1 – Import your workflow 2 – Build a machine configuration to run your workflows on 3 – Download models into your private storage, to be used in your workflows and team. 4 – Run ComfyUI in the cloud to modify and test your workflows on cloud GPUs 5 – Expose workflow inputs with our custom nodes, for API and playground use 6 – Deploy APIs 7 – Let your team use your workflows in playground without using ComfyUI
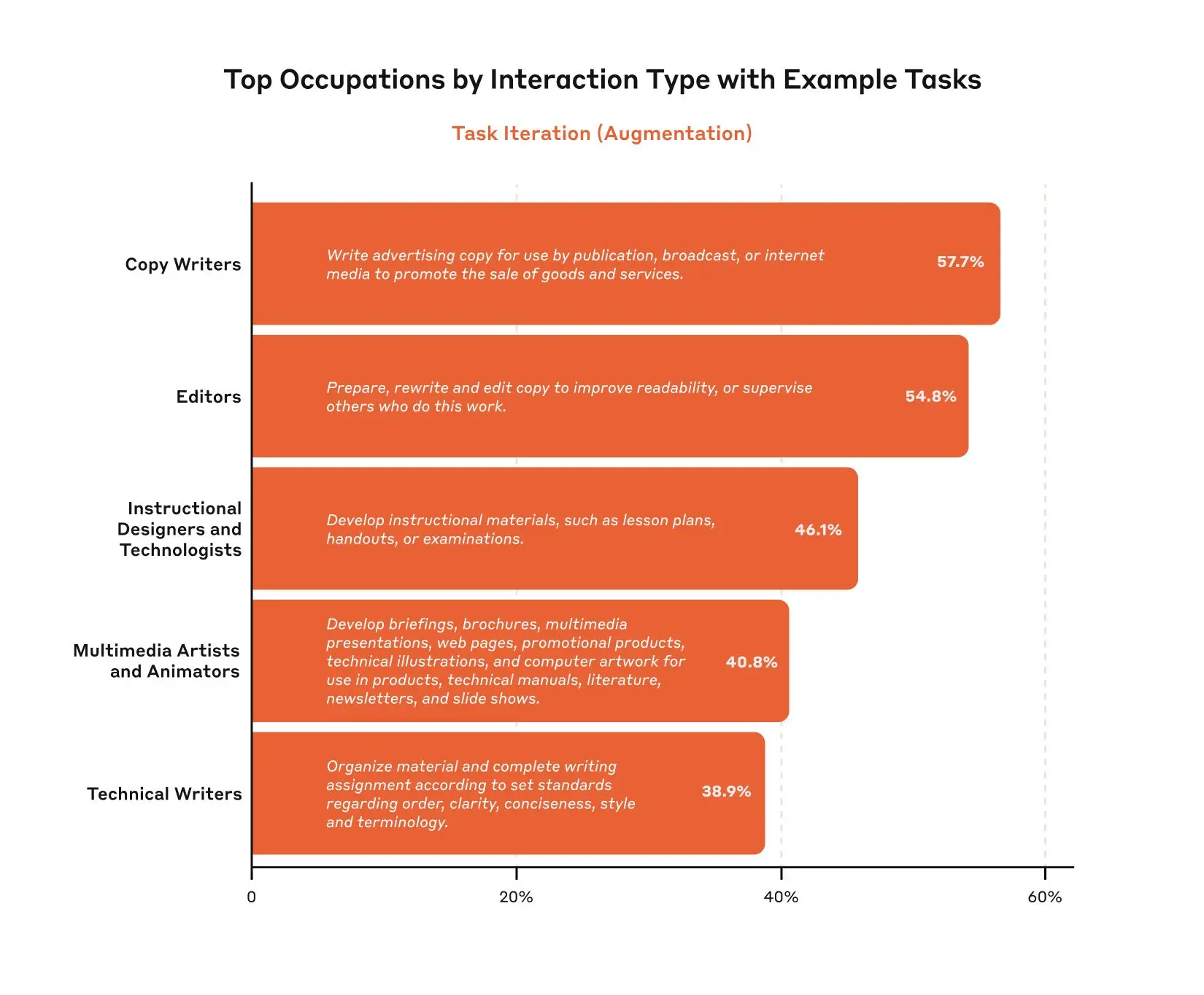
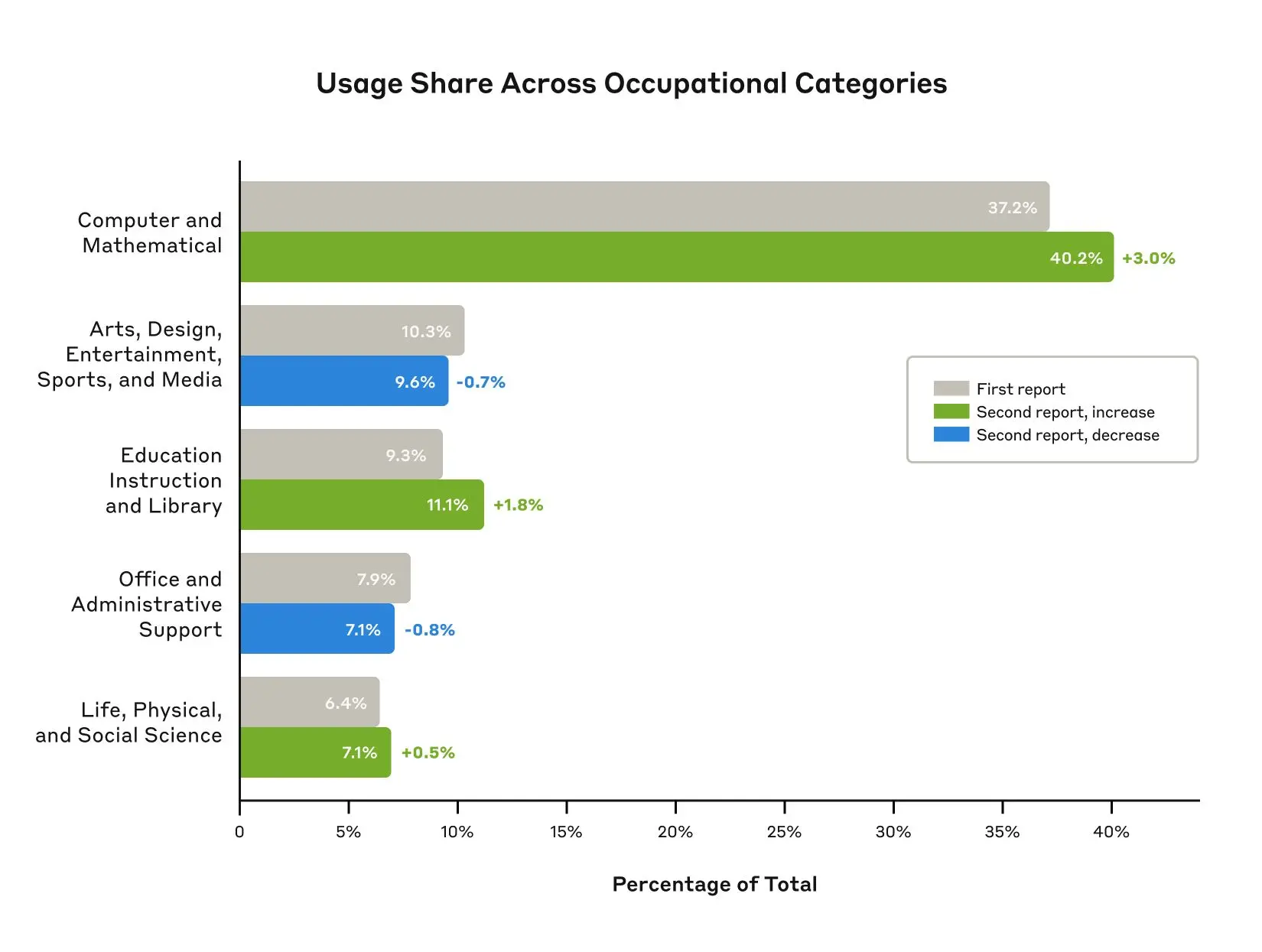
