


COMPOSITION
-
SlowMoVideo – How to make a slow motion shot with the open source program
Read more: SlowMoVideo – How to make a slow motion shot with the open source programhttp://slowmovideo.granjow.net/
slowmoVideo is an OpenSource program that creates slow-motion videos from your footage.
Slow motion cinematography is the result of playing back frames for a longer duration than they were exposed. For example, if you expose 240 frames of film in one second, then play them back at 24 fps, the resulting movie is 10 times longer (slower) than the original filmed event….
Film cameras are relatively simple mechanical devices that allow you to crank up the speed to whatever rate the shutter and pull-down mechanism allow. Some film cameras can operate at 2,500 fps or higher (although film shot in these cameras often needs some readjustment in postproduction). Video, on the other hand, is always captured, recorded, and played back at a fixed rate, with a current limit around 60fps. This makes extreme slow motion effects harder to achieve (and less elegant) on video, because slowing down the video results in each frame held still on the screen for a long time, whereas with high-frame-rate film there are plenty of frames to fill the longer durations of time. On video, the slow motion effect is more like a slide show than smooth, continuous motion.
One obvious solution is to shoot film at high speed, then transfer it to video (a case where film still has a clear advantage, sorry George). Another possibility is to cross dissolve or blur from one frame to the next. This adds a smooth transition from one still frame to the next. The blur reduces the sharpness of the image, and compared to slowing down images shot at a high frame rate, this is somewhat of a cheat. However, there isn’t much you can do about it until video can be recorded at much higher rates. Of course, many film cameras can’t shoot at high frame rates either, so the whole super-slow-motion endeavor is somewhat specialized no matter what medium you are using. (There are some high speed digital cameras available now that allow you to capture lots of digital frames directly to your computer, so technology is starting to catch up with film. However, this feature isn’t going to appear in consumer camcorders any time soon.)
-
Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental process
Read more: Christopher Butler – Understanding the Eye-Mind Connection – Vision is a mental processhttps://www.chrbutler.com/understanding-the-eye-mind-connection
The intricate relationship between the eyes and the brain, often termed the eye-mind connection, reveals that vision is predominantly a cognitive process. This understanding has profound implications for fields such as design, where capturing and maintaining attention is paramount. This essay delves into the nuances of visual perception, the brain’s role in interpreting visual data, and how this knowledge can be applied to effective design strategies.
This cognitive aspect of vision is evident in phenomena such as optical illusions, where the brain interprets visual information in a way that contradicts physical reality. These illusions underscore that what we “see” is not merely a direct recording of the external world but a constructed experience shaped by cognitive processes.
Understanding the cognitive nature of vision is crucial for effective design. Designers must consider how the brain processes visual information to create compelling and engaging visuals. This involves several key principles:
- Attention and Engagement
- Visual Hierarchy
- Cognitive Load Management
- Context and Meaning
-
Key/Fill ratios and scene composition using false colors
Read more: Key/Fill ratios and scene composition using false colors
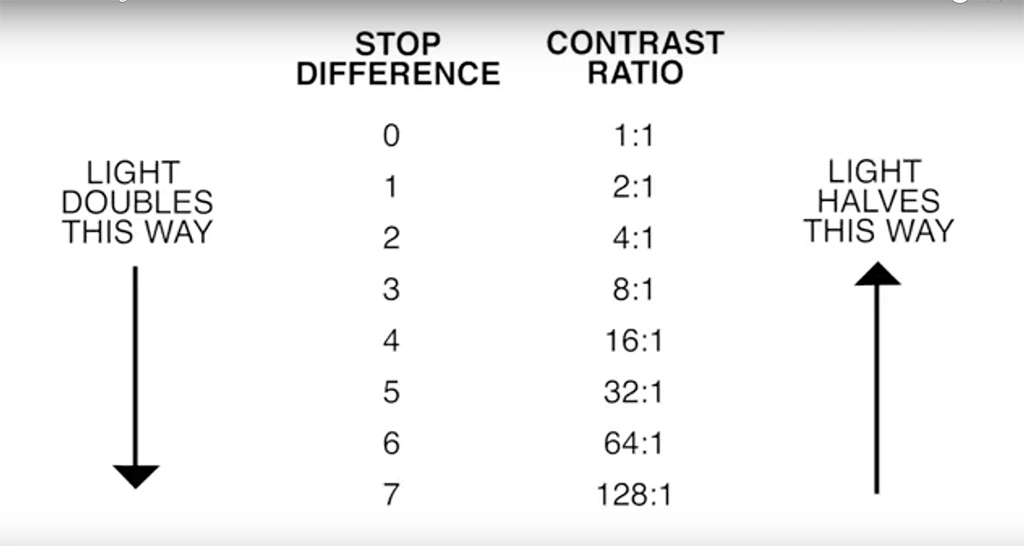
To measure the contrast ratio you will need a light meter. The process starts with you measuring the main source of light, or the key light.
Get a reading from the brightest area on the face of your subject. Then, measure the area lit by the secondary light, or fill light. To make sense of what you have just measured you have to understand that the information you have just gathered is in F-stops, a measure of light. With each additional F-stop, for example going one stop from f/1.4 to f/2.0, you create a doubling of light. The reverse is also true; moving one stop from f/8.0 to f/5.6 results in a halving of the light.
Let’s say you grabbed a measurement from your key light of f/8.0. Then, when you measured your fill light area, you get a reading of f/4.0. This will lead you to a contrast ratio of 4:1 because there are two stops between f/4.0 and f/8.0 and each stop doubles the amount of light. In other words, two stops x twice the light per stop = four times as much light at f/8.0 than at f/4.0.

