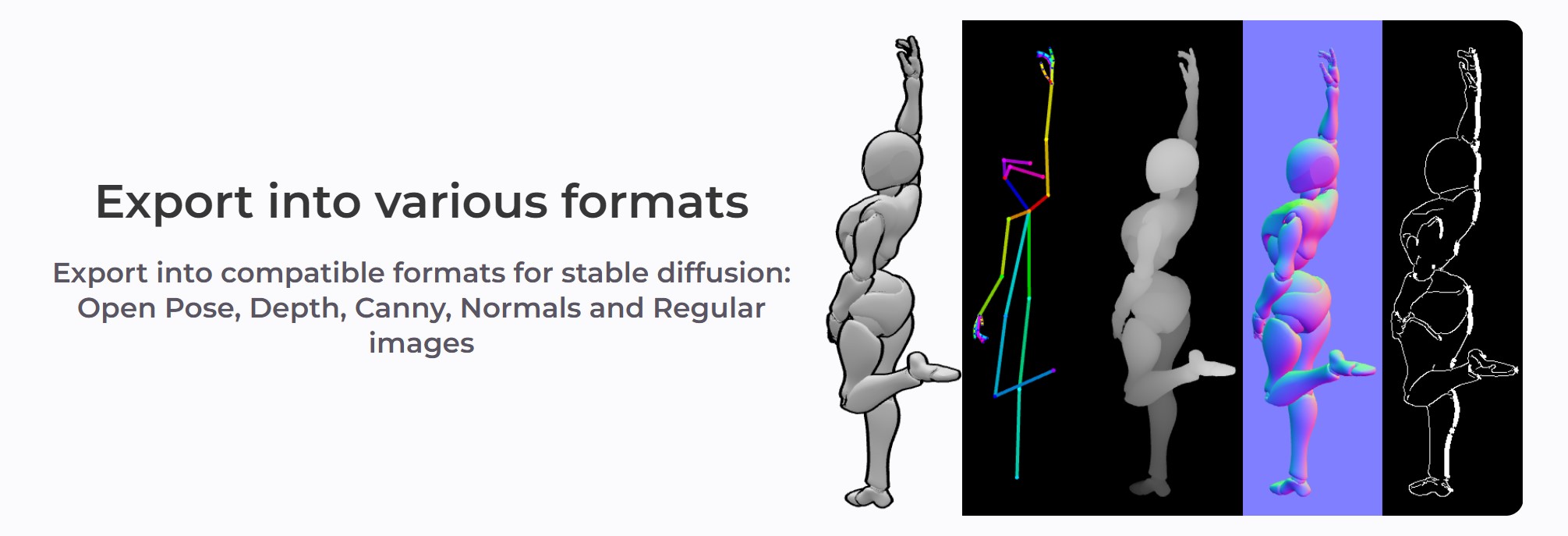
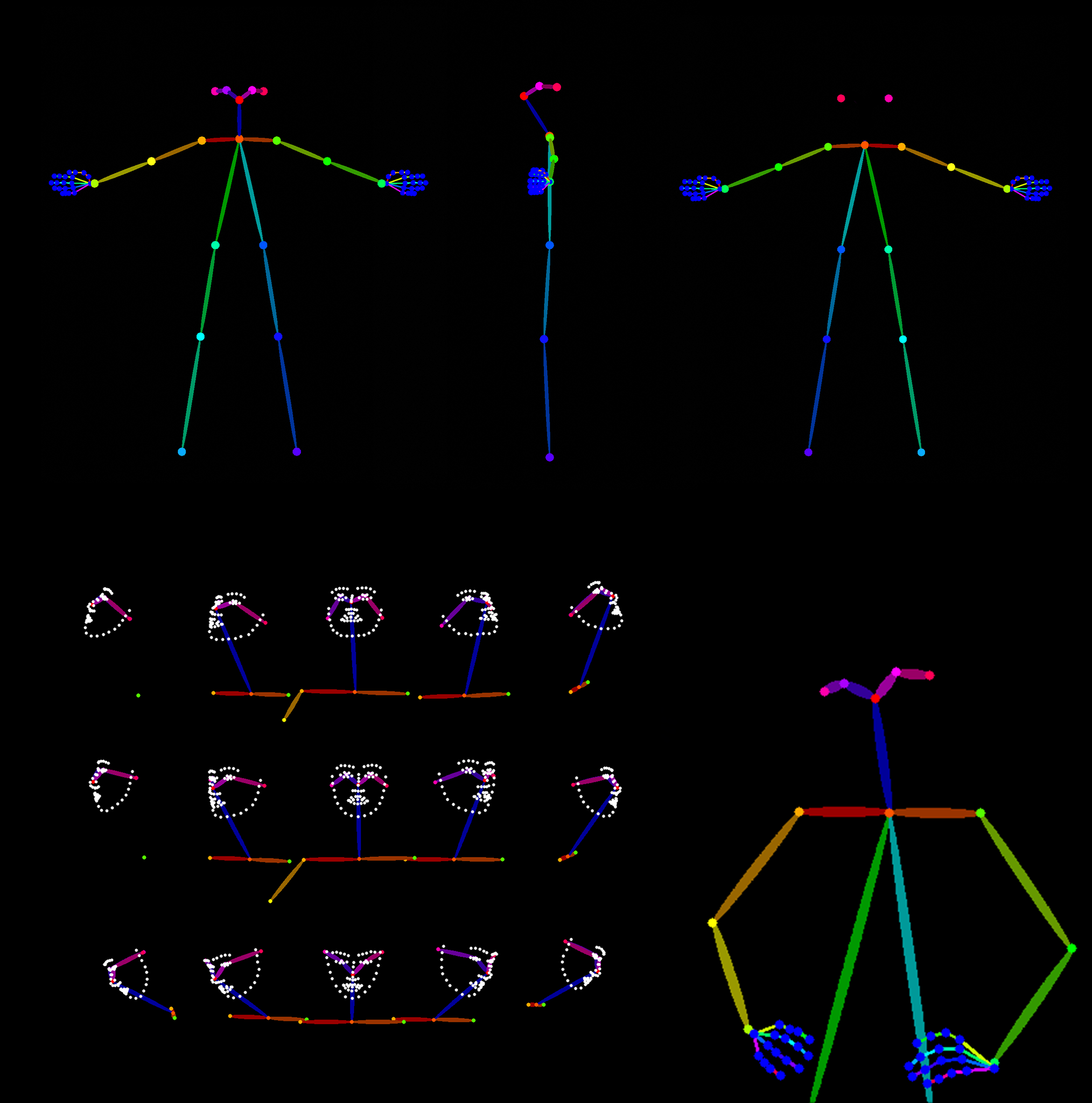
Export into compatible formats for stable diffusion:
Open Pose, Depth, Canny, Normals and Regular images




3Dprinting (176) A.I. (761) animation (340) blender (197) colour (229) commercials (49) composition (152) cool (360) design (636) Featured (69) hardware (308) IOS (109) jokes (134) lighting (282) modeling (131) music (186) photogrammetry (178) photography (751) production (1254) python (87) quotes (491) reference (310) software (1336) trailers (297) ves (538) VR (219)
Export into compatible formats for stable diffusion:
Open Pose, Depth, Canny, Normals and Regular images

https://www.patreon.com/posts/create-from-with-115147229
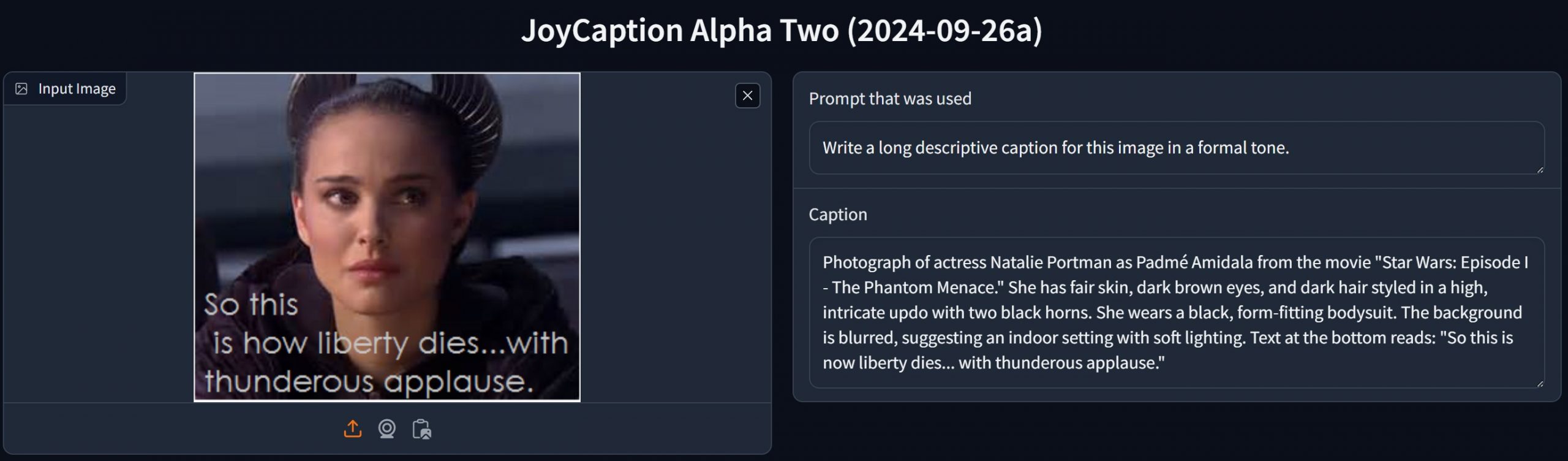
Note: the image below is not from the workflow
Nodes:
Install missing nodes in the workflow through the manager.
Models:
Make sure not to mix SD1.5 and SDLX models.
Follow the details under the pdf below.
General suggesions:
– Comfy Org / Flux.1 [dev] Checkpoint model (fp8)
The manager will put it under checkpoints, which will not work.
Make sure to put it under the models/unet folder for the Load Diffusion Model node to work.
