Views : 27




3Dprinting (184) A.I. (923) animation (354) blender (220) colour (241) commercials (53) composition (154) cool (375) design (660) Featured (94) hardware (319) IOS (109) jokes (141) lighting (300) modeling (160) music (189) photogrammetry (199) photography (757) production (1310) python (108) quotes (501) reference (318) software (1384) trailers (310) ves (577) VR (221)
POPULAR SEARCHES unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
Listen to the podcast in the post
“I just created a AI-Generated podcast by feeding an article I write into Google’s NotebookLM. If I hadn’t make it myself, I would have been 100% fooled into thinking it was real people talking.”
The model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU.
https://github.com/apple/ml-depth-pro
https://arxiv.org/pdf/2410.02073


https://www.colour-science.org/anders-langlands/
This page compares images rendered in Arnold using spectral rendering and different sets of colourspace primaries: Rec.709, Rec.2020, ACES and DCI-P3. The SPD data for the GretagMacbeth Color Checker are the measurements of Noburu Ohta, taken from Mansencal, Mauderer and Parsons (2014) colour-science.org.

https://bottosson.github.io/posts/colorwrong/
Most software around us today are decent at accurately displaying colors. Processing of colors is another story unfortunately, and is often done badly.
To understand what the problem is, let’s start with an example of three ways of blending green and magenta:

Let’s look at some more examples of blending of colors, to see how these problems surface more practically. The examples use strong colors since then the differences are more pronounced. This is using the same three ways of blending colors as the first example.

Instead of making it as easy as possible to work with color, most software make it unnecessarily hard, by doing image processing with representations not designed for it. Approximating the physical behavior of light with linear RGB models is one easy thing to do, but more work is needed to create image representations tailored for image processing and human perception.
Also see:
https://radiancefields.com/how-ever-(exact-volumetric-ellipsoid-rendering)-does-this-work
https://half-potato.gitlab.io/posts/ever/
Unlike previous methods like Gaussian Splatting, EVER leverages ellipsoids instead of Gaussians and uses Ray Tracing instead of Rasterization. This shift eliminates artifacts like popping and blending inconsistencies, offering sharper and more accurate renderings.


Best alternatives to Adobe:
https://github.com/KenneyNL/Adobe-Alternatives
https://www.theverge.com/2024/10/1/24259369/microsoft-hololens-2-discontinuation-support
Software support for the original HoloLens headset will end on December 10th.
Microsoft’s struggles with HoloLens have been apparent over the past two years.
𝐌𝐞𝐭𝐚 𝐇𝐲𝐩𝐞𝐫𝐬𝐜𝐚𝐩𝐞 𝐢𝐧 𝐚 𝐧𝐮𝐭𝐬𝐡𝐞𝐥𝐥
Hyperscape technology allows us to scan spaces with just a phone and create photorealistic replicas of the physical world with high fidelity. You can experience these digital replicas on the Quest 3 or on the just announced Quest 3S.
https://www.youtube.com/clip/UgkxGlXM3v93kLg1D9qjJIKmvIYW-vHvdbd0
𝐇𝐢𝐠𝐡 𝐅𝐢𝐝𝐞𝐥𝐢𝐭𝐲 𝐄𝐧𝐚𝐛𝐥𝐞𝐬 𝐚 𝐍𝐞𝐰 𝐒𝐞𝐧𝐬𝐞 𝐨𝐟 𝐏𝐫𝐞𝐬𝐞𝐧𝐜𝐞
This level of photorealism will enable a new way to be together, where spaces look, sound, and feel like you are physically there.