theslantedlens.com/2017/lighting-ratios-photo-video/
Examples in the post
-
Composition – These are the basic lighting techniques you need to know for photography and film
Read more: Composition – These are the basic lighting techniques you need to know for photography and film
http://www.diyphotography.net/basic-lighting-techniques-need-know-photography-film/
Amongst the basic techniques, there’s…
1- Side lighting – Literally how it sounds, lighting a subject from the side when they’re faced toward you
2- Rembrandt lighting – Here the light is at around 45 degrees over from the front of the subject, raised and pointing down at 45 degrees
3- Back lighting – Again, how it sounds, lighting a subject from behind. This can help to add drama with silouettes
4- Rim lighting – This produces a light glowing outline around your subject
5- Key light – The main light source, and it’s not necessarily always the brightest light source
6- Fill light – This is used to fill in the shadows and provide detail that would otherwise be blackness
7- Cross lighting – Using two lights placed opposite from each other to light two subjects
-
Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutions
Read more: Photography basics: Camera Aspect Ratio, Sensor Size and Depth of Field – resolutionshttp://www.shutterangle.com/2012/cinematic-look-aspect-ratio-sensor-size-depth-of-field/
http://www.shutterangle.com/2012/film-video-aspect-ratio-artistic-choice/












DESIGN
-
Turn Yourself Into an Action Figure Using ChatGPT
Read more: Turn Yourself Into an Action Figure Using ChatGPT
ChatGPT Action Figure Prompts:
Create an action figure from the photo. It must be visualised in a realistic way. There should be accessories next to the figure like a UX designer have, Macbook Pro, a camera, drawing tablet, headset etc. Add a hole to the top of the box in the action figure. Also write the text “UX Mate” and below it “Keep Learning! Keep Designing
Use this image to create a picture of a action figure toy of a construction worker in a blister package from head to toe with accessories including a hammer, a staple gun and a ladder. The package should read “Kirk The Handy Man”
Create a realistic image of a toy action figure box. The box should be designed in a toy-equipment/action-figure style, with a cut-out window at the top like classic action figure packaging. The main color of the box and moleskine notebook should match the color of my jacket (referenced visually). Add colorful Mexican skull decorations across the box for a vibrant and artistic flair. Inside the box, include a “Your name” action figure, posed heroically. Next to the figure, arrange the following “equipment” in a stylized layout: • item 1 • item 2 … On the box, write: “Your name” (bold title font) Underneath: “Your role or anything else” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. On the box, write: “Your name” (bold title font) Underneath: “Your role or description” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. Prompt on Kling AI The figure steps out of its toy packaging and begins walking forward. As he continues to walk, the camera gradually zooms out in sync with his movement.
“Create image. Create a toy of the person in the photo. Let it be an action figure. Next to the figure, there should be the toy’s equipment, each in its individual blisters. 1) a book called “Tecnoforma”. 2) A 3-headed dog with a tag that says “Troika” and a bone at its feet with word “austerity” written on it. 3) a three-headed Hydra with with a tag called “Geringonça”. 4) a book titled “D. Sebastião”. Don’t repeat the equipment under any circumstance. The card holding the blister should be strong orange. Also, on top of the box, write ‘Pedro Passos Coelho’ and underneath it, ‘PSD action figure’. The figure and equipment must all be inside blisters. Visualize this in a realistic way.”


