


COMPOSITION
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/


-
HuggingFace ai-comic-factory – a FREE AI Comic Book Creator
Read more: HuggingFace ai-comic-factory – a FREE AI Comic Book Creatorhttps://huggingface.co/spaces/jbilcke-hf/ai-comic-factory

this is the epic story of a group of talented digital artists trying to overcame daily technical challenges to achieve incredibly photorealistic projects of monsters and aliens















DESIGN
-
COLOR
-
If a blind person gained sight, could they recognize objects previously touched?
Read more: If a blind person gained sight, could they recognize objects previously touched?Blind people who regain their sight may find themselves in a world they don’t immediately comprehend. “It would be more like a sighted person trying to rely on tactile information,” Moore says.
Learning to see is a developmental process, just like learning language, Prof Cathleen Moore continues. “As far as vision goes, a three-and-a-half year old child is already a well-calibrated system.”
-
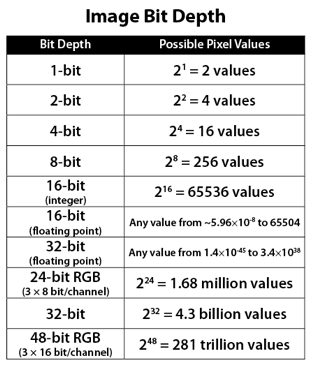
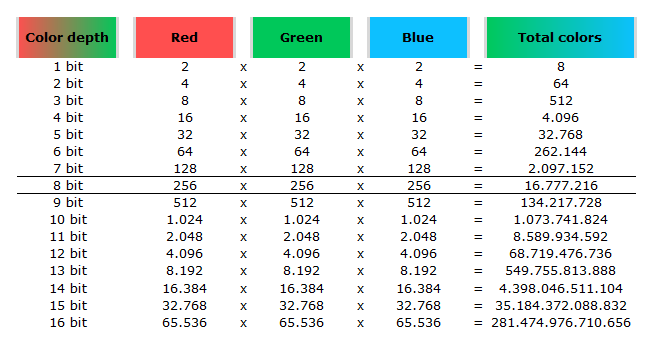
Image rendering bit depth
Read more: Image rendering bit depthThe terms 8-bit, 16-bit, 16-bit float, and 32-bit refer to different data formats used to store and represent image information, as bits per pixel.
https://en.wikipedia.org/wiki/Color_depth
In color technology, color depth also known as bit depth, is either the number of bits used to indicate the color of a single pixel, OR the number of bits used for each color component of a single pixel.
When referring to a pixel, the concept can be defined as bits per pixel (bpp).
When referring to a color component, the concept can be defined as bits per component, bits per channel, bits per color (all three abbreviated bpc), and also bits per pixel component, bits per color channel or bits per sample (bps). Modern standards tend to use bits per component, but historical lower-depth systems used bits per pixel more often.
Color depth is only one aspect of color representation, expressing the precision with which the amount of each primary can be expressed; the other aspect is how broad a range of colors can be expressed (the gamut). The definition of both color precision and gamut is accomplished with a color encoding specification which assigns a digital code value to a location in a color space.