– same for realvisxlV50_v50LightningBakedvae.safetensors
it should go under models/vae

https://github.com/Genesis-Embodied-AI/Genesis
https://genesis-world.readthedocs.io/en/latest
Genesis is a physics platform designed for general purpose Robotics/Embodied AI/Physical AI applications. It is simultaneously multiple things:

https://github.com/comfyanonymous/ComfyUI
https://comfyui-wiki.com/en/install
https://stable-diffusion-art.com/comfyui
https://github.com/LykosAI/StabilityMatrix
https://github.com/ltdrdata/ComfyUI-Manager
https://github.com/comfyanonymous/ComfyUI
https://github.com/ltdrdata/ComfyUI-Manager
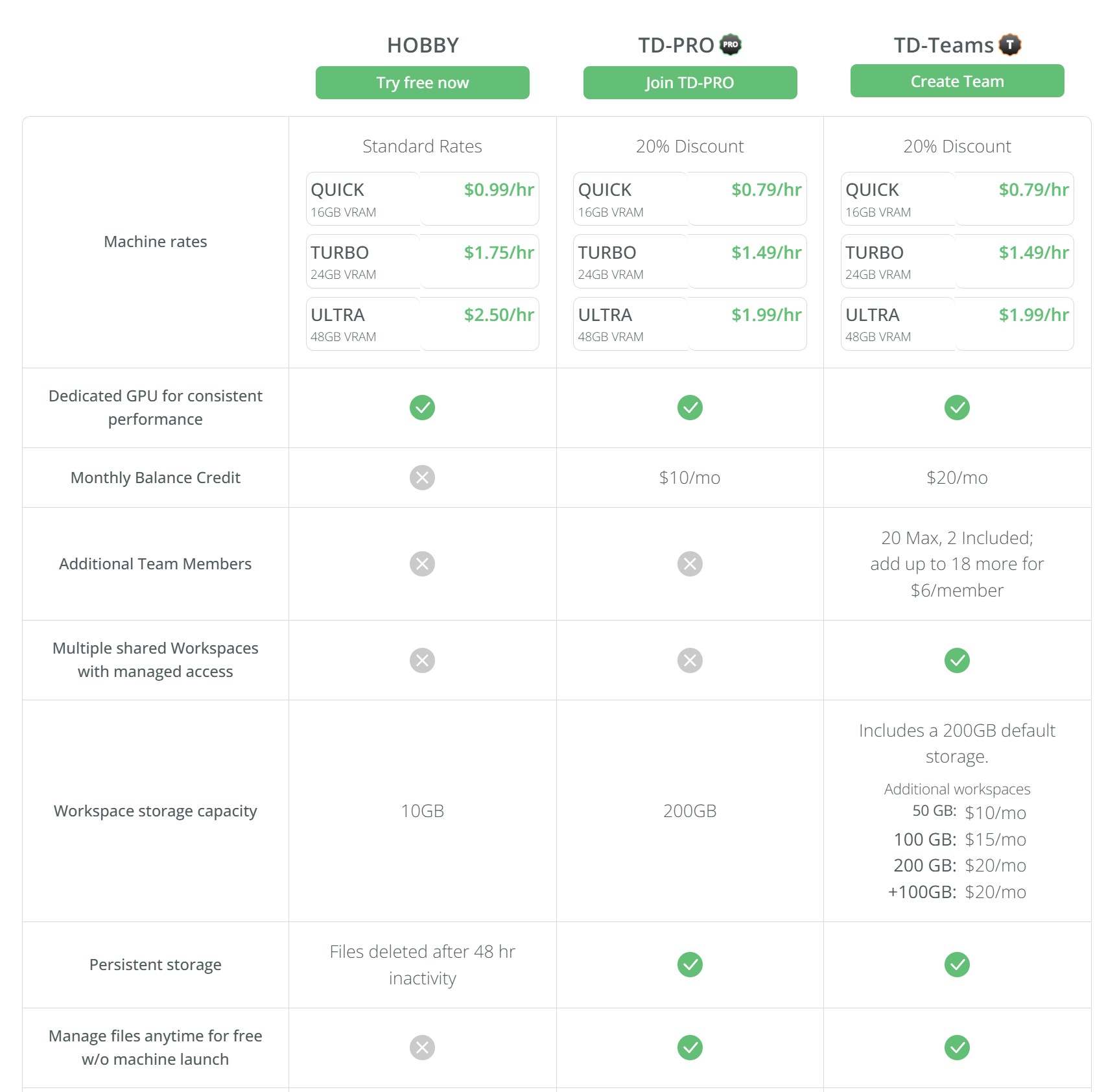
https://www.thinkdiffusion.com
Videos, shortcuts and details in the post!

https://substack.com/inbox/post/153106976
https://techcrunch.com/2024/12/14/what-are-ai-world-models-and-why-do-they-matter/
A model that can generate the next frame of a 3D scene based on the previous frame(s) and user input, trained on video data, and running in real-time.
World models enable AI systems to simulate and reason about their environments, pushing forward autonomous decision-making and real-world problem-solving.
