



3Dprinting (175) A.I. (733) animation (338) blender (196) colour (229) commercials (49) composition (152) cool (359) design (634) Featured (68) hardware (307) IOS (109) jokes (134) lighting (282) modeling (125) music (185) photogrammetry (177) photography (751) production (1249) python (86) quotes (486) reference (310) software (1330) trailers (296) ves (536) VR (219)
Author: pIXELsHAM.com
-
BEAR – BE-A-Rigger – Maya Rigging Tool
https://github.com/Grackable/bear_core
BEAR claims to be the most intuitive and easy-to-use rigging tool available, offering production-proven features that streamline the rigging workflow for maximum efficiency and consistency.
-
Jellyfish Pictures suspends operations
https://www.broadcastnow.co.uk/post-and-vfx/jellyfish-pictures-suspends-operations/5202847.article
According to a report in Indian news outlet, Animation Xpress, Jellyfish is facing financial struggles and has temporarily suspended its global operations.

-
Judge allows authors AI copyright lawsuit against Meta to move forward
The lawsuit has already provided a few glimpses into how Meta approaches copyright, with court filings from the plaintiffs claiming that Mark Zuckerberg gave the Llama team permission to train the models using copyrighted works and that other Meta team members discussed the use of legally questionable content for AI training.

-
Lumotive Light Control Metasurface – This Tiny Chip Replaces Bulky Optics & Mechanical Mirrors

Programmable Optics for LiDAR and 3D Sensing: How Lumotive’s LCM is Changing the Game
For decades, LiDAR and 3D sensing systems have relied on mechanical mirrors and bulky optics to direct light and measure distance. But at CES 2025, Lumotive unveiled a breakthrough—a semiconductor-based programmable optic that removes the need for moving parts altogether.
The Problem with Traditional LiDAR and Optical Systems
LiDAR and 3D sensing systems work by sending out light and measuring when it returns, creating a precise depth map of the environment. However, traditional systems have relied on physically moving mirrors and lenses, which introduce several limitations:
- Size and weight – Bulky components make integration difficult.
- Complexity – Mechanical parts are prone to failure and expensive to produce.
- Speed limitations – Physical movement slows down scanning and responsiveness.
To bring high-resolution depth sensing to wearables, smart devices, and autonomous systems, a new approach is needed.
Enter the Light Control Metasurface (LCM)
Lumotive’s Light Control Metasurface (LCM) replaces mechanical mirrors with a semiconductor-based optical chip. This allows LiDAR and 3D sensing systems to steer light electronically, just like a processor manages data. The advantages are game-changing:
- No moving parts – Increased durability and reliability
- Ultra-compact form factor – Fits into small devices and wearables
- Real-time reconfigurability – Optics can adapt instantly to changing environments
- Energy-efficient scanning – Focuses on relevant areas, saving power
How Does it Work?
LCM technology works by controlling how light is directed using programmable metasurfaces. Unlike traditional optics that require physical movement, Lumotive’s approach enables light to be redirected with software-controlled precision.
This means:
- No mechanical delays – Everything happens at electronic speeds.
- AI-enhanced tracking – The sensor can focus only on relevant objects.
- Scalability – The same technology can be adapted for industrial, automotive, AR/VR, and smart city applications.
Live Demo: Real-Time 3D Sensing
At CES 2025, Lumotive showcased how their LCM-enabled sensor can scan a room in real time, creating an instant 3D point cloud. Unlike traditional LiDAR, which has a fixed scan pattern, this system can dynamically adjust to track people, objects, and even gestures on the fly.
This is a huge leap forward for AI-powered perception systems, allowing cameras and sensors to interpret their environment more intelligently than ever before.
Who Needs This Technology?
Lumotive’s programmable optics have the potential to disrupt multiple industries, including:
- Automotive – Advanced LiDAR for autonomous vehicles
- Industrial automation – Precision 3D scanning for robotics and smart factories
- Smart cities – Real-time monitoring of public spaces
- AR/VR/XR – Depth-aware tracking for immersive experiences
The Future of 3D Sensing Starts Here
Lumotive’s Light Control Metasurface represents a fundamental shift in how we think about optics and 3D sensing. By bringing programmability to light steering, it opens up new possibilities for faster, smarter, and more efficient depth-sensing technologies.
With traditional LiDAR now facing a serious challenge, the question is: Who will be the first to integrate programmable optics into their designs?
-
ComfyDock – The Easiest (Free) Way to Safely Run ComfyUI Sessions in a Boxed Container
https://www.reddit.com/r/comfyui/comments/1j2x4qv/comfydock_the_easiest_free_way_to_run_comfyui_in/
ComfyDock is a tool that allows you to easily manage your ComfyUI environments via Docker.
Common Challenges with ComfyUI
- Custom Node Installation Issues: Installing new custom nodes can inadvertently change settings across the whole installation, potentially breaking the environment.
- Workflow Compatibility: Workflows are often tested with specific custom nodes and ComfyUI versions. Running these workflows on different setups can lead to errors and frustration.
- Security Risks: Installing custom nodes directly on your host machine increases the risk of malicious code execution.
How ComfyDock Helps
- Environment Duplication: Easily duplicate your current environment before installing custom nodes. If something breaks, revert to the original environment effortlessly.
- Deployment and Sharing: Workflow developers can commit their environments to a Docker image, which can be shared with others and run on cloud GPUs to ensure compatibility.
- Enhanced Security: Containers help to isolate the environment, reducing the risk of malicious code impacting your host machine.