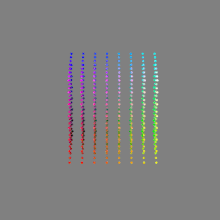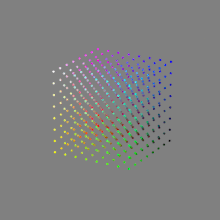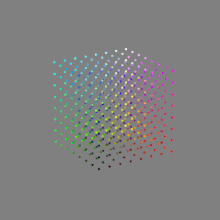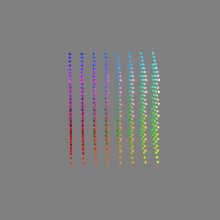
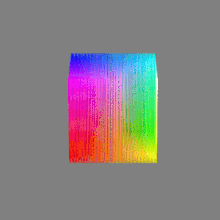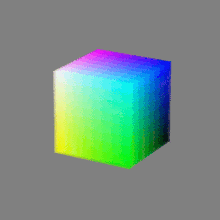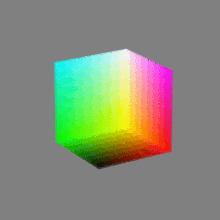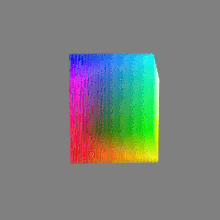
Here’s a simple explanation of each.
8-bit images (i.e. 24 bits per pixel for a color image) are considered Low Dynamic Range.
They can store around 5 stops of light and each pixel carry a value from 0 (black) to 255 (white).
As a comparison, DSLR cameras can capture ~12-15 stops of light and they use RAW files to store the information.16-bit: This format is commonly referred to as “half-precision.” It uses 16 bits of data to represent color values for each pixel. With 16 bits, you can have 65,536 discrete levels of color, allowing for relatively high precision and smooth gradients. However, it has a limited dynamic range, meaning it cannot accurately represent extremely bright or dark values. It is commonly used for regular images and textures.
16-bit float: This format is an extension of the 16-bit format but uses floating-point numbers instead of fixed integers. Floating-point numbers allow for more precise calculations and a larger dynamic range. In this case, the 16 bits are used to store both the color value and the exponent, which controls the range of values that can be represented. The 16-bit float format provides better accuracy and a wider dynamic range than regular 16-bit, making it useful for high-dynamic-range imaging (HDRI) and computations that require more precision.
32-bit: (i.e. 96 bits per pixel for a color image) are considered High Dynamic Range. This format, also known as “full-precision” or “float,” uses 32 bits to represent color values and offers the highest precision and dynamic range among the three options. With 32 bits, you have a significantly larger number of discrete levels, allowing for extremely accurate color representation, smooth gradients, and a wide range of brightness values. It is commonly used for professional rendering, visual effects, and scientific applications where maximum precision is required.
Bits and HDR coverage
High Dynamic Range (HDR) images are designed to capture a wide range of luminance values, from the darkest shadows to the brightest highlights, in order to reproduce a scene with more accuracy and detail. The bit depth of an image refers to the number of bits used to represent each pixel’s color information. When comparing 32-bit float and 16-bit float HDR images, the drop in accuracy primarily relates to the precision of the color information.
A 32-bit float HDR image offers a higher level of precision compared to a 16-bit float HDR image. In a 32-bit float format, each color channel (red, green, and blue) is represented by 32 bits, allowing for a larger range of values to be stored. This increased precision enables the image to retain more details and subtleties in color and luminance.
On the other hand, a 16-bit float HDR image utilizes 16 bits per color channel, resulting in a reduced range of values that can be represented. This lower precision leads to a loss of fine details and color nuances, especially in highly contrasted areas of the image where there are significant differences in luminance.
The drop in accuracy between 32-bit and 16-bit float HDR images becomes more noticeable as the exposure range of the scene increases. Exposure range refers to the span between the darkest and brightest areas of an image. In scenes with a limited exposure range, where the luminance differences are relatively small, the loss of accuracy may not be as prominent or perceptible. These images usually are around 8-10 exposure levels.
However, in scenes with a wide exposure range, such as a landscape with deep shadows and bright highlights, the reduced precision of a 16-bit float HDR image can result in visible artifacts like color banding, posterization, and loss of detail in both shadows and highlights. The image may exhibit abrupt transitions between tones or colors, which can appear unnatural and less realistic.
To provide a rough estimate, it is often observed that exposure values beyond approximately ±6 to ±8 stops from the middle gray (18% reflectance) may be more prone to accuracy issues in a 16-bit float format. This range may vary depending on the specific implementation and encoding scheme used.
To summarize, the drop in accuracy between 32-bit and 16-bit float HDR images is mainly related to the reduced precision of color information. This decrease in precision becomes more apparent in scenes with a wide exposure range, affecting the representation of fine details and leading to visible artifacts in the image.
In practice, this means that exposure values beyond a certain range will experience a loss of accuracy and detail when stored in a 16-bit float format. The exact range at which this loss occurs depends on the encoding scheme and the specific implementation. However, in general, extremely bright or extremely dark values that fall outside the representable range may be subject to quantization errors, resulting in loss of detail, banding, or other artifacts.
HDRs used for lighting purposes are usually slightly convolved to improve on sampling speed and removing specular artefacts. To that extent, 16 bit float HDRIs tend to me most used in CG cycles.