The key insight is that by training on video data, these models learn not just how to generate images, but also:
Some companies, like World Labs, are taking a hybrid approach: using World Models to generate static 3D representations that can then be rendered using traditional 3D engines (in this case, Gaussian Splatting). This gives you the best of both worlds: the creative power of AI generation with the multiview consistency and performance of traditional rendering.
https://aivideo.hunyuan.tencent.com
https://github.com/Tencent/HunyuanVideo
Unlike other models like Sora, Pika2, Veo2, HunyuanVideo’s neural network weights are uncensored and openly distributed, which means they can be run locally under the right circumstances (for example on a consumer 24 GB VRAM GPU) and it can be fine-tuned or used with LoRAs to teach it new concepts.

Guillermo del Toro and Ben Affleck, among others, have voiced concerns about the capabilities of generative AI in the creative industries. They believe that while AI can produce text, images, sound, and video that are technically proficient, it lacks the authentic emotional depth and creative intuition inherent in human artistry—qualities that define works like those of Shakespeare, Dalí, or Hitchcock.
Generative AI models are trained on vast datasets and excel at recognizing and replicating patterns. They can generate coherent narratives, mimic writing or artistic styles, and even compose poetry and music. However, they do not possess consciousness or genuine emotions. The “emotion” conveyed in AI-generated content is a reflection of learned patterns rather than true emotional experience.
Having extensively tested and used generative AI over the past four years, I observe that the rapid advancement of the field suggests many current limitations could be overcome in the future. As models become more sophisticated and training data expands, AI systems are increasingly capable of generating content that is coherent, contextually relevant, stylistically diverse, and can even evoke emotional responses.
The following video is an AI-generated “casting” using a text-to-video model specifically prompted to test emotion, expressions, and microexpressions. This is only the beginning.
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.