-
Why the Solar Maximum means peak Northern Lights in 2025
https://northernlightscanada.com/explore/solar-maximum
Every 11 years the Sun’s magnetic pole flips. Leading up to this event, there is a period of increased solar activity — from sunspots and solar flares to spectacular northern and southern lights. The current solar cycle began in 2019 and scientists predict it will peak sometime in 2024 or 2025 before the Sun returns to a lower level of activity in the early 2030s.
The most dramatic events produced by the solar photosphere (the “surface” of the Sun) are coronal mass ejections. When these occur and solar particles get spewed out into space, they can wash over the Earth and interact with our magnetic field. This interaction funnels the charged particles towards Earth’s own North and South magnetic poles — where the particles interact with molecules in Earth’s ionosphere and cause them to fluoresce — phenomena known as aurora borealis (northern lights) and aurora australis (southern lights).
In 2019, it was predicted that the solar maximum would likely occur sometime around July 2025. However, Nature does not have to conform with our predictions, and seems to be giving us the maximum earlier than expected.

Very strong solar activity — especially the coronal mass ejections — can indeed wreak some havoc on our satellite and communication electronics. Most often, it is fairly minor — we get what is known as a “radio blackout” that interferes with some of our radio communications. Once in a while, though, a major solar event occurs. The last of these was in 1859 in what is now known as the Carrington Event, which knocked out telegraph communications across Europe and North America. Should a similar solar storm happen today it would be fairly devastating, affecting major aspects of our infrastructure including our power grid and, (gasp), the internet itself.
-
Mike Seymour – Amid Industry Collapses, with guest panelist Scott Ross (ex ILM and DD)
Beyond Technicolor’s specific challenges, the broader VFX industry continues to grapple with systemic issues, including cost-cutting pressures, exploitative working conditions, and an unsustainable business model. VFX houses often operate on razor-thin margins, competing in a race to the bottom due to studios’ demand for cheaper and faster work. This results in a cycle of overwork, burnout, and, in many cases, eventual bankruptcy, as seen with Rhythm & Hues in 2013 and now at Technicolor. The reliance on tax incentives and outsourcing further complicates matters, making VFX work highly unstable. With major vendors collapsing and industry workers facing continued uncertainty, many are calling for structural changes, including better contracts, collective bargaining, and a more sustainable production pipeline. Without meaningful reform, the industry risks seeing more historic names disappear and countless skilled artists move to other fields.

