520 514 497
D5600 520 514 500
D6000 520 517 509
D65 520 520 520
D10000 479 489 520
D20000 448 464 520







LIGHTING
-
Rendering – BRDF – Bidirectional reflectance distribution function
Read more: Rendering – BRDF – Bidirectional reflectance distribution functionhttp://en.wikipedia.org/wiki/Bidirectional_reflectance_distribution_function
The bidirectional reflectance distribution function is a four-dimensional function that defines how light is reflected at an opaque surface
http://www.cs.ucla.edu/~zhu/tutorial/An_Introduction_to_BRDF-Based_Lighting.pdf
In general, when light interacts with matter, a complicated light-matter dynamic occurs. This interaction depends on the physical characteristics of the light as well as the physical composition and characteristics of the matter.
That is, some of the incident light is reflected, some of the light is transmitted, and another portion of the light is absorbed by the medium itself.
A BRDF describes how much light is reflected when light makes contact with a certain material. Similarly, a BTDF (Bi-directional Transmission Distribution Function) describes how much light is transmitted when light makes contact with a certain material
http://www.cs.princeton.edu/~smr/cs348c-97/surveypaper.html
It is difficult to establish exactly how far one should go in elaborating the surface model. A truly complete representation of the reflective behavior of a surface might take into account such phenomena as polarization, scattering, fluorescence, and phosphorescence, all of which might vary with position on the surface. Therefore, the variables in this complete function would be:
incoming and outgoing angle incoming and outgoing wavelength incoming and outgoing polarization (both linear and circular) incoming and outgoing position (which might differ due to subsurface scattering) time delay between the incoming and outgoing light ray
-
Terminators and Iron Men: HDRI, Image-based lighting and physical shading at ILM – Siggraph 2010
Read more: Terminators and Iron Men: HDRI, Image-based lighting and physical shading at ILM – Siggraph 2010 -
Convert between light exposure and intensity
Read more: Convert between light exposure and intensityimport math,sys def Exposure2Intensity(exposure): exp = float(exposure) result = math.pow(2,exp) print(result) Exposure2Intensity(0) def Intensity2Exposure(intensity): inarg = float(intensity) if inarg == 0: print("Exposure of zero intensity is undefined.") return if inarg < 1e-323: inarg = max(inarg, 1e-323) print("Exposure of negative intensities is undefined. Clamping to a very small value instead (1e-323)") result = math.log(inarg, 2) print(result) Intensity2Exposure(0.1) -
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing











![[gamma correction test]](http://www.madore.org/~david/misc/color/gammatest.png "sRGB gamma correction test")




COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Daniele Tosti Interview for the magazine InCG, Taiwan, Issue 28, 201609
-
Most common ways to smooth 3D prints
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
-
Sensitivity of human eye
-
Photography basics: Shutter angle and shutter speed and motion blur
-
Godot Cheat Sheets
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