As models continue to advance, so too must our measurement of their economic impacts. In our second report, covering data since the launch of Claude 3.7 Sonnet, we find relatively modest increases in coding, education, and scientific use cases, and no change in the balance of augmentation and automation. We find that Claude’s new extended thinking mode is used with the highest frequency in technical domains and tasks, and identify patterns in automation / augmentation patterns across tasks and occupations. We release datasets for both of these analyses.
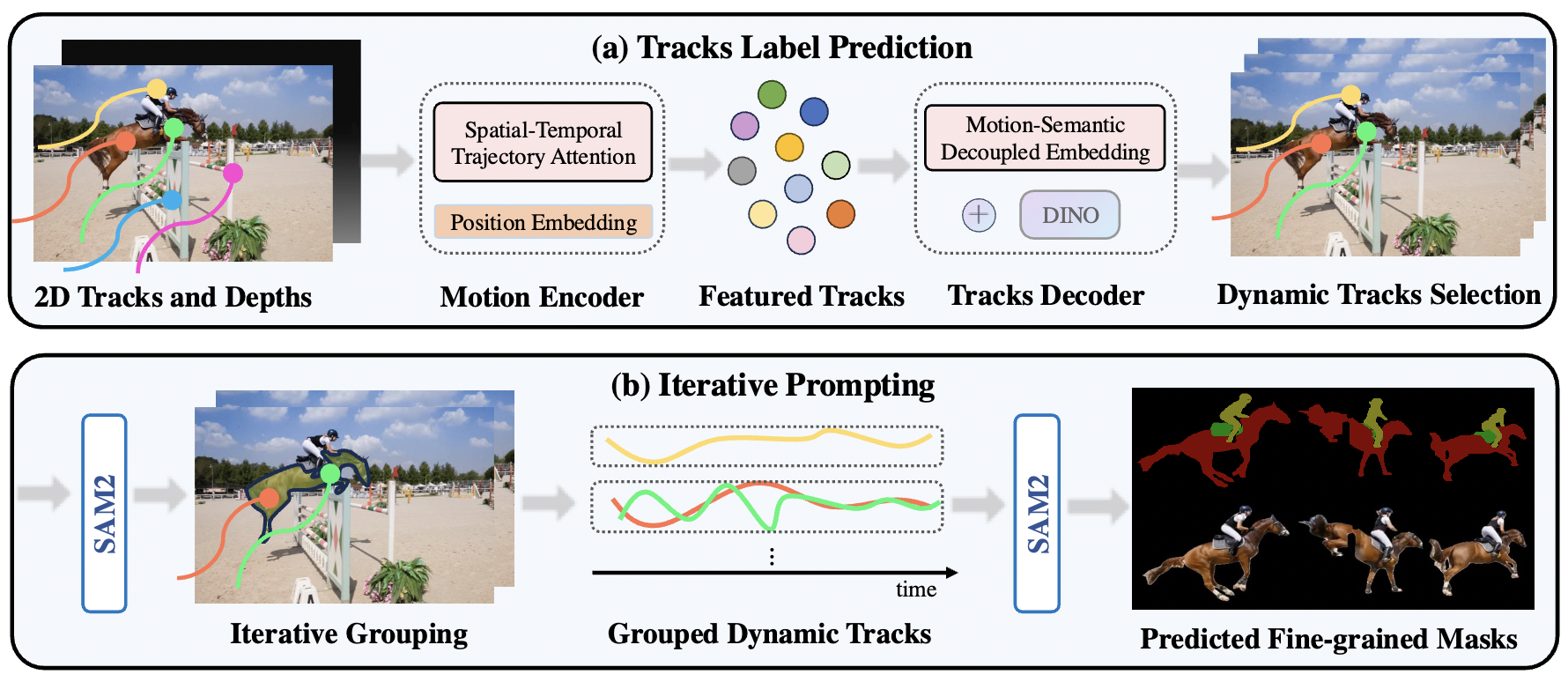