-
Niels Cautaerts – Python dependency management is a dumpster fire
https://nielscautaerts.xyz/python-dependency-management-is-a-dumpster-fire.html
For many modern programming languages, the associated tooling has the lock-file based dependency management mechanism baked in. For a great example, consider Rust’s Cargo.
(more…)
Not so with Python.
The default package manager for Python is pip. The default instruction to install a package is to runpip install package. Unfortunately, this imperative approach for creating your environment is entirely divorced from the versioning of your code. You very quickly end up in a situation where you have 100’s of packages installed. You no longer know which packages you explicitly asked to install, and which packages got installed because they were a transitive dependency. You no longer know which version of the code worked in which environment, and there is no way to roll back to an earlier version of your environment. Installing any new package could break your environment.
… -
Meta Avat3r – Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars
https://tobias-kirschstein.github.io/avat3r
Avat3r takes 4 input images of a person’s face and generates an animatable 3D head avatar in a single forward pass. The resulting 3D head representation can be animated at interactive rates. The entire creation process of the 3D avatar, from taking 4 smartphone pictures to the final result, can be executed within minutes.

https://www.uploadvr.com/meta-researchers-generate-photorealistic-avatars-from-just-four-selfies
-
Shadow of Mordor’s brilliant Nemesis system is locked away by a Warner Bros patent until 2036, despite studio shutdown
The Nemesis system, for those unfamiliar, is a clever in-game mechanic which tracks a player’s actions to create enemies that feel capable of remembering past encounters. In the studio’s Middle-earth games, this allowed foes to rise through the ranks and enact revenge.
The patent itself – which you can view here – was originally filed back in 2016, before it was granted in 2021. It is dubbed “Nemesis characters, nemesis forts, social vendettas and followers in computer games”. As it stands, the patent has an expiration date of 11th August, 2036.

-
Crypto Mining Attack via ComfyUI/Ultralytics in 2024
https://github.com/ultralytics/ultralytics/issues/18037
zopieux on Dec 5, 2024 : Ultralytics was attacked (or did it on purpose, waiting for a post mortem there), 8.3.41 contains nefarious code downloading and running a crypto miner hosted as a GitHub blob.

-
Walt Disney Animation Abandons Longform Streaming Content
https://www.hollywoodreporter.com/business/business-news/tiana-disney-series-shelved-1236153297
A spokesperson confirmed there will be some layoffs in its Vancouver studio as a result of this shift in business strategy. In addition to the Tiana series, the studio is also scrapping an unannounced feature-length project that was set to go straight to Disney+.
Insiders say that Walt Disney Animation remains committed to releasing one theatrical film per year in addition to other shorts and special projects

