Views : 8




3Dprinting (179) A.I. (899) animation (353) blender (217) colour (241) commercials (53) composition (154) cool (368) design (657) Featured (91) hardware (316) IOS (109) jokes (140) lighting (300) modeling (156) music (189) photogrammetry (197) photography (757) production (1308) python (101) quotes (498) reference (317) software (1379) trailers (308) ves (573) VR (221)
POPULAR SEARCHES unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke

https://draftdocs.acescentral.com/background/whats-new/
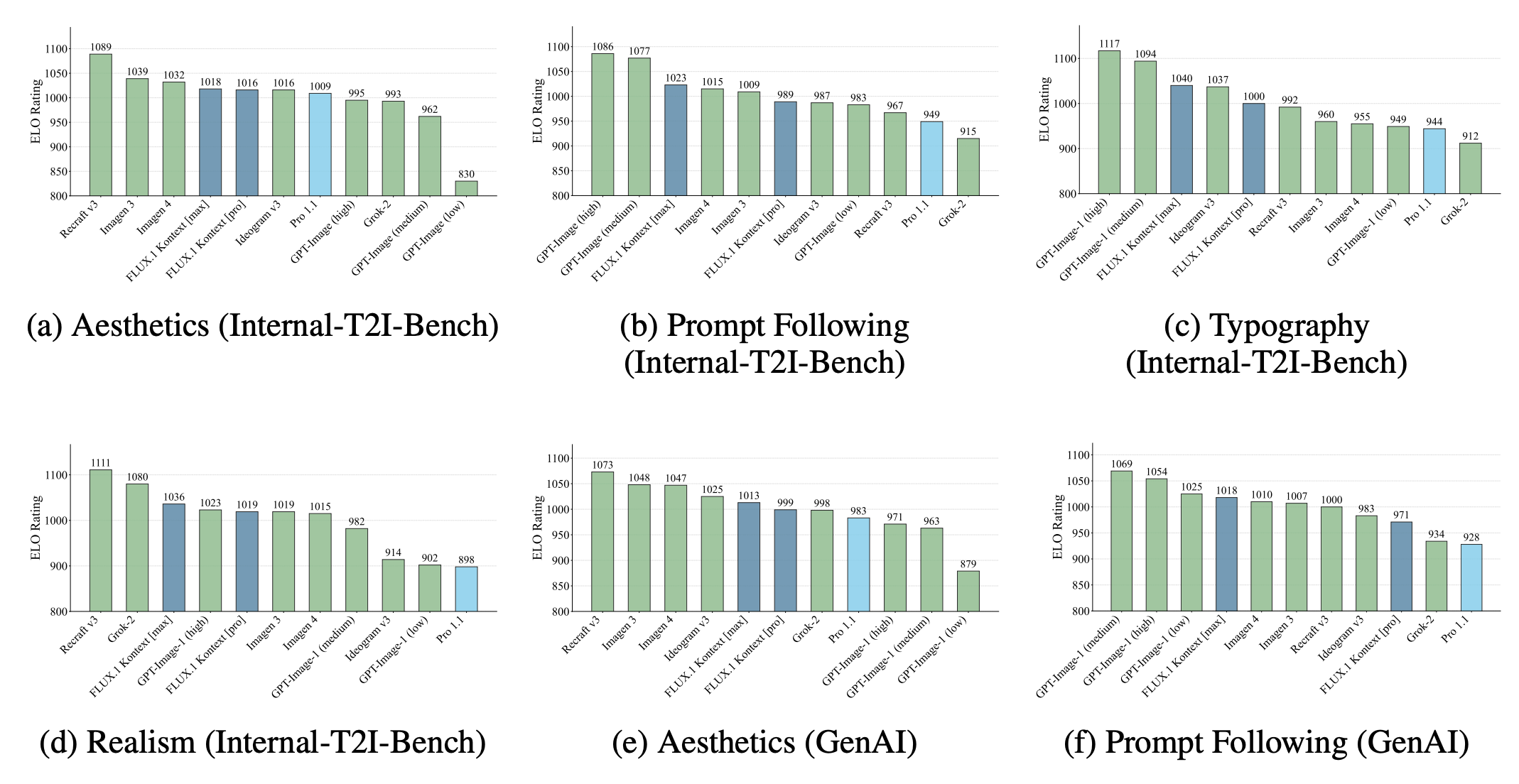
ACES 2.0 is the second major release of the components that make up the ACES system. The most significant change is a new suite of rendering transforms whose design was informed by collected feedback and requests from users of ACES 1. The changes aim to improve the appearance of perceived artifacts and to complete previously unfinished components of the system, resulting in a more complete, robust, and consistent product.
Highlights of the key changes in ACES 2.0 are as follows:
The most substantial change in ACES 2.0 is a complete redesign of the rendering transform.
ACES 2.0 was built as a unified system, rather than through piecemeal additions. Different deliverable outputs “match” better and making outputs to display setups other than the provided presets is intended to be user-driven. The rendering transforms are less likely to produce undesirable artifacts “out of the box”, which means less time can be spent fixing problematic images and more time making pictures look the way you want.
https://github.com/WhatDreamsCost/Spline-Path-Control
https://whatdreamscost.github.io/Spline-Path-Control/
https://github.com/WhatDreamsCost/Spline-Path-Control/tree/main/example_workflows
Spline Path Control is a simple tool designed to make it easy to create motion controls. It allows you to create and animate shapes that follow splines, and then export the result as a .webm video file.
