



3Dprinting (176) A.I. (761) animation (340) blender (197) colour (229) commercials (49) composition (152) cool (360) design (636) Featured (69) hardware (308) IOS (109) jokes (134) lighting (282) modeling (131) music (186) photogrammetry (178) photography (751) production (1254) python (87) quotes (491) reference (310) software (1336) trailers (297) ves (538) VR (219)
Category: hardware
-
What is OLED and what can it do for your TV
https://www.cnet.com/news/what-is-oled-and-what-can-it-do-for-your-tv/
OLED stands for Organic Light Emitting Diode. Each pixel in an OLED display is made of a material that glows when you jab it with electricity. Kind of like the heating elements in a toaster, but with less heat and better resolution. This effect is called electroluminescence, which is one of those delightful words that is big, but actually makes sense: “electro” for electricity, “lumin” for light and “escence” for, well, basically “essence.”
OLED TV marketing often claims “infinite” contrast ratios, and while that might sound like typical hyperbole, it’s one of the extremely rare instances where such claims are actually true. Since OLED can produce a perfect black, emitting no light whatsoever, its contrast ratio (expressed as the brightest white divided by the darkest black) is technically infinite.
OLED is the only technology capable of absolute blacks and extremely bright whites on a per-pixel basis. LCD definitely can’t do that, and even the vaunted, beloved, dearly departed plasma couldn’t do absolute blacks.

-
8 Tips for Scaling Rendering to the Cloud
http://www.awn.com/animationworld/8-tips-scaling-rendering-cloud
1.Understand data traffic patterns on your network
2.Watch the volume of requests to your render farm manager 3.Don’t burden your file server 4.Don’t underestimate license management during rendering 5.Match your hardware to the type of render job 6.Cache or sync data to reduce traffic at scale 7.Your Supervisor needs horsepower!
8.Keep a watchful eye on your spending
-
Touch Designer by Derivative – architecture real-time mapping projection management system
https://www.derivative.ca/088/Applications/
TouchDesigner is a visual development platform that equips you with the tools you need to create stunning realtime projects and rich user experiences.
Whether you’re creating interactive media systems, architectural projections, live music visuals, or simply rapid-prototyping your latest creative impulse, TouchDesigner is the platform that can do it all.
In the increasingly popular technique of mapping projector outputs to real-world objects, TouchDesigner is the tool of choice. With an integrated 3D engine to accurately model and texture real-world objects, completely configurable multiprojector output options, and one of the most powerful realtime graphics engines available, TouchDesigner is ready for the unique requirements of any projection mapping project.

-
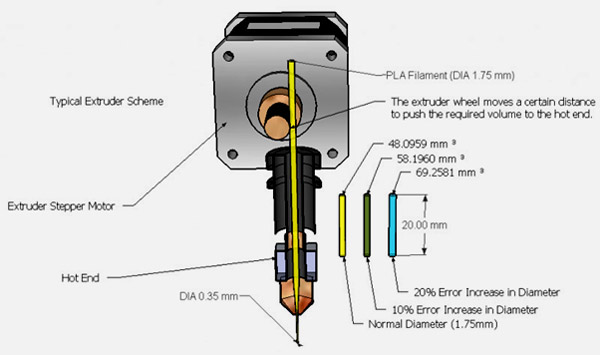
3D printing shop Moddler
http://www.3dprinter.net/venturebeat-profiles-3d-printing-shop-moddler https://vimeo.com/45456368























COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
Scene Referred vs Display Referred color workflows
-
Generative AI Glossary / AI Dictionary / AI Terminology
-
Gamma correction
-
Advanced Computer Vision with Python OpenCV and Mediapipe
-
AI Search – Find The Best AI Tools & Apps
-
VFX pipeline – Render Wall management topics
-
Google – Artificial Intelligence free courses
-
Rec-2020 – TVs new color gamut standard used by Dolby Vision?
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.