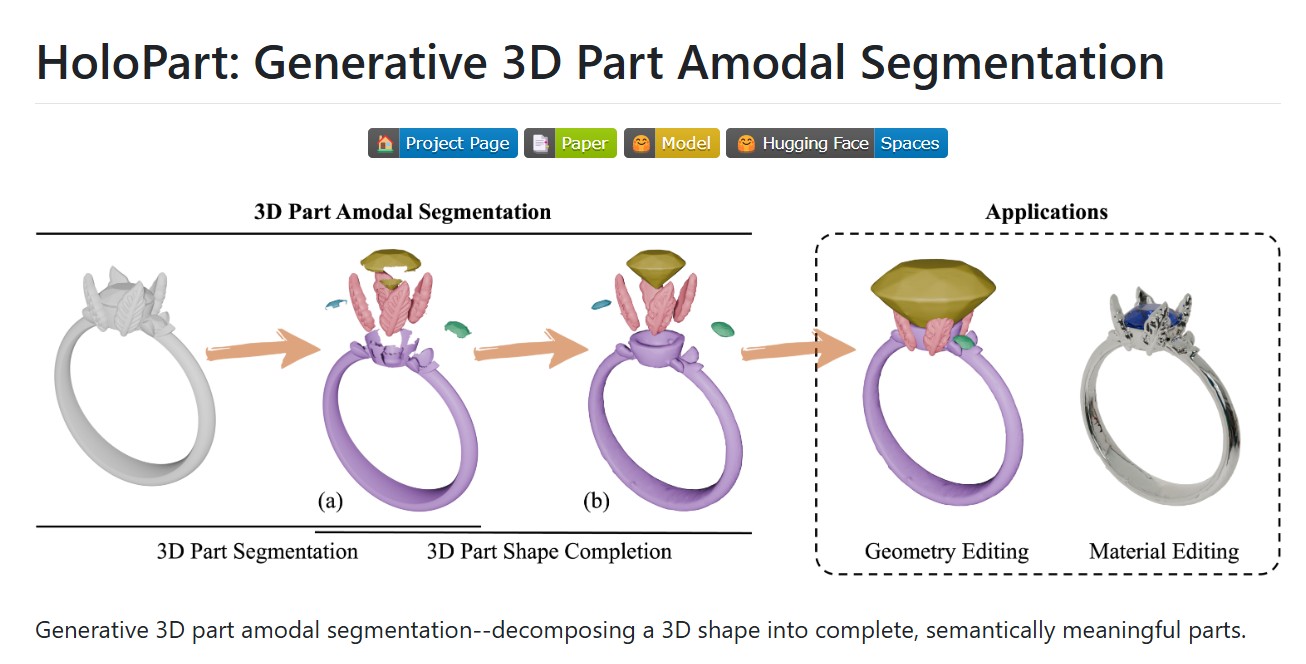
Overview of Our Pipeline. We take 2D tracks and depth maps generated by off-the-shelf models as input, which are then processed by a motion encoder to capture motion patterns, producing featured tracks. Next, we use tracks decoder that integrates DINO feature to decode the featured tracks by decoupling motion and semantic information and ultimately obtain the dynamic trajectories(a). Finally, using SAM2, we group dynamic tracks belonging to the same object and generate fine-grained moving object masks(b).