-
Andreas Horn – The 9 algorithms
The illustration below highlights the algorithms most frequently utilized in our everyday activities: They play a key role in everything we do from online shopping recommendations, navigation apps, social media, email spam filters and even smart home devices.
 𝗦𝗼𝗿𝘁𝗶𝗻𝗴 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺
𝗦𝗼𝗿𝘁𝗶𝗻𝗴 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺
– Organize data for efficiency.
➜ Example: Sorting email threads or search results. 𝗗𝗶𝗷𝗸𝘀𝘁𝗿𝗮’𝘀 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺
– Finds the shortest path in networks.
➜ Example: Google Maps driving routes. 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀
– AI models that understand context and meaning.
➜ Example: ChatGPT, Claude and other LLMs. 𝗟𝗶𝗻𝗸 𝗔𝗻𝗮𝗹𝘆𝘀𝗶𝘀
– Ranks pages and builds connections.
➜ Example: TikTok PageRank, LinkedIn recommendations. 𝗥𝗦𝗔 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺
– Encrypts and secures data communication.
➜ Example: WhatsApp encryption or online banking. 𝗜𝗻𝘁𝗲𝗴𝗲𝗿 𝗙𝗮𝗰𝘁𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻
– Secures cryptographic systems.
➜ Example: Protecting sensitive data in blockchain. 𝗖𝗼𝗻𝘃𝗼𝗹𝘂𝘁𝗶𝗼𝗻𝗮𝗹 𝗡𝗲𝘂𝗿𝗮𝗹 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝘀 (𝗖𝗡𝗡𝘀)
– Recognizes patterns in images and videos.
