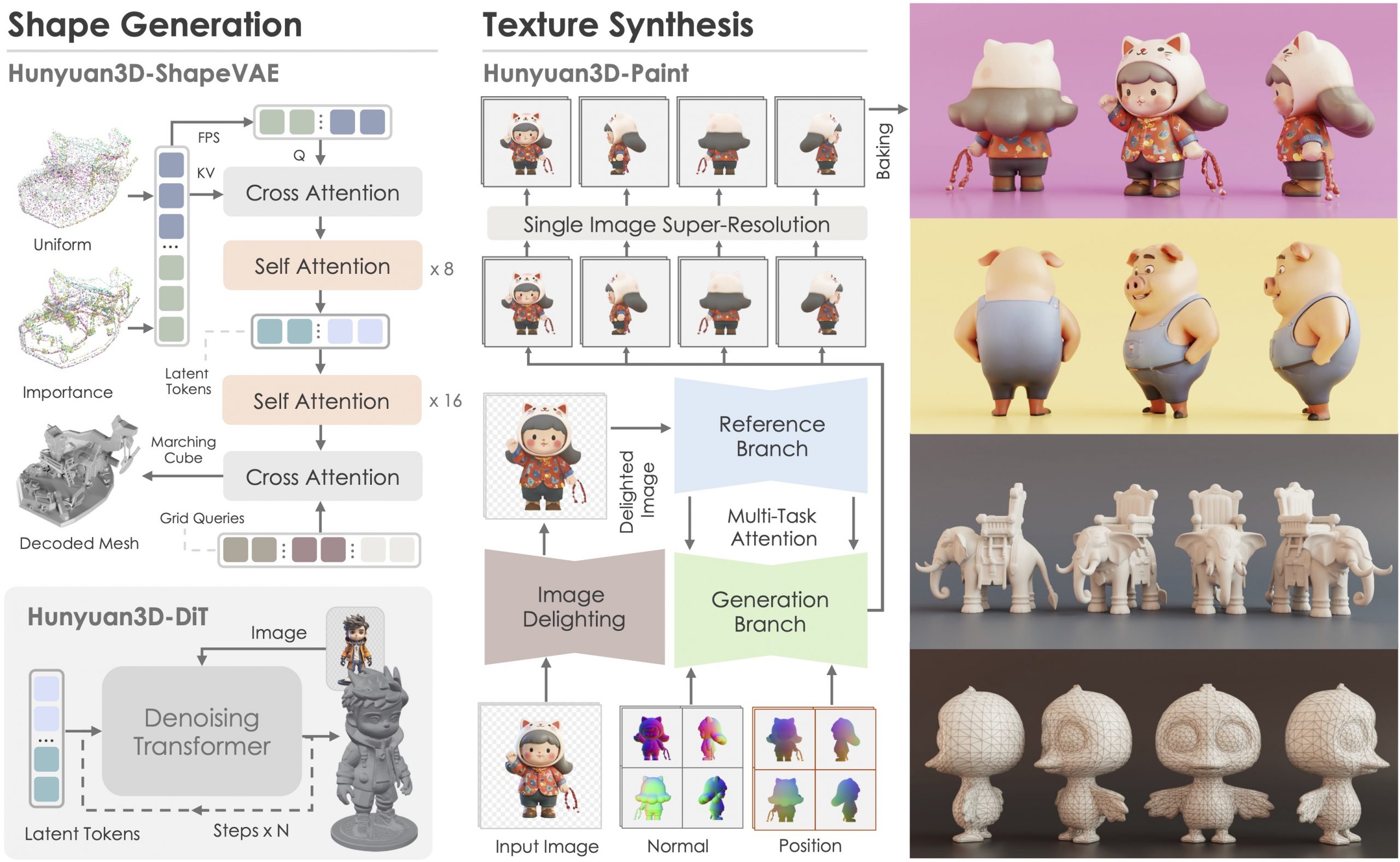
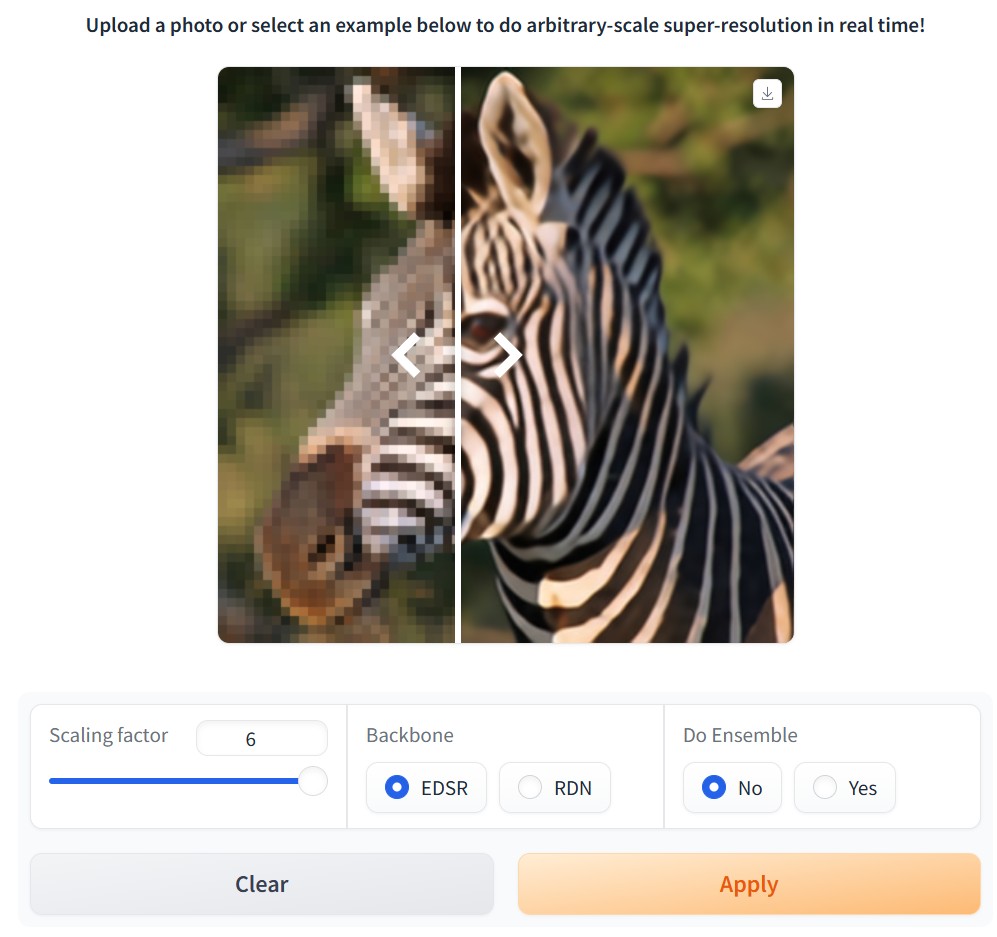
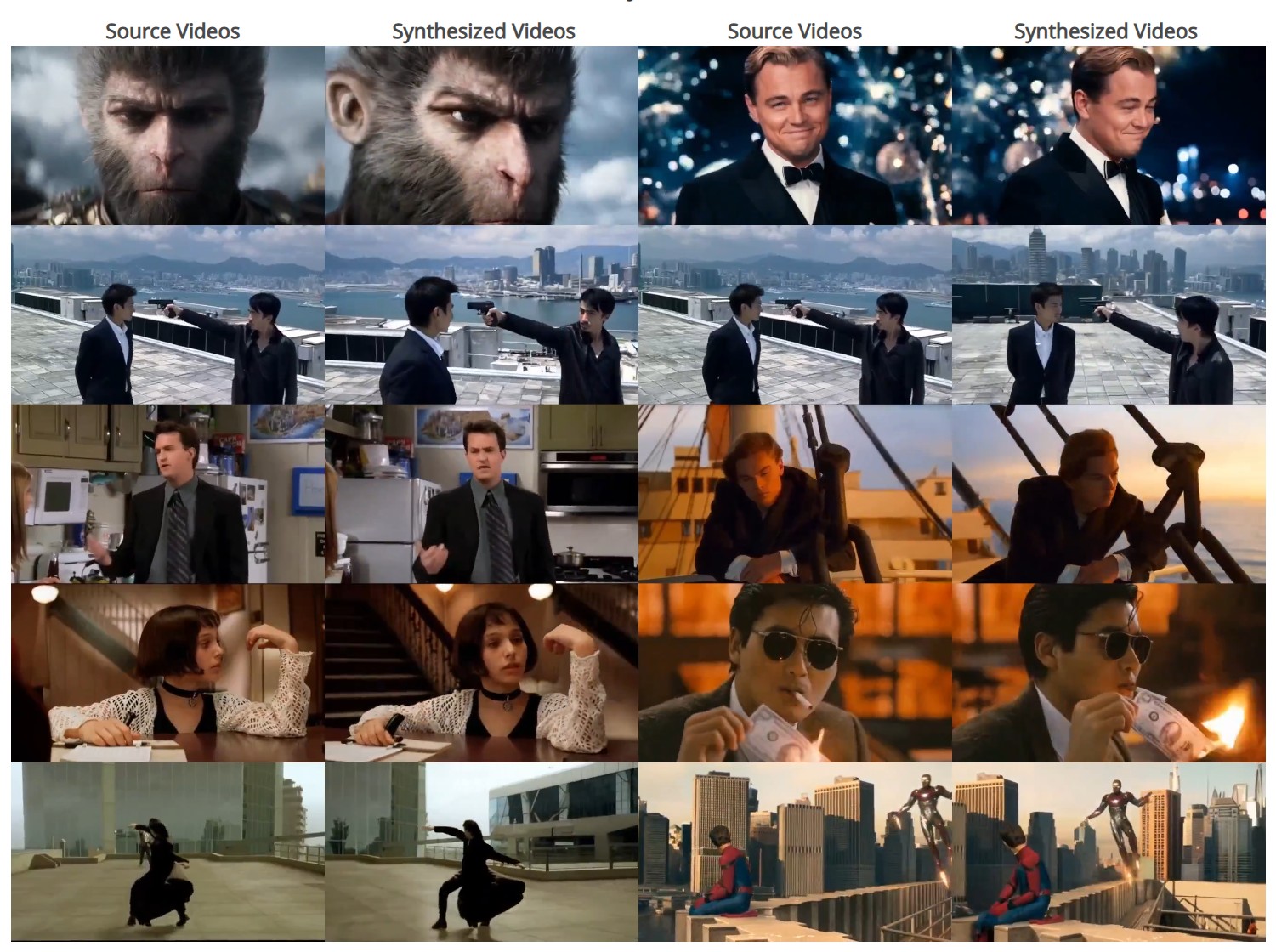
https://blog.comfy.org/p/comfyui-manager-joins-comfy-org
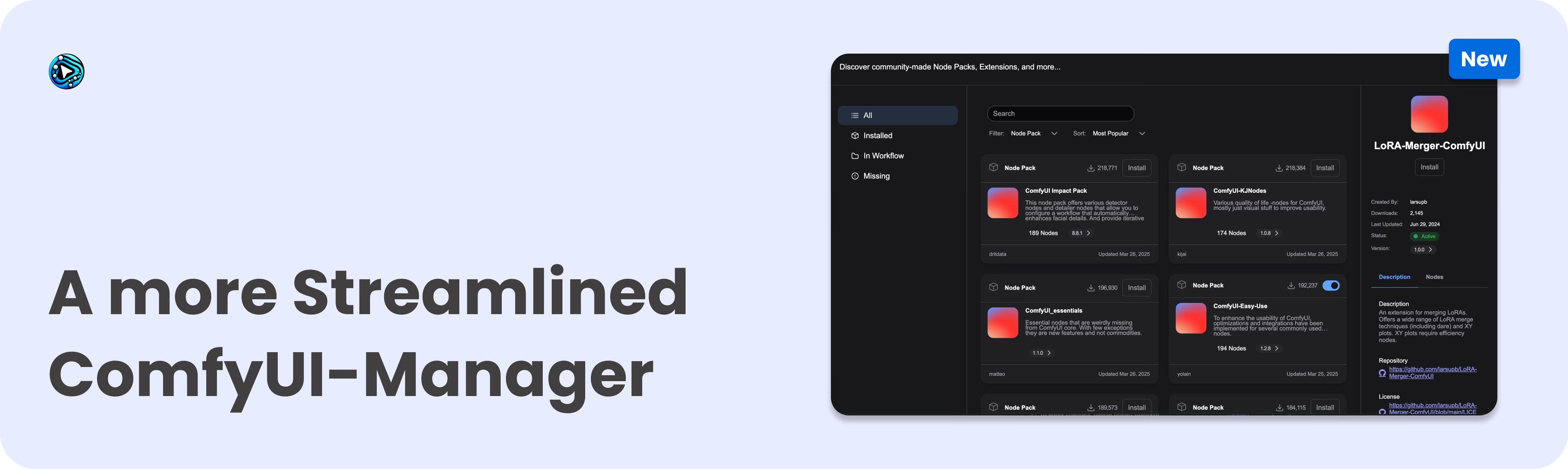
On March 28, ComfyUI-Manager will be moving to the Comfy-Org GitHub organization as Comfy-Org/ComfyUI-Manager. This represents a natural evolution as they continue working to improve the custom node experience for all ComfyUI users.
What This Means For You
This change is primarily about improving support and development velocity. There are a few practical considerations:
- Automatic GitHub redirects will ensure all existing links, git commands, and references to the repository will continue to work seamlessly without any action needed
- For developers: Any existing PRs and issues will be transferred to the new repository location
- For users: ComfyUI-Manager will continue to function exactly as before—no action needed
- For workflow authors: Resources that reference ComfyUI-Manager will continue to work without interruption