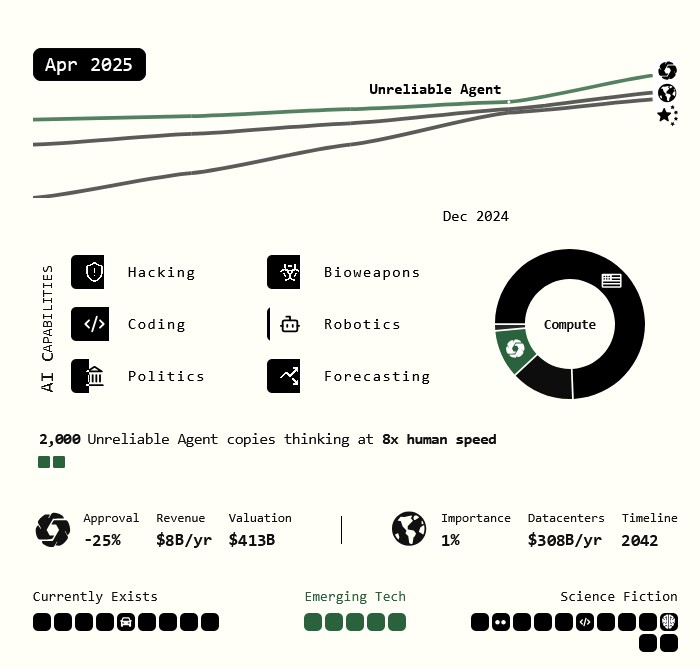
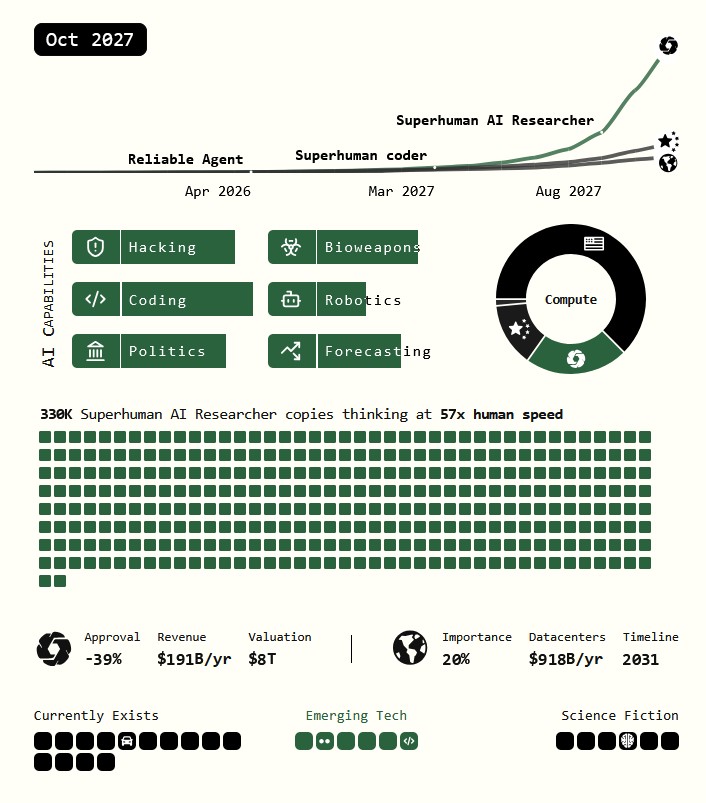
We predict that the impact of superhuman AI over the next decade will be enormous, exceeding that of the Industrial Revolution.
We wrote a scenario that represents our best guess about what that might look like.1 It’s informed by trend extrapolations, wargames, expert feedback, experience at OpenAI, and previous forecasting successes.
Create an action figure from the photo. It must be visualised in a realistic way. There should be accessories next to the figure like a UX designer have, Macbook Pro, a camera, drawing tablet, headset etc. Add a hole to the top of the box in the action figure. Also write the text “UX Mate” and below it “Keep Learning! Keep Designing
Use this image to create a picture of a action figure toy of a construction worker in a blister package from head to toe with accessories including a hammer, a staple gun and a ladder. The package should read “Kirk The Handy Man”
Create a realistic image of a toy action figure box. The box should be designed in a toy-equipment/action-figure style, with a cut-out window at the top like classic action figure packaging. The main color of the box and moleskine notebook should match the color of my jacket (referenced visually). Add colorful Mexican skull decorations across the box for a vibrant and artistic flair. Inside the box, include a “Your name” action figure, posed heroically. Next to the figure, arrange the following “equipment” in a stylized layout: • item 1 • item 2 … On the box, write: “Your name” (bold title font) Underneath: “Your role or anything else” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. On the box, write: “Your name” (bold title font) Underneath: “Your role or description” The entire scene should look like a real product mockup, highly realistic, lit like a studio product photo. Prompt on Kling AI The figure steps out of its toy packaging and begins walking forward. As he continues to walk, the camera gradually zooms out in sync with his movement.
“Create image. Create a toy of the person in the photo. Let it be an action figure. Next to the figure, there should be the toy’s equipment, each in its individual blisters. 1) a book called “Tecnoforma”. 2) A 3-headed dog with a tag that says “Troika” and a bone at its feet with word “austerity” written on it. 3) a three-headed Hydra with with a tag called “Geringonça”. 4) a book titled “D. Sebastião”. Don’t repeat the equipment under any circumstance. The card holding the blister should be strong orange. Also, on top of the box, write ‘Pedro Passos Coelho’ and underneath it, ‘PSD action figure’. The figure and equipment must all be inside blisters. Visualize this in a realistic way.”