-
IM3 Stained glass
Read more: IM3 Stained glass
http://imgur.com/a/GXUun#hO6wzrs
Some people are asking how… here is a brief explanation on how I did it with photos….
(more…)















COLOR
-
Thomas Mansencal – Colour Science for Python
Read more: Thomas Mansencal – Colour Science for Pythonhttps://thomasmansencal.substack.com/p/colour-science-for-python
https://www.colour-science.org/
Colour is an open-source Python package providing a comprehensive number of algorithms and datasets for colour science. It is freely available under the BSD-3-Clause terms.

-
The Color of Infinite Temperature
Read more: The Color of Infinite TemperatureThis is the color of something infinitely hot.

Of course you’d instantly be fried by gamma rays of arbitrarily high frequency, but this would be its spectrum in the visible range.
johncarlosbaez.wordpress.com/2022/01/16/the-color-of-infinite-temperature/
This is also the color of a typical neutron star. They’re so hot they look the same.
It’s also the color of the early Universe!This was worked out by David Madore.
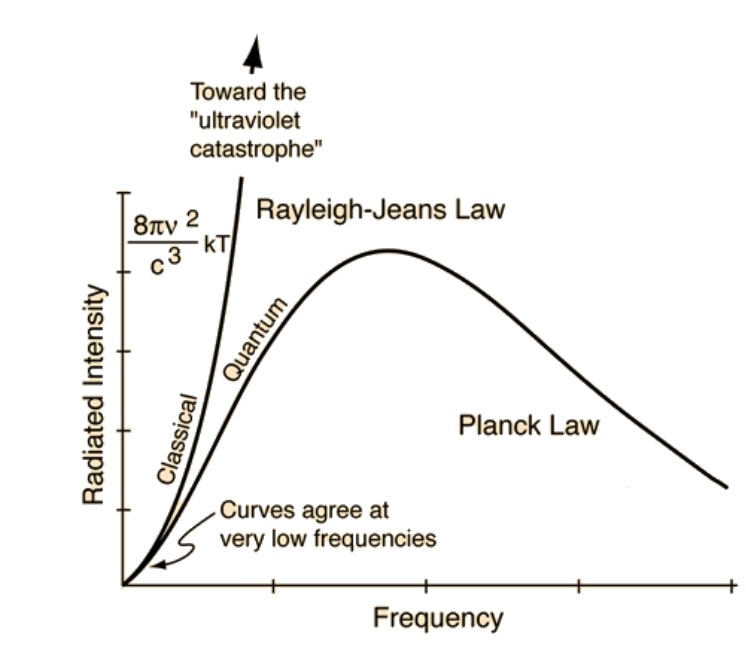
The color he got is sRGB(148,177,255).
www.htmlcsscolor.com/hex/94B1FFAnd according to the experts who sip latte all day and make up names for colors, this color is called ‘Perano’.













LIGHTING
-
Photography basics: Why Use a (MacBeth) Color Chart?
Read more: Photography basics: Why Use a (MacBeth) Color Chart?Start here: https://www.pixelsham.com/2013/05/09/gretagmacbeth-color-checker-numeric-values/
https://www.studiobinder.com/blog/what-is-a-color-checker-tool/



In LightRoom

in Final Cut

in Nuke
Note: In Foundry’s Nuke, the software will map 18% gray to whatever your center f/stop is set to in the viewer settings (f/8 by default… change that to EV by following the instructions below).
You can experiment with this by attaching an Exposure node to a Constant set to 0.18, setting your viewer read-out to Spotmeter, and adjusting the stops in the node up and down. You will see that a full stop up or down will give you the respective next value on the aperture scale (f8, f11, f16 etc.).One stop doubles or halves the amount or light that hits the filmback/ccd, so everything works in powers of 2.
So starting with 0.18 in your constant, you will see that raising it by a stop will give you .36 as a floating point number (in linear space), while your f/stop will be f/11 and so on.If you set your center stop to 0 (see below) you will get a relative readout in EVs, where EV 0 again equals 18% constant gray.

In other words. Setting the center f-stop to 0 means that in a neutral plate, the middle gray in the macbeth chart will equal to exposure value 0. EV 0 corresponds to an exposure time of 1 sec and an aperture of f/1.0.
This will set the sun usually around EV12-17 and the sky EV1-4 , depending on cloud coverage.
To switch Foundry’s Nuke’s SpotMeter to return the EV of an image, click on the main viewport, and then press s, this opens the viewer’s properties. Now set the center f-stop to 0 in there. And the SpotMeter in the viewport will change from aperture and fstops to EV.
-
DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ball
Read more: DiffusionLight: HDRI Light Probes for Free by Painting a Chrome Ballhttps://diffusionlight.github.io/
https://github.com/DiffusionLight/DiffusionLight
https://github.com/DiffusionLight/DiffusionLight?tab=MIT-1-ov-file#readme
https://colab.research.google.com/drive/15pC4qb9mEtRYsW3utXkk-jnaeVxUy-0S
“a simple yet effective technique to estimate lighting in a single input image. Current techniques rely heavily on HDR panorama datasets to train neural networks to regress an input with limited field-of-view to a full environment map. However, these approaches often struggle with real-world, uncontrolled settings due to the limited diversity and size of their datasets. To address this problem, we leverage diffusion models trained on billions of standard images to render a chrome ball into the input image. Despite its simplicity, this task remains challenging: the diffusion models often insert incorrect or inconsistent objects and cannot readily generate images in HDR format. Our research uncovers a surprising relationship between the appearance of chrome balls and the initial diffusion noise map, which we utilize to consistently generate high-quality chrome balls. We further fine-tune an LDR difusion model (Stable Diffusion XL) with LoRA, enabling it to perform exposure bracketing for HDR light estimation. Our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios.”

-
What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…
Read more: What’s the Difference Between Ray Casting, Ray Tracing, Path Tracing and Rasterization? Physical light tracing…RASTERIZATION
Rasterisation (or rasterization) is the task of taking the information described in a vector graphics format OR the vertices of triangles making 3D shapes and converting them into a raster image (a series of pixels, dots or lines, which, when displayed together, create the image which was represented via shapes), or in other words “rasterizing” vectors or 3D models onto a 2D plane for display on a computer screen.For each triangle of a 3D shape, you project the corners of the triangle on the virtual screen with some math (projective geometry). Then you have the position of the 3 corners of the triangle on the pixel screen. Those 3 points have texture coordinates, so you know where in the texture are the 3 corners. The cost is proportional to the number of triangles, and is only a little bit affected by the screen resolution.
In computer graphics, a raster graphics or bitmap image is a dot matrix data structure that represents a generally rectangular grid of pixels (points of color), viewable via a monitor, paper, or other display medium.
With rasterization, objects on the screen are created from a mesh of virtual triangles, or polygons, that create 3D models of objects. A lot of information is associated with each vertex, including its position in space, as well as information about color, texture and its “normal,” which is used to determine the way the surface of an object is facing.
Computers then convert the triangles of the 3D models into pixels, or dots, on a 2D screen. Each pixel can be assigned an initial color value from the data stored in the triangle vertices.
Further pixel processing or “shading,” including changing pixel color based on how lights in the scene hit the pixel, and applying one or more textures to the pixel, combine to generate the final color applied to a pixel.
The main advantage of rasterization is its speed. However, rasterization is simply the process of computing the mapping from scene geometry to pixels and does not prescribe a particular way to compute the color of those pixels. So it cannot take shading, especially the physical light, into account and it cannot promise to get a photorealistic output. That’s a big limitation of rasterization.
There are also multiple problems:
If you have two triangles one is behind the other, you will draw twice all the pixels. you only keep the pixel from the triangle that is closer to you (Z-buffer), but you still do the work twice.
The borders of your triangles are jagged as it is hard to know if a pixel is in the triangle or out. You can do some smoothing on those, that is anti-aliasing.
You have to handle every triangles (including the ones behind you) and then see that they do not touch the screen at all. (we have techniques to mitigate this where we only look at triangles that are in the field of view)
Transparency is hard to handle (you can’t just do an average of the color of overlapping transparent triangles, you have to do it in the right order)



RAY CASTING
It is almost the exact reverse of rasterization: you start from the virtual screen instead of the vector or 3D shapes, and you project a ray, starting from each pixel of the screen, until it intersect with a triangle.The cost is directly correlated to the number of pixels in the screen and you need a really cheap way of finding the first triangle that intersect a ray. In the end, it is more expensive than rasterization but it will, by design, ignore the triangles that are out of the field of view.
You can use it to continue after the first triangle it hit, to take a little bit of the color of the next one, etc… This is useful to handle the border of the triangle cleanly (less jagged) and to handle transparency correctly.
RAYTRACING



Same idea as ray casting except once you hit a triangle you reflect on it and go into a different direction. The number of reflection you allow is the “depth” of your ray tracing. The color of the pixel can be calculated, based off the light source and all the polygons it had to reflect off of to get to that screen pixel.The easiest way to think of ray tracing is to look around you, right now. The objects you’re seeing are illuminated by beams of light. Now turn that around and follow the path of those beams backwards from your eye to the objects that light interacts with. That’s ray tracing.
Ray tracing is eye-oriented process that needs walking through each pixel looking for what object should be shown there, which is also can be described as a technique that follows a beam of light (in pixels) from a set point and simulates how it reacts when it encounters objects.
Compared with rasterization, ray tracing is hard to be implemented in real time, since even one ray can be traced and processed without much trouble, but after one ray bounces off an object, it can turn into 10 rays, and those 10 can turn into 100, 1000…The increase is exponential, and the the calculation for all these rays will be time consuming.
Historically, computer hardware hasn’t been fast enough to use these techniques in real time, such as in video games. Moviemakers can take as long as they like to render a single frame, so they do it offline in render farms. Video games have only a fraction of a second. As a result, most real-time graphics rely on the another technique called rasterization.

PATH TRACING
Path tracing can be used to solve more complex lighting situations.
Path tracing is a type of ray tracing. When using path tracing for rendering, the rays only produce a single ray per bounce. The rays do not follow a defined line per bounce (to a light, for example), but rather shoot off in a random direction. The path tracing algorithm then takes a random sampling of all of the rays to create the final image. This results in sampling a variety of different types of lighting.When a ray hits a surface it doesn’t trace a path to every light source, instead it bounces the ray off the surface and keeps bouncing it until it hits a light source or exhausts some bounce limit.
It then calculates the amount of light transferred all the way to the pixel, including any color information gathered from surfaces along the way.
It then averages out the values calculated from all the paths that were traced into the scene to get the final pixel color value.It requires a ton of computing power and if you don’t send out enough rays per pixel or don’t trace the paths far enough into the scene then you end up with a very spotty image as many pixels fail to find any light sources from their rays. So when you increase the the samples per pixel, you can see the image quality becomes better and better.
Ray tracing tends to be more efficient than path tracing. Basically, the render time of a ray tracer depends on the number of polygons in the scene. The more polygons you have, the longer it will take.
Meanwhile, the rendering time of a path tracer can be indifferent to the number of polygons, but it is related to light situation: If you add a light, transparency, translucence, or other shader effects, the path tracer will slow down considerably.
blogs.nvidia.com/blog/2018/03/19/whats-difference-between-ray-tracing-rasterization/
https://en.wikipedia.org/wiki/Rasterisation
https://www.quora.com/Whats-the-difference-between-ray-tracing-and-path-tracing
-
Simulon – a Hollywood production studio app in the hands of an independent creator with access to consumer hardware, LDRi to HDRi through ML
Read more: Simulon – a Hollywood production studio app in the hands of an independent creator with access to consumer hardware, LDRi to HDRi through MLDivesh Naidoo: The video below was made with a live in-camera preview and auto-exposure matching, no camera solve, no HDRI capture and no manual compositing setup. Using the new Simulon phone app.
LDR to HDR through ML
https://simulon.typeform.com/betatest
Process example











COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Image rendering bit depth
-
Types of AI Explained in a few Minutes – AI Glossary
-
Sensitivity of human eye
-
Types of Film Lights and their efficiency – CRI, Color Temperature and Luminous Efficacy
-
Convert 2D Images to 3D Models
-
How to paint a boardgame miniatures
-
STOP FCC – SAVE THE FREE NET
-
Glossary of Lighting Terms – cheat sheet
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