-
HDR and Color
Read more: HDR and Colorhttps://www.soundandvision.com/content/nits-and-bits-hdr-and-color
In HD we often refer to the range of available colors as a color gamut. Such a color gamut is typically plotted on a two-dimensional diagram, called a CIE chart, as shown in at the top of this blog. Each color is characterized by its x/y coordinates.

Good enough for government work, perhaps. But for HDR, with its higher luminance levels and wider color, the gamut becomes three-dimensional.

For HDR the color gamut therefore becomes a characteristic we now call the color volume. It isn’t easy to show color volume on a two-dimensional medium like the printed page or a computer screen, but one method is shown below. As the luminance becomes higher, the picture eventually turns to white. As it becomes darker, it fades to black. The traditional color gamut shown on the CIE chart is simply a slice through this color volume at a selected luminance level, such as 50%.
Three different color volumes—we still refer to them as color gamuts though their third dimension is important—are currently the most significant. The first is BT.709 (sometimes referred to as Rec.709), the color gamut used for pre-UHD/HDR formats, including standard HD.
The largest is known as BT.2020; it encompasses (roughly) the range of colors visible to the human eye (though ET might find it insufficient!).
Between these two is the color gamut used in digital cinema, known as DCI-P3.

sRGB

D65

-
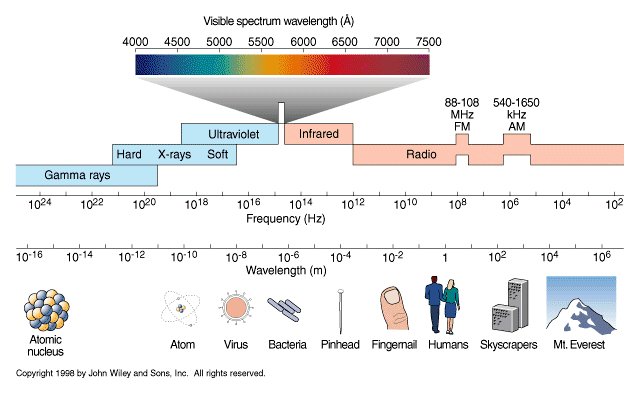
Sensitivity of human eye
Read more: Sensitivity of human eyehttp://www.wikilectures.eu/index.php/Spectral_sensitivity_of_the_human_eye
http://www.normankoren.com/Human_spectral_sensitivity_small.jpg
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
http://weeklysciencequiz.blogspot.com/2013/01/violet-skies-are-for-birds.html