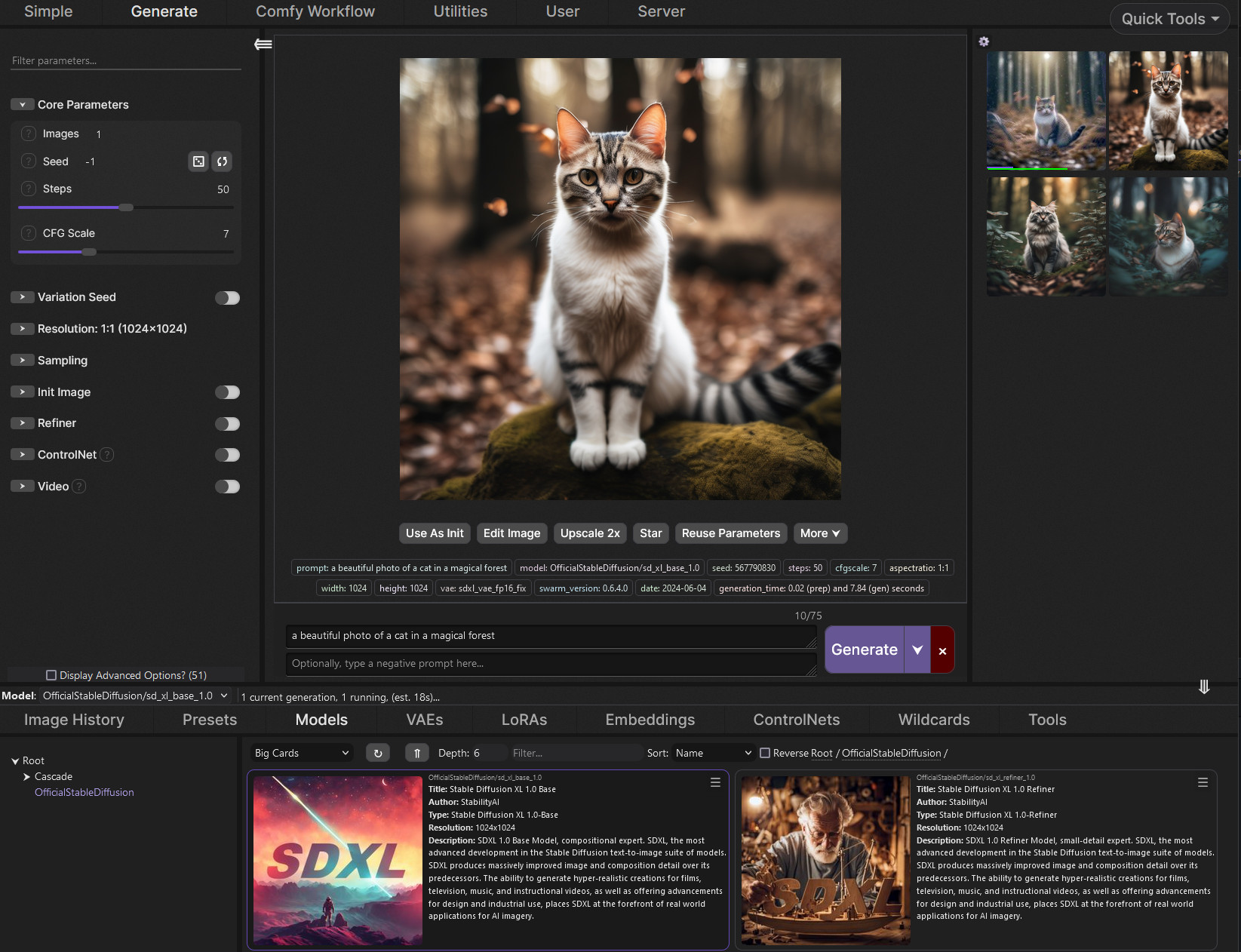
A Modular AI Image Generation Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. Supports AI image models (Stable Diffusion, Flux, etc.), and AI video models (LTX-V, Hunyuan Video, Cosmos, Wan, etc.), with plans to support eg audio and more in the future.
SwarmUI by default runs entirely locally on your own computer. It does not collect any data from you.
SwarmUI is 100% Free-and-Open-Source software, under the MIT License. You can do whatever you want with it.
