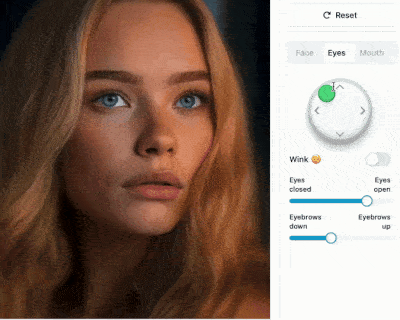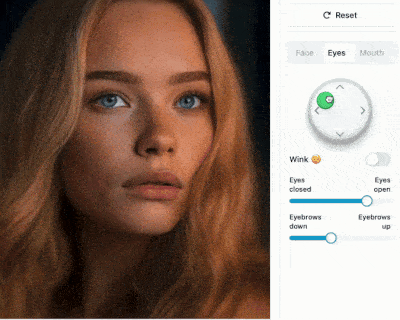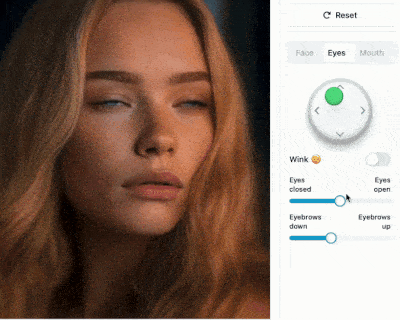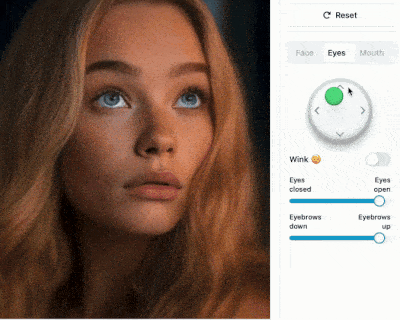
https://francis-rings.github.io/StableAnimator





3Dprinting (185) A.I. (925) animation (355) blender (223) colour (241) commercials (53) composition (154) cool (375) design (660) Featured (94) hardware (319) IOS (109) jokes (141) lighting (302) modeling (160) music (189) photogrammetry (199) photography (758) production (1310) python (108) quotes (501) reference (318) software (1384) trailers (310) ves (579) VR (221)
POPULAR SEARCHES unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
https://generative-world-explorer.github.io
Planning with partial observation is a central challenge in embodied AI. A majority of prior works have tackled this challenge by developing agents that physically explore their environment to update their beliefs about the world state. However, humans can imagine unseen parts of the world through a mental exploration and revise their beliefs with imagined observations. Such updated beliefs can allow them to make more informed decisions at the current step, without having to physically explore the world first. To achieve this human-like ability, we introduce the Generative World Explorer (Genex), a video generation model that allows an agent to mentally explore a large-scale 3D world (e.g., urban scenes) and acquire imagined observations to update its belief about the world .

Mochi 1 AI operates on a pay-as-you-go model, meaning you only pay for the services you utilize without any hidden fees.

A feed-forward model capable of reconstructing 3D scenes parameterized by 3D Gaussians from unposed sparse multi-view images.
Linus Torvalds, the creator and maintainer of the Linux kernel, talks modern developments.

Listen to the podcast in the post
“I just created a AI-Generated podcast by feeding an article I write into Google’s NotebookLM. If I hadn’t make it myself, I would have been 100% fooled into thinking it was real people talking.”
The model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU.
https://github.com/apple/ml-depth-pro
https://arxiv.org/pdf/2410.02073


In the next couple of decades, we will be able to do things that would have seemed like magic to our grandparents.
This phenomenon is not new, but it will be newly accelerated. People have become dramatically more capable over time; we can already accomplish things now that our predecessors would have believed to be impossible.
We are more capable not because of genetic change, but because we benefit from the infrastructure of society being way smarter and more capable than any one of us; in an important sense, society itself is a form of advanced intelligence. Our grandparents – and the generations that came before them – built and achieved great things. They contributed to the scaffolding of human progress that we all benefit from. AI will give people tools to solve hard problems and help us add new struts to that scaffolding that we couldn’t have figured out on our own. The story of progress will continue, and our children will be able to do things we can’t.
https://www.bbc.com/future/article/20240912-what-riddles-teach-us-about-the-human-mind
“As human beings, it’s very easy for us to have common sense, and apply it at the right time and adapt it to new problems,” says Ilievski, who describes his branch of computer science as “common sense AI”. But right now, AI has a “general lack of grounding in the world”, which makes that kind of basic, flexible reasoning a struggle.
AI excels at pattern recognition, “but it tends to be worse than humans at questions that require more abstract thinking”, says Xaq Pitkow, an associate professor at Carnegie Mellon University in the US, who studies the intersection of AI and neuroscience. In many cases, though, it depends on the problem.
A bizarre truth about AI is we have no idea how it works. The same is true about the brain.
That’s why the best systems may come from a combination of AI and human work; we can play to the machine’s strengths, Ilievski says.
The goal is to reduce costs by replacing traditional storyboard artists and VFX crews with AI-generated “cinematic video.” Lionsgate hopes to use this technology for both pre- and post-production processes. While the company promotes the cost-saving potential, the creative community has raised concerns, as Runway is currently facing a lawsuit over copyright infringement.
https://depthcrafter.github.io/
We innovate DepthCrafter, a novel video depth estimation approach, by leveraging video diffusion models. It can generate temporally consistent long depth sequences with fine-grained details for open-world videos, without requiring additional information such as camera poses or optical flow.
https://loopyavatar.github.io/
Loopy supports various visual and audio styles. It can generate vivid motion details from audio alone, such as non-speech movements like sighing, emotion-driven eyebrow and eye movements, and natural head movements.
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.