➜ Example: Facial recognition, object detection in self-driving cars. 𝗛𝘂𝗳𝗳𝗺𝗮𝗻 𝗖𝗼𝗱𝗶𝗻𝗴
– Compresses data efficiently.
➜ Example: JPEG and MP3 file compression. 𝗦𝗲𝗰𝘂𝗿𝗲 𝗛𝗮𝘀𝗵 𝗔𝗹𝗴𝗼𝗿𝗶𝘁𝗵𝗺 (𝗦𝗛𝗔)
– Ensures data integrity.
➜ Example: Password encryption, digital signatures.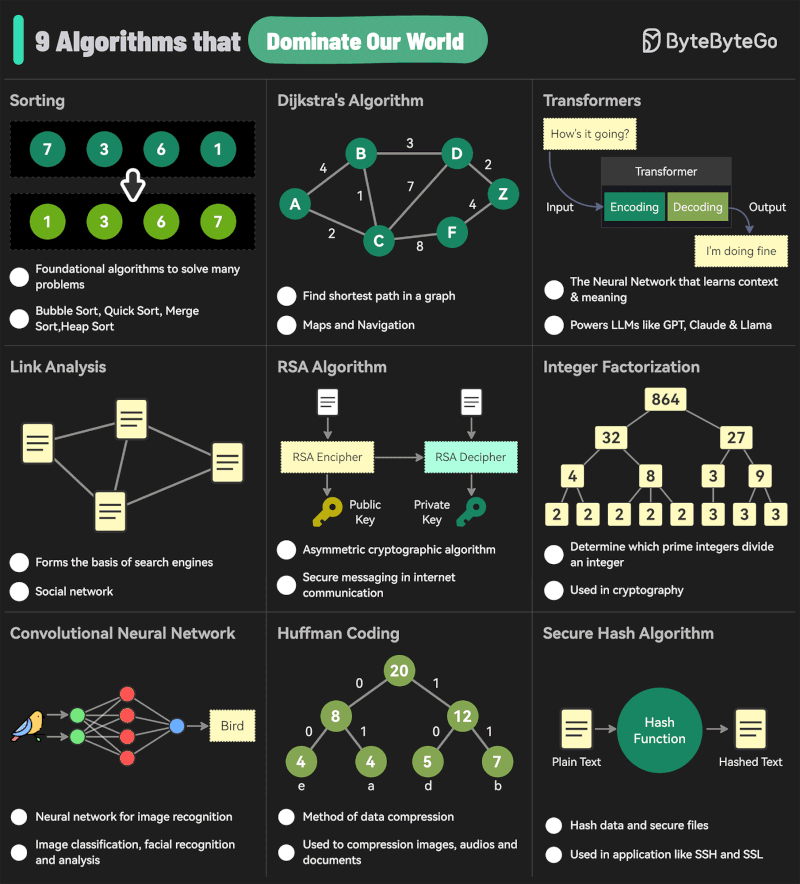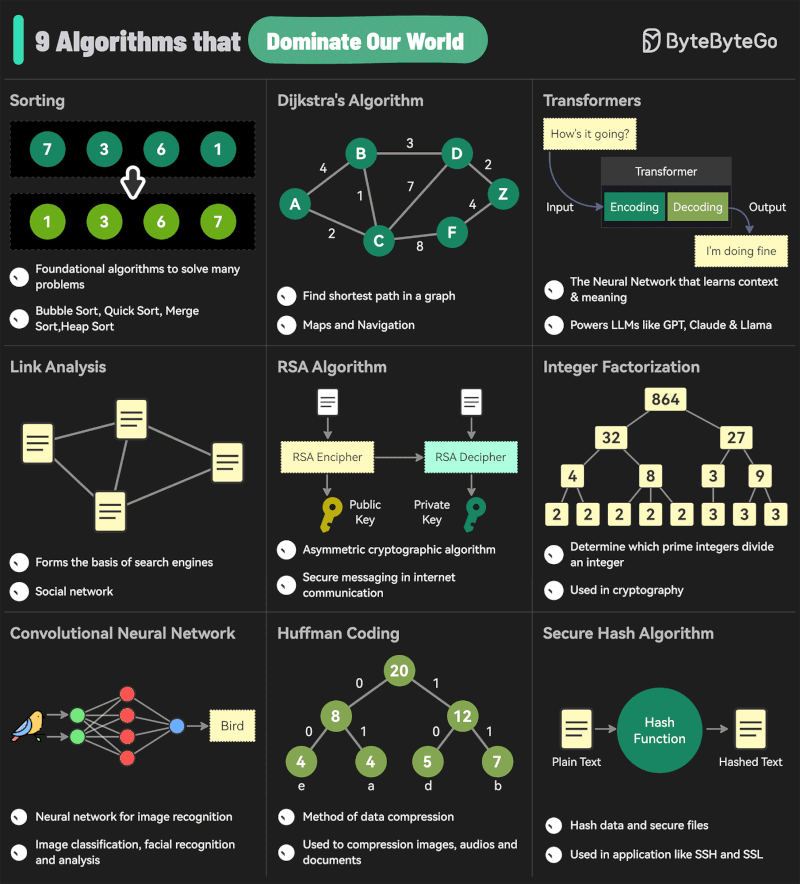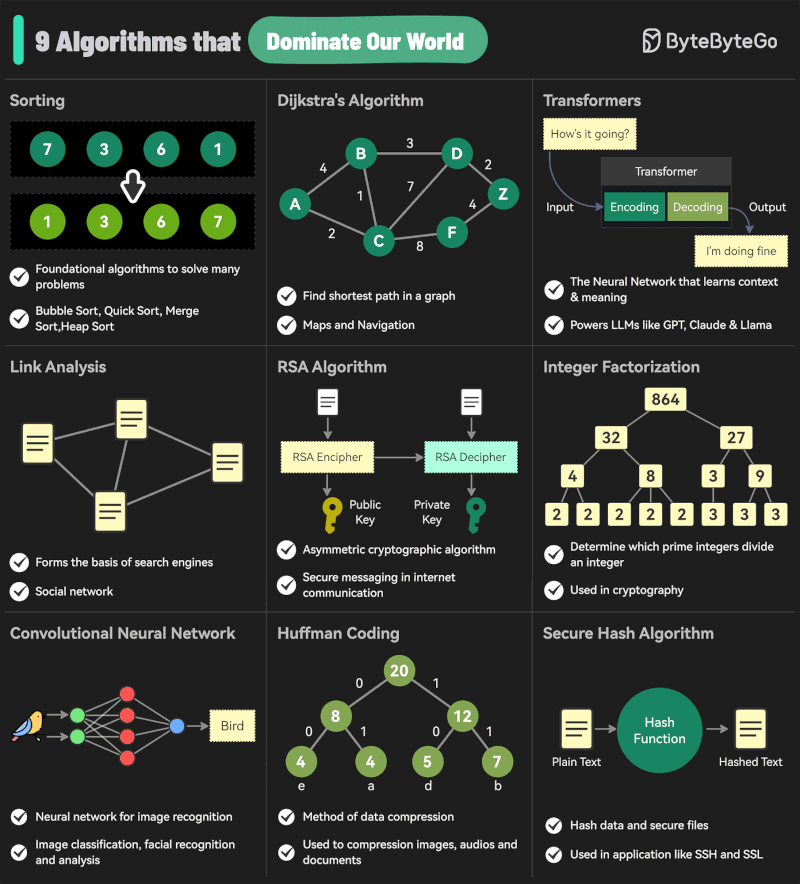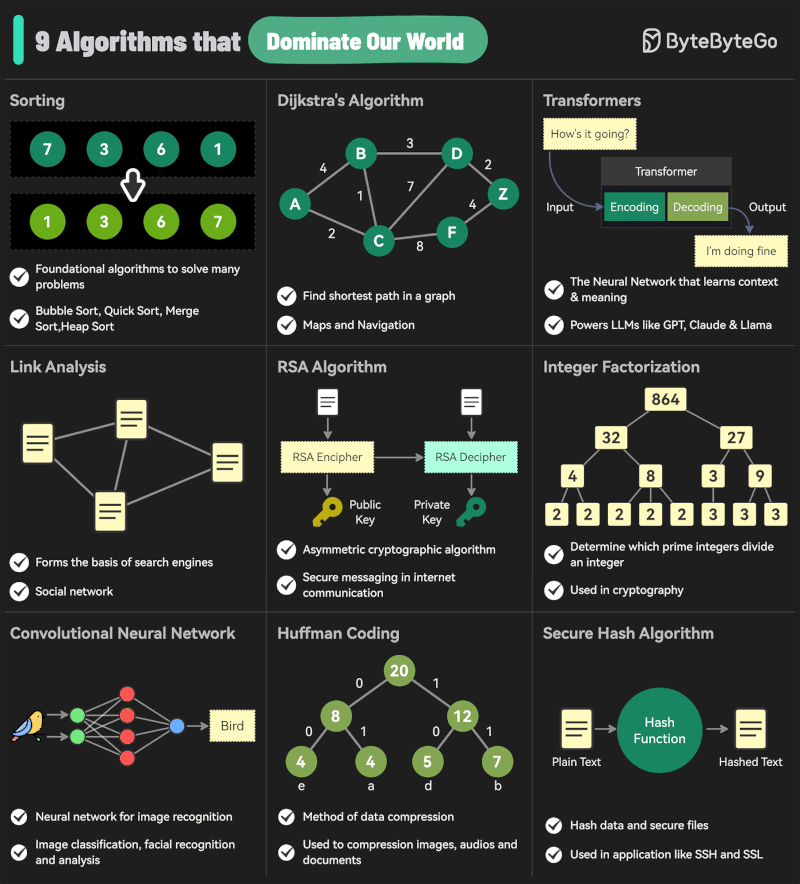
-
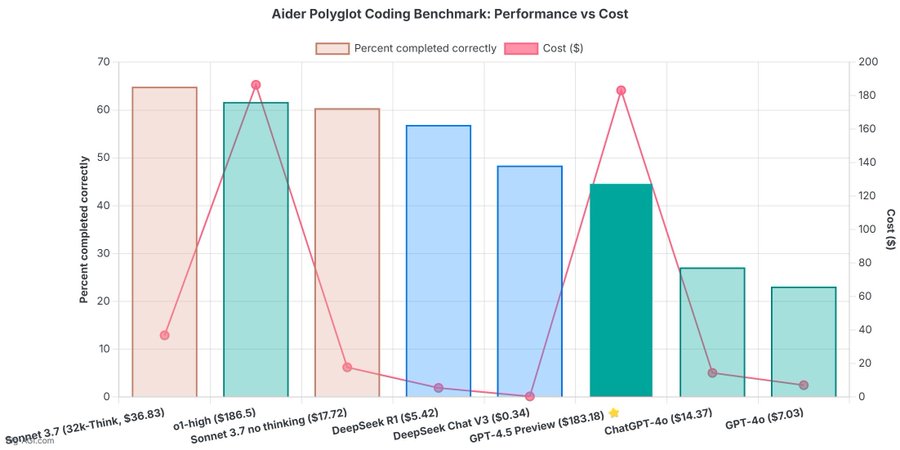
OpenAI 4.5 model arrives to mixed reviews
The verdict is in: OpenAI’s newest and most capable traditional AI model, GPT-4.5, is big, expensive, and slow, providing marginally better performance than GPT-4o at 30x the cost for input and 15x the cost for output. The new model seems to prove that longstanding rumors of diminishing returns in training unsupervised-learning LLMs were correct and that the so-called “scaling laws” cited by many for years have possibly met their natural end.
-
Walter Murch – “In the Blink of an Eye” – A perspective on cut editing
https://www.amazon.ca/Blink-Eye-Revised-2nd/dp/1879505622
Celebrated film editor Walter Murch’s vivid, multifaceted, thought-provoking essay on film editing. Starting with the most basic editing question — Why do cuts work? — Murch takes the reader on a wonderful ride through the aesthetics and practical concerns of cutting film. Along the way, he offers unique insights on such subjects as continuity and discontinuity in editing, dreaming, and reality; criteria for a good cut; the blink of the eye as an emotional cue; digital editing; and much more. In this second edition, Murch revises his popular first edition’s lengthy meditation on digital editing in light of technological changes. Francis Ford Coppola says about this book: “Nothing is as fascinating as spending hours listening to Walter’s theories of life, cinema and the countless tidbits of wisdom that he leaves behind like Hansel and Gretel’s trail of breadcrumbs…….”

Version 1.0.0




















 Security Alert: Crypto Mining Attack via ComfyUI/Ultralytics
Security Alert: Crypto Mining Attack via ComfyUI/Ultralytics

COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
-
UV maps
-
How do LLMs like ChatGPT (Generative Pre-Trained Transformer) work? Explained by Deep-Fake Ryan Gosling
-
How to paint a boardgame miniatures
-
QR code logos
-
Scene Referred vs Display Referred color workflows
-
Ethan Roffler interviews CG Supervisor Daniele Tosti
-
Game Development tips
-
Principles of Animation with Alan Becker, Dermot OConnor and Shaun Keenan
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.