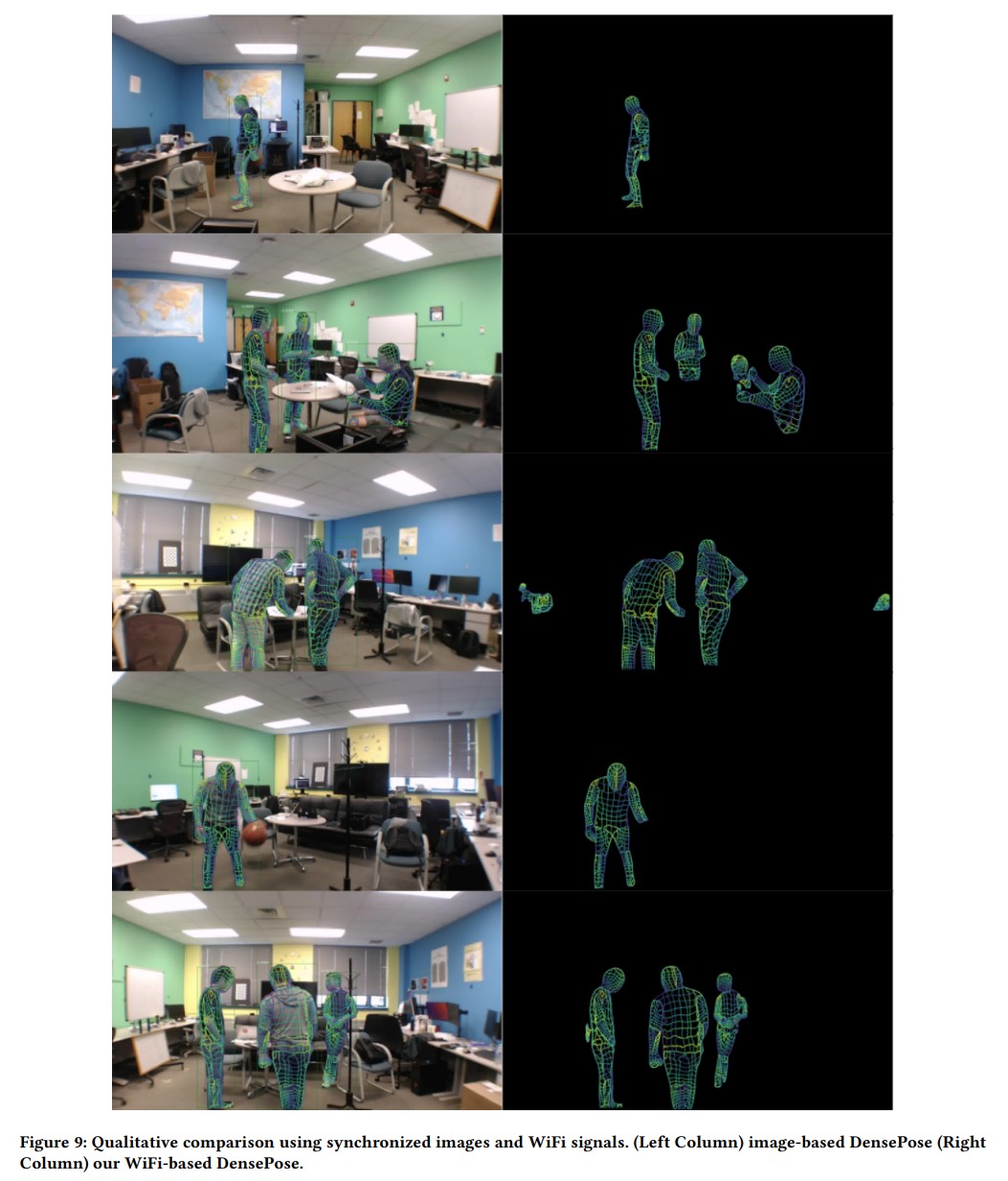
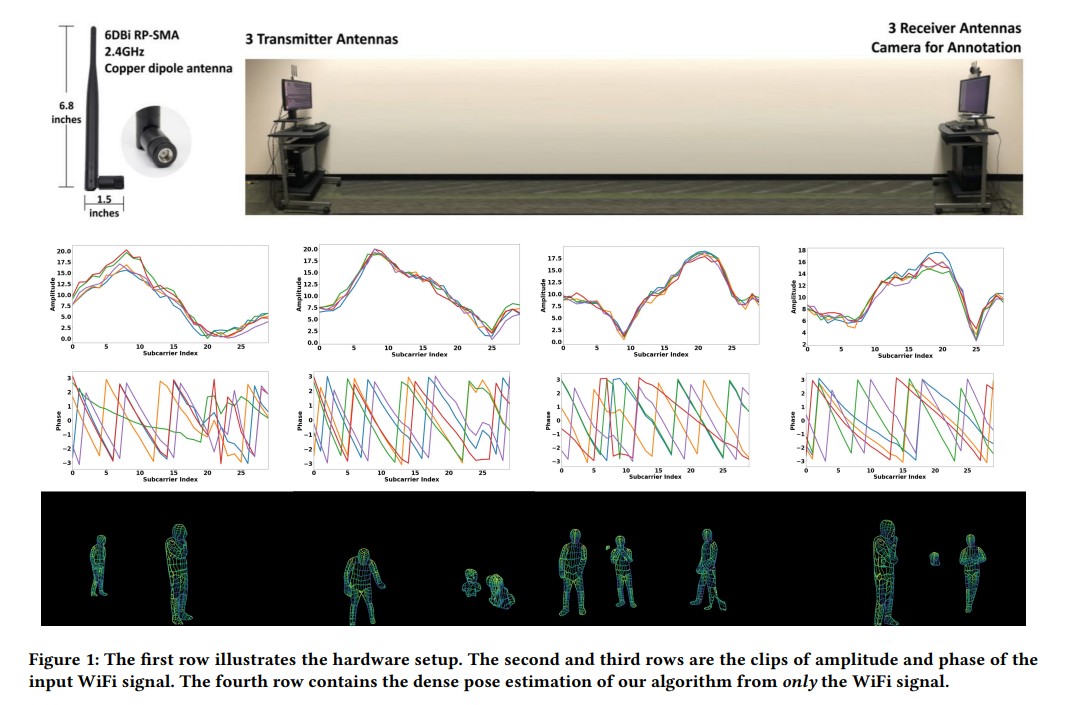
Advances in computer vision and machine learning techniques have led to significant development in 2D and 3D human pose estimation using RGB cameras, LiDAR, and radars. However, human pose estimation from images is adversely affected by common issues such as occlusion and lighting, which can significantly hinder performance in various scenarios.