This project was created to simplify the process of generating control videos for tools like VACE. Use it to control the motion of anything (camera movement, objects, humans etc) all without extra prompting.
Linear, Ease-in, Ease-out, and Ease-in-out functions for smooth acceleration and deceleration.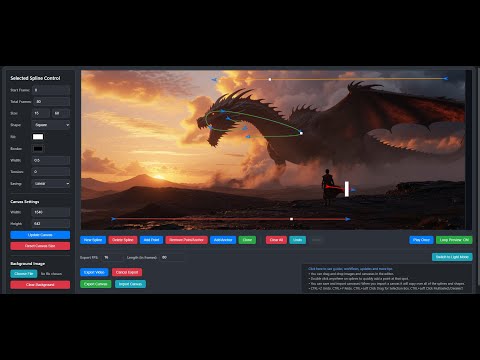
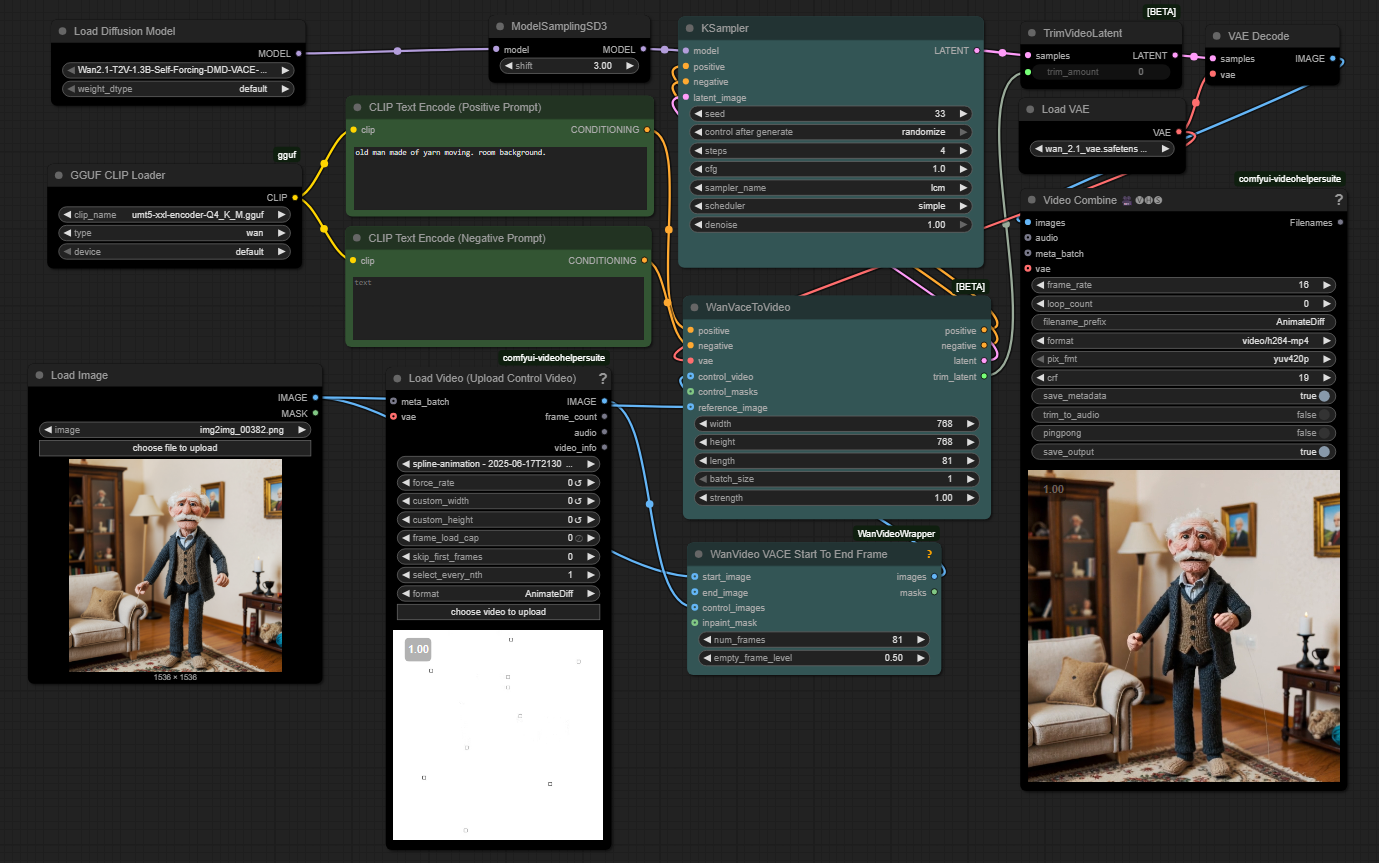
https://github.com/zibojia/MiniMax-Remover
MiniMax-Remover is a fast and effective video object remover based on minimax optimization. It operates in two stages: the first stage trains a remover using a simplified DiT architecture, while the second stage distills a robust remover with CFG removal and fewer inference steps.
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.