Sensitivity of human eye Sensitivity of human eyes to light increase with the decrease in light intensity. In day-light condition, the cones cell is responding to this condition. And the eye is most sensitive at 555 nm. In darkness condition, the rod cell is responding to this condition. And the eye is most sensitive at 507 nm.
As light intensity decreases, cone function changes more effective way. And when decrease the light intensity, it prompt to accumulation of rhodopsin. Furthermore, in activates rods, it allow to respond to stimuli of light in much lower intensity.
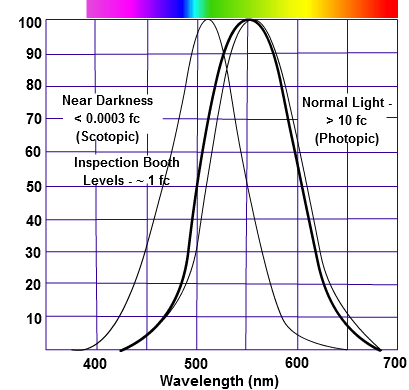
The three curves in the figure above shows the normalized response of an average human eye to various amounts of ambient light. The shift in sensitivity occurs because two types of photoreceptors called cones and rods are responsible for the eye’s response to light. The curve on the right shows the eye’s response under normal lighting conditions and this is called the photopic response. The cones respond to light under these conditions.
As mentioned previously, cones are composed of three different photo pigments that enable color perception. This curve peaks at 555 nanometers, which means that under normal lighting conditions, the eye is most sensitive to a yellowish-green color. When the light levels drop to near total darkness, the response of the eye changes significantly as shown by the scotopic response curve on the left. At this level of light, the rods are most active and the human eye is more sensitive to the light present, and less sensitive to the range of color. Rods are highly sensitive to light but are comprised of a single photo pigment, which accounts for the loss in ability to discriminate color. At this very low light level, sensitivity to blue, violet, and ultraviolet is increased, but sensitivity to yellow and red is reduced. The heavier curve in the middle represents the eye’s response at the ambient light level found in a typical inspection booth. This curve peaks at 550 nanometers, which means the eye is most sensitive to yellowish-green color at this light level. Fluorescent penetrant inspection materials are designed to fluoresce at around 550 nanometers to produce optimal sensitivity under dim lighting conditions.

-
What causes color
Read more: What causes colorwww.webexhibits.org/causesofcolor/5.html
Water itself has an intrinsic blue color that is a result of its molecular structure and its behavior.
-
Photography basics: Color Temperature and White Balance
Read more: Photography basics: Color Temperature and White Balance

Color Temperature of a light source describes the spectrum of light which is radiated from a theoretical “blackbody” (an ideal physical body that absorbs all radiation and incident light – neither reflecting it nor allowing it to pass through) with a given surface temperature.
https://en.wikipedia.org/wiki/Color_temperature
Or. Most simply it is a method of describing the color characteristics of light through a numerical value that corresponds to the color emitted by a light source, measured in degrees of Kelvin (K) on a scale from 1,000 to 10,000.
More accurately. The color temperature of a light source is the temperature of an ideal backbody that radiates light of comparable hue to that of the light source.
As such, the color temperature of a light source is a numerical measurement of its color appearance. It is based on the principle that any object will emit light if it is heated to a high enough temperature, and that the color of that light will shift in a predictable manner as the temperature is increased. The system is based on the color changes of a theoretical “blackbody radiator” as it is heated from a cold black to a white hot state.
So, why do we measure the hue of the light as a “temperature”? This was started in the late 1800s, when the British physicist William Kelvin heated a block of carbon. It glowed in the heat, producing a range of different colors at different temperatures. The black cube first produced a dim red light, increasing to a brighter yellow as the temperature went up, and eventually produced a bright blue-white glow at the highest temperatures. In his honor, Color Temperatures are measured in degrees Kelvin, which are a variation on Centigrade degrees. Instead of starting at the temperature water freezes, the Kelvin scale starts at “absolute zero,” which is -273 Centigrade.
More about black bodies here: https://www.pixelsham.com/2013/03/14/black-body-color

Details in the post
-
About color: What is a LUT
Read more: About color: What is a LUThttp://www.lightillusion.com/luts.html
https://www.shutterstock.com/blog/how-use-luts-color-grading
A LUT (Lookup Table) is essentially the modifier between two images, the original image and the displayed image, based on a mathematical formula. Basically conversion matrices of different complexities. There are different types of LUTS – viewing, transform, calibration, 1D and 3D.