Radar and LiDAR technologies, while useful, require specialized hardware that is both expensive and power-intensive. Moreover, deploying these sensors in non-public areas raises important privacy concerns, further limiting their practical applications.
To overcome these limitations, recent research has explored the use of WiFi antennas, which are one-dimensional sensors, for tasks like body segmentation and key-point body detection. Building on this idea, the current study expands the use of WiFi signals in combination with deep learning architectures—techniques typically used in computer vision—to estimate dense human pose correspondence.
In this work, a deep neural network was developed to map the phase and amplitude of WiFi signals to UV coordinates across 24 human regions. The results demonstrate that the model is capable of estimating the dense pose of multiple subjects with performance comparable to traditional image-based approaches, despite relying solely on WiFi signals. This breakthrough paves the way for developing low-cost, widely accessible, and privacy-preserving algorithms for human sensing.
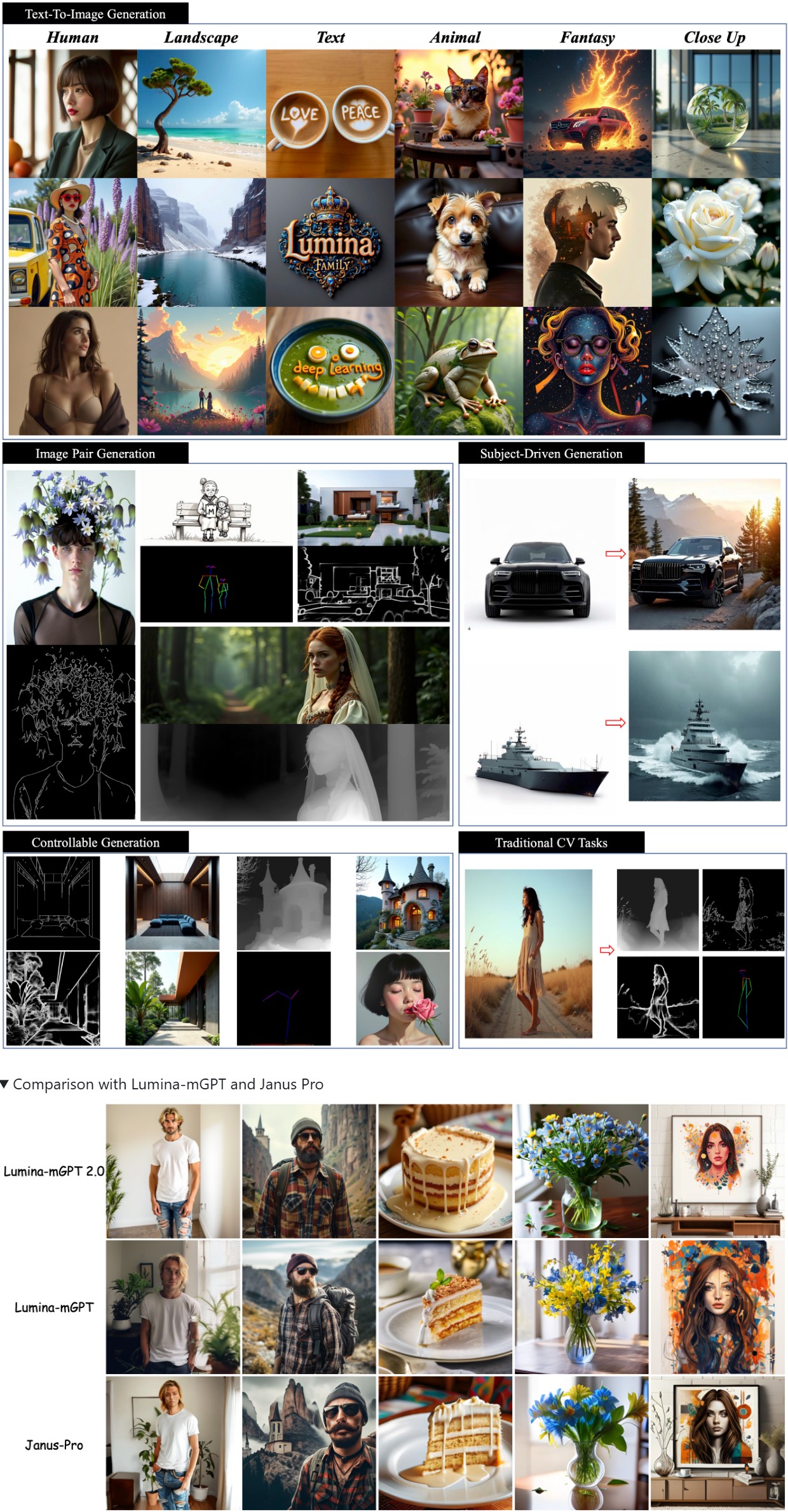
A stand-alone, decoder-only autoregressive model, trained from scratch, that unifies a broad spectrum of image generation tasks, including text-to-image generation, image pair generation, subject-driven generation, multi-turn image editing, controllable generation, and dense prediction.
