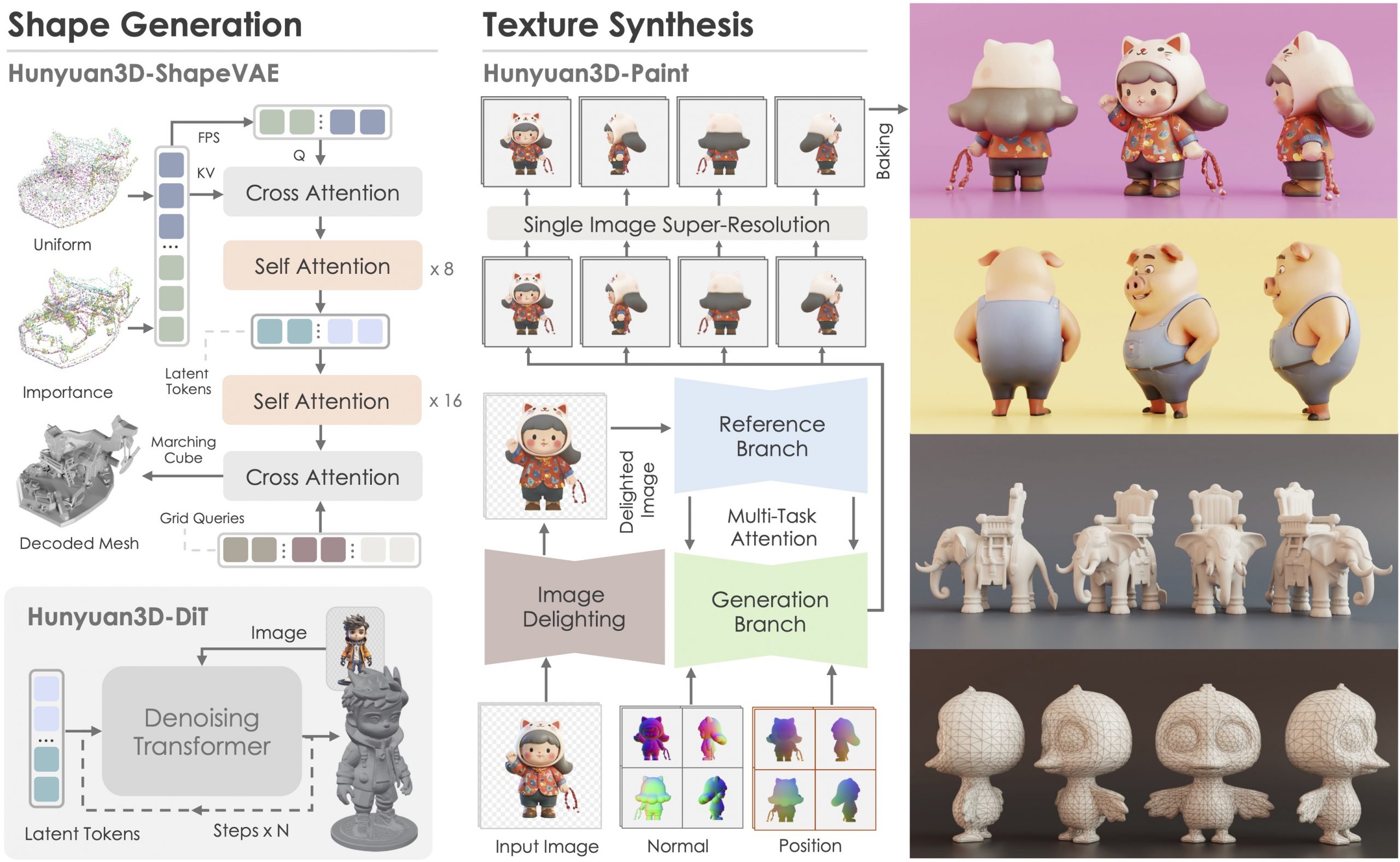
A method for reconstructing photorealistic, animatable head avatars at speeds sufficient for on-the-fly reconstruction. Unlike prior approaches that utilize