-
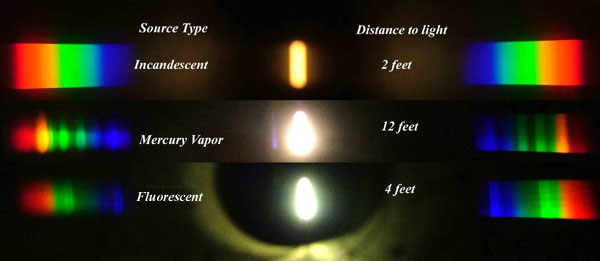
Space bodies’ components and light spectroscopy
Read more: Space bodies’ components and light spectroscopywww.plutorules.com/page-111-space-rocks.html
This help’s us understand the composition of components in/on solar system bodies.
Dips in the observed light spectrum, also known as, lines of absorption occur as gasses absorb energy from light at specific points along the light spectrum.
These dips or darkened zones (lines of absorption) leave a finger print which identify elements and compounds.
In this image the dark absorption bands appear as lines of emission which occur as the result of emitted not reflected (absorbed) light.
Lines of absorption
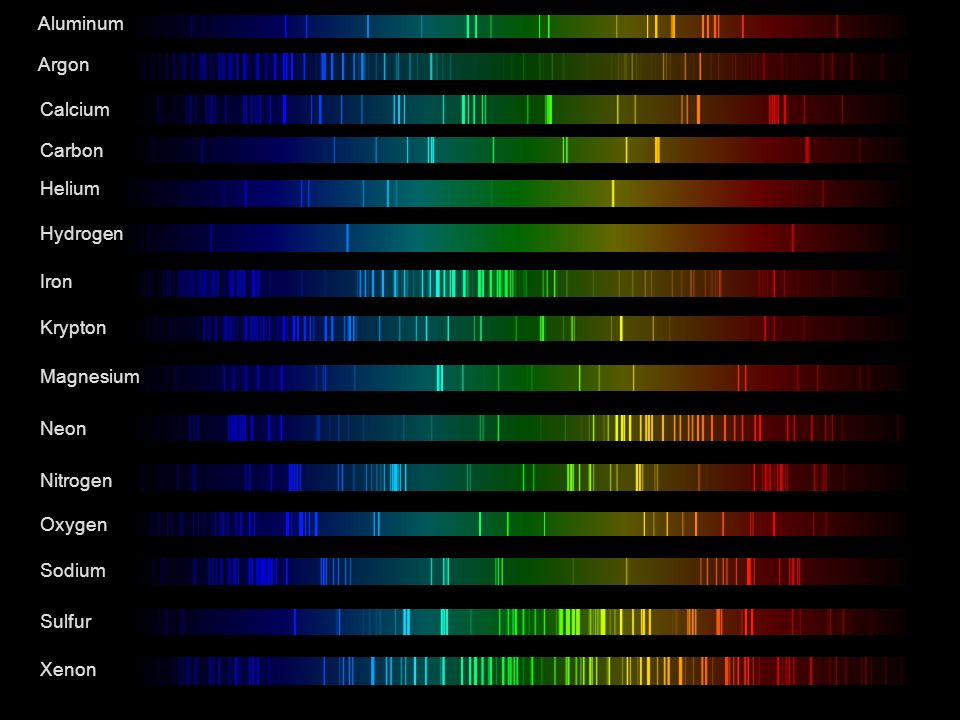 Lines of emission
Lines of emission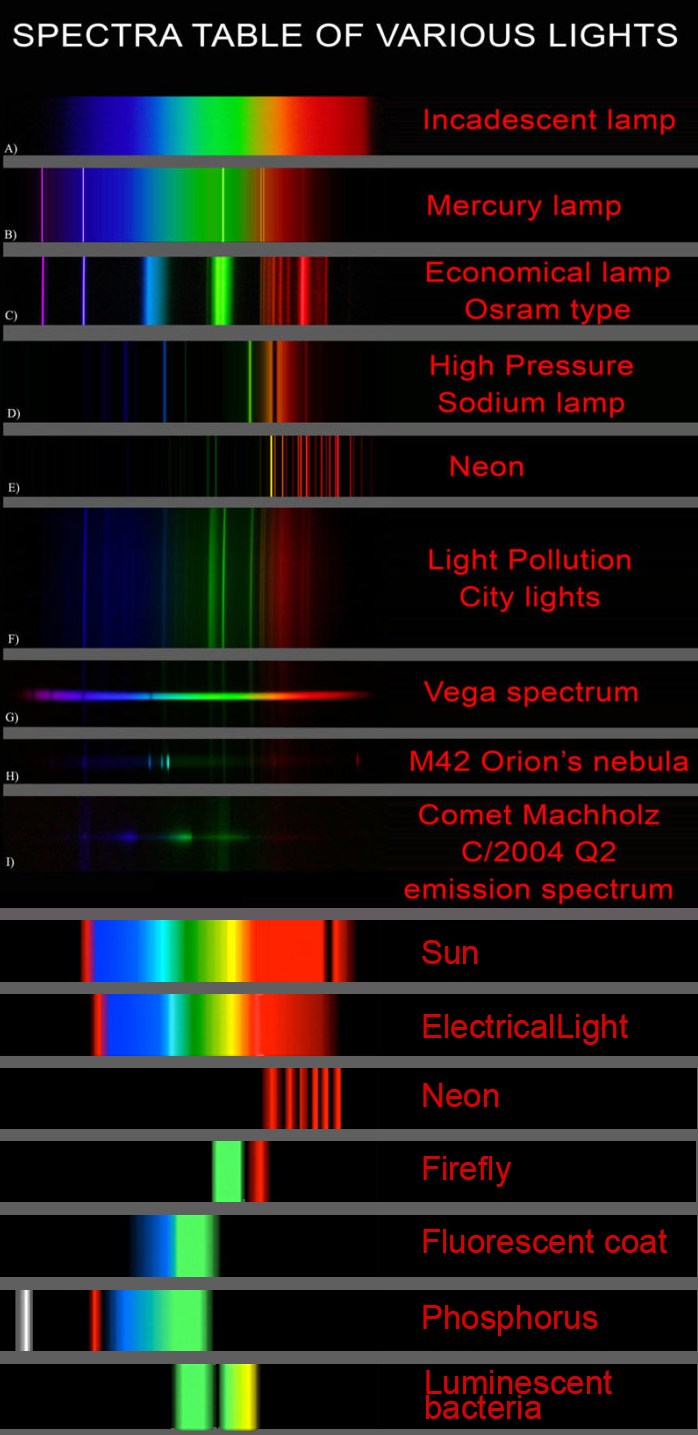


-
Scene Referred vs Display Referred color workflows
Read more: Scene Referred vs Display Referred color workflowsDisplay Referred it is tied to the target hardware, as such it bakes color requirements into every type of media output request.
Scene Referred uses a common unified wide gamut and targeting audience through CDL and DI libraries instead.
So that color information stays untouched and only “transformed” as/when needed.



Sources:
– Victor Perez – Color Management Fundamentals & ACES Workflows in Nuke
– https://z-fx.nl/ColorspACES.pdf
– Wicus
LIGHTING
-
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”

-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-


































{kind=link}
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Matt Gray – How to generate a profitable business
-
UV maps
-
Gamma correction
-
Alejandro Villabón and Rafał Kaniewski – Recover Highlights With 8-Bit to High Dynamic Range Half Float Copycat – Nuke
-
Photography basics: How Exposure Stops (Aperture, Shutter Speed, and ISO) Affect Your Photos – cheat sheet cards
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
-
Convert 2D Images to 3D Models
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