Playbook3d.com is a diffusion-based render engine that reduces the time to final image with AI. It is accessible via web editor and API with support for scene segmentation and re-lighting, integration with production pipelines and frame-to-frame consistency for image, video, and real-time 3D formats.
7:59-9:50 Justine Bateman: “I mean first I want to give people, help people have a little bit of a definition of what generative AI is— think of it as like a blender and if you have a blender at home and you turn it on, what does it do? It depends on what I put into it, so it cannot function unless it’s fed things.
Then you turn on the blender and you give it a prompt, which is your little spoon, and you get a little spoonful—little Frankenstein spoonful—out of what you asked for. So what is going into the blender? Every but a hundred years of film and television or many, many years of, you know, doctor’s reports or students’ essays or whatever it is.
In the film business, in particular, that’s what we call theft; it’s the biggest violation. And the term that continues to be used is “all we did.” I think the CTO of OpenAI—believe that’s her position; I forget her name—when she was asked in an interview recently what she had to say about the fact that they didn’t ask permission to take it in, she said, “Well, it was all publicly available.”
And I will say this: if you own a car—I know we’re in New York City, so it’s not going to be as applicable—but if I see a car in the street, it’s publicly available, but somehow it’s illegal for me to take it. That’s what we have the copyright office for, and I don’t know how well staffed they are to handle something like this, but this is the biggest copyright violation in the history of that office and the US government”
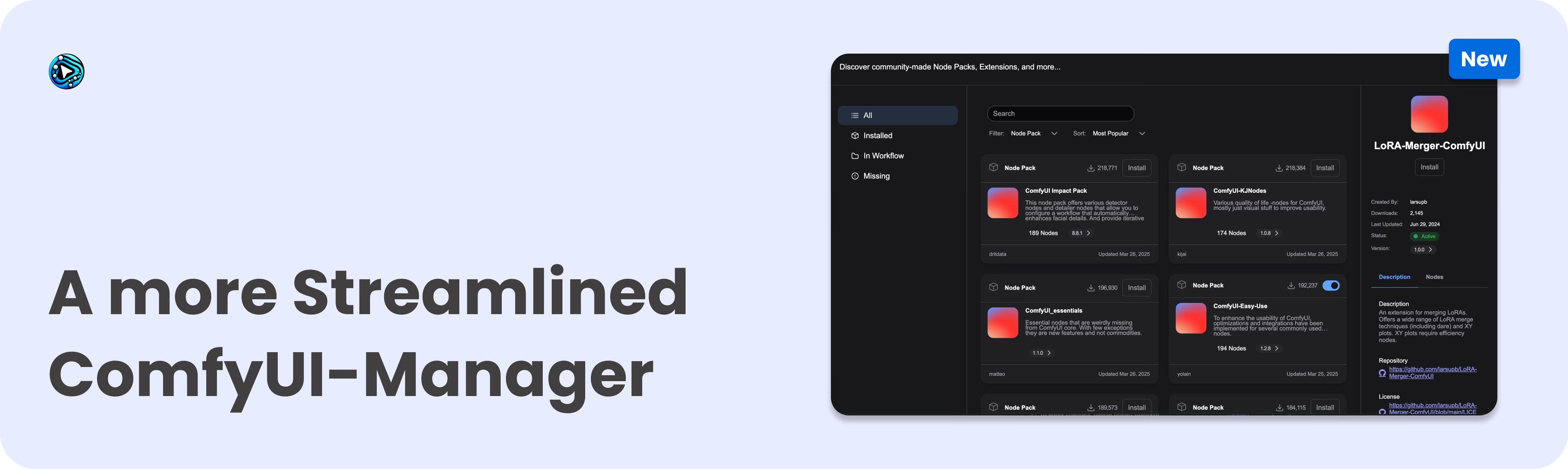
On March 28, ComfyUI-Manager will be moving to the Comfy-Org GitHub organization as Comfy-Org/ComfyUI-Manager. This represents a natural evolution as they continue working to improve the custom node experience for all ComfyUI users.
What This Means For You
This change is primarily about improving support and development velocity. There are a few practical considerations:
Automatic GitHub redirects will ensure all existing links, git commands, and references to the repository will continue to work seamlessly without any action needed
For developers: Any existing PRs and issues will be transferred to the new repository location
For users: ComfyUI-Manager will continue to function exactly as before—no action needed
For workflow authors: Resources that reference ComfyUI-Manager will continue to work without interruption
AccVideo is a novel efficient distillation method to accelerate video diffusion models with synthetic datset. This method is 8.5x faster than HunyuanVideo.
With Gen-4, you are now able to precisely generate consistent characters, locations and objects across scenes. Simply set your look and feel and the model will maintain coherent world environments while preserving the distinctive style, mood and cinematographic elements of each frame. Then, regenerate those elements from multiple perspectives and positions within your scenes.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.