𝐒𝐢𝐦𝐩𝐥𝐞 𝐂𝐚𝐩𝐭𝐮𝐫𝐞 𝐩𝐫𝐨𝐜𝐞𝐬𝐬 𝐰𝐢𝐭𝐡 𝐲𝐨𝐮𝐫 𝐦𝐨𝐛𝐢𝐥𝐞 𝐩𝐡𝐨𝐧𝐞
Currently not available, but in the future, it will offer a new way to create worlds in Horizon and will be the easiest way to bring physical spaces to the digital world. Creators can capture physical environments on their mobile device and invite friends, fans, or customers to visit and engage in the digital replicas.
𝐂𝐥𝐨𝐮𝐝-𝐛𝐚𝐬𝐞𝐝 𝐏𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠 𝐚𝐧𝐝 𝐑𝐞𝐧𝐝𝐞𝐫𝐢𝐧𝐠
Using Gaussian Splatting, a 3D modeling technique that renders fine details with high accuracy and efficiency, we process the model input data in the cloud and render the created model through cloud rendering and streaming on Quest 3 and the just announced Quest 3S.
𝐓𝐫𝐲 𝐢𝐭 𝐨𝐮𝐭 𝐲𝐨𝐮𝐫𝐬𝐞𝐥𝐟
If you are in the US and you have a Meta Quest 3 or 3S you can try it out here:
https://www.meta.com/experiences/meta-horizon-hyperscape-demo/7972066712871980/
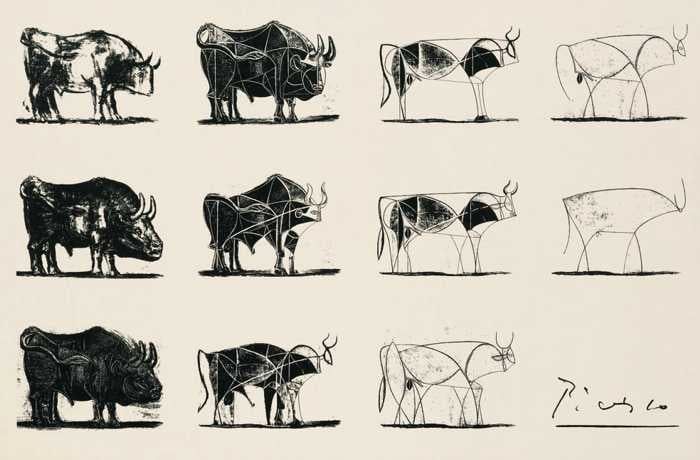
https://www.yankodesign.com/2024/09/18/principles-of-interior-design-balance
The three types of balance include:

In the next couple of decades, we will be able to do things that would have seemed like magic to our grandparents.
This phenomenon is not new, but it will be newly accelerated. People have become dramatically more capable over time; we can already accomplish things now that our predecessors would have believed to be impossible.
We are more capable not because of genetic change, but because we benefit from the infrastructure of society being way smarter and more capable than any one of us; in an important sense, society itself is a form of advanced intelligence. Our grandparents – and the generations that came before them – built and achieved great things. They contributed to the scaffolding of human progress that we all benefit from. AI will give people tools to solve hard problems and help us add new struts to that scaffolding that we couldn’t have figured out on our own. The story of progress will continue, and our children will be able to do things we can’t.
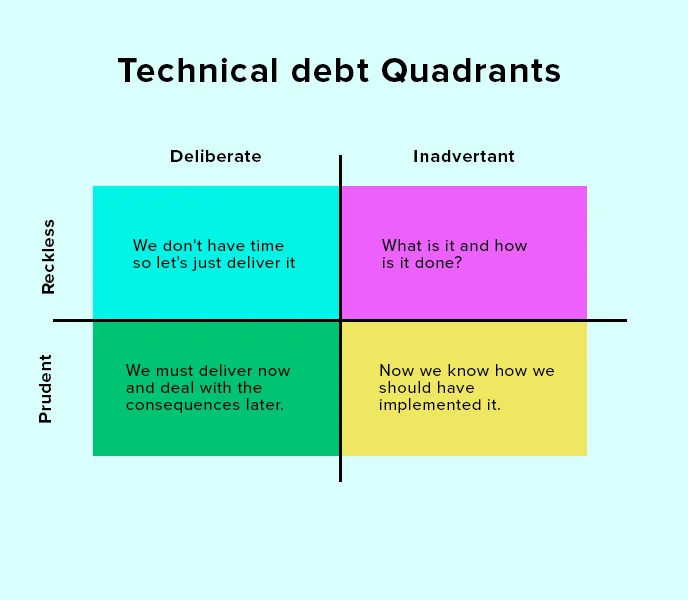
In software development, “technical debt” is a term used to describe the accumulation of shortcuts, suboptimal solutions, and outdated code that occur as developers rush to meet deadlines or prioritize immediate goals over long-term maintainability. While this concept initially seems abstract, its consequences are concrete and can significantly affect the security, usability, and stability of software systems.
Technical debt arises when software engineers choose a less-than-ideal implementation in the interest of saving time or reducing upfront effort. Much like financial debt, these decisions come with an interest rate: over time, the cost of maintaining and updating the system increases, and more effort is required to fix problems that stem from earlier choices. In extreme cases, technical debt can slow development to a crawl, causing future updates or improvements to become far more difficult than they would have been with cleaner, more scalable code.
One of the most significant threats posed by technical debt is the vulnerability it creates in terms of software security. Outdated code often lacks the latest security patches or is built on legacy systems that are no longer supported. Attackers can exploit these weaknesses, leading to data breaches, ransomware, or other forms of cybercrime. Furthermore, as systems grow more complex and the debt compounds, identifying and fixing vulnerabilities becomes increasingly challenging. Failing to address technical debt leaves an organization exposed to security risks that may only become apparent after a costly incident.
Technical debt also affects the user experience. Systems burdened by outdated code often become clunky and slow, leading to poor usability. Engineers may find themselves continuously patching minor issues rather than implementing larger, user-centric improvements. Over time, this results in a product that feels antiquated, is difficult to use, or lacks modern functionality. In a competitive market, poor usability can alienate users, causing a loss of confidence and driving them to alternative products or services.
Stability is another critical area impacted by technical debt. As developers add features or make updates to systems weighed down by previous quick fixes, they run the risk of introducing bugs or causing system crashes. The tangled, fragile nature of code laden with technical debt makes troubleshooting difficult and increases the likelihood of cascading failures. Over time, instability in the software can erode both the trust of users and the efficiency of the development team, as more resources are dedicated to resolving recurring issues rather than innovating or expanding the system’s capabilities.
While technical debt can provide short-term gains by speeding up initial development, the long-term costs are much higher. Unaddressed technical debt can lead to project delays, escalating maintenance costs, and an ever-widening gap between current code and modern best practices. The more technical debt accumulates, the harder and more expensive it becomes to address. For many companies, failing to pay down this debt eventually results in a critical juncture: either invest heavily in refactoring the codebase or face an expensive overhaul to rebuild from the ground up.
Technical debt is an unavoidable aspect of software development, but understanding its perils is essential for minimizing its impact on security, usability, and stability. By actively managing technical debt—whether through regular refactoring, code audits, or simply prioritizing long-term quality over short-term expedience—organizations can avoid the most dangerous consequences and ensure their software remains robust and reliable in an ever-changing technological landscape.
https://insights.daffodilsw.com/blog/technical-debt

https://github.com/jedypod/debayer
The only required dependency is oiiotool. However other “debayer engines” are also supported.
The LibRaw library provides a simple and unified interface for extracting out of RAW files generated by digital photo cameras the following:

Additions:

https://www.bbc.com/future/article/20240912-what-riddles-teach-us-about-the-human-mind
“As human beings, it’s very easy for us to have common sense, and apply it at the right time and adapt it to new problems,” says Ilievski, who describes his branch of computer science as “common sense AI”. But right now, AI has a “general lack of grounding in the world”, which makes that kind of basic, flexible reasoning a struggle.
AI excels at pattern recognition, “but it tends to be worse than humans at questions that require more abstract thinking”, says Xaq Pitkow, an associate professor at Carnegie Mellon University in the US, who studies the intersection of AI and neuroscience. In many cases, though, it depends on the problem.
A bizarre truth about AI is we have no idea how it works. The same is true about the brain.
That’s why the best systems may come from a combination of AI and human work; we can play to the machine’s strengths, Ilievski says.
COLLECTIONS
| Featured AI
| Design And Composition
| Explore posts
POPULAR SEARCHES
unreal | pipeline | virtual production | free | learn | photoshop | 360 | macro | google | nvidia | resolution | open source | hdri | real-time | photography basics | nuke
FEATURED POSTS
Social Links
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.