


COMPOSITION
























DESIGN
-
Goga Tandashvili – bas-relief master
Read more: Goga Tandashvili – bas-relief master@moltenimmersiveart Goga Tandashvili is a master of the art of Bas-Relief. Using this technique, he creates stunning figures that are slightly raised from a flat surface, bringing scenes inspired by the natural world to life. #Art #Artists #GogaTandashvili #BasReliefSculpture #ArtInspiredByNature #ImpressionistArt #BasRelief #Sculptures #Sculptor #Molten #MoltenArt #MoltenImmersiveArt #MoltenAffect #Curation #Curator #ArtCuration #ArtCurator #DorothyDiStefano ♬ original sound – Molten Immersive Art -
Mariko Mori – Kamitate Stone at Sean Kelly Gallery
Read more: Mariko Mori – Kamitate Stone at Sean Kelly Gallery
Mariko Mori, the internationally celebrated artist who blends technology, spirituality, and nature, debuts Kamitate Stone I this October at Sean Kelly Gallery in New York. The work continues her exploration of luminous form, energy, and transcendence.














COLOR
-
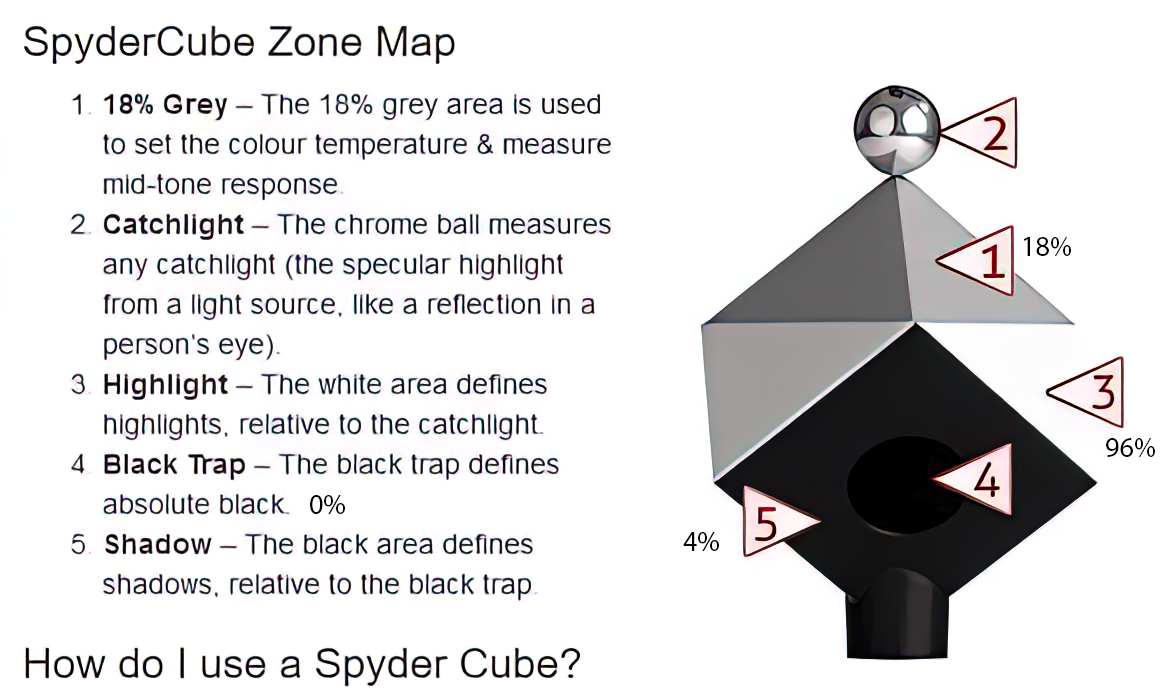
Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?
Read more: Is a MacBeth Colour Rendition Chart the Safest Way to Calibrate a Camera?www.colour-science.org/posts/the-colorchecker-considered-mostly-harmless/
“Unless you have all the relevant spectral measurements, a colour rendition chart should not be used to perform colour-correction of camera imagery but only for white balancing and relative exposure adjustments.”
“Using a colour rendition chart for colour-correction might dramatically increase error if the scene light source spectrum is different from the illuminant used to compute the colour rendition chart’s reference values.”
“other factors make using a colour rendition chart unsuitable for camera calibration:
– Uncontrolled geometry of the colour rendition chart with the incident illumination and the camera.
– Unknown sample reflectances and ageing as the colour of the samples vary with time.
– Low samples count.
– Camera noise and flare.
– Etc…“Those issues are well understood in the VFX industry, and when receiving plates, we almost exclusively use colour rendition charts to white balance and perform relative exposure adjustments, i.e. plate neutralisation.”
-
Composition – cinematography Cheat Sheet
Read more: Composition – cinematography Cheat Sheet
Where is our eye attracted first? Why?
Size. Focus. Lighting. Color.
Size. Mr. White (Harvey Keitel) on the right.
Focus. He’s one of the two objects in focus.
Lighting. Mr. White is large and in focus and Mr. Pink (Steve Buscemi) is highlighted by
a shaft of light.
Color. Both are black and white but the read on Mr. White’s shirt now really stands out.
(more…)
What type of lighting?















LIGHTING
-
PTGui 13 beta adds control through a Patch Editor
Read more: PTGui 13 beta adds control through a Patch EditorAdditions:
- Patch Editor (PTGui Pro)
- DNG output
- Improved RAW / DNG handling
- JPEG 2000 support
- Performance improvements



















COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Canva bought Affinity – Now Affinity Photo and Affinity Designer are… GONE?!
-
Want to build a start up company that lasts? Think three-layer cake
-
Eyeline Labs VChain – Chain-of-Visual-Thought for Reasoning in Video Generation for better AI physics
-
Guide to Prompt Engineering
-
Ross Pettit on The Agile Manager – How tech firms went for prioritizing cash flow instead of talent (and artists)
-
Godot Cheat Sheets
-
Animation/VFX/Game Industry JOB POSTINGS by Chris Mayne
-
AnimationXpress.com interviews Daniele Tosti for TheCgCareer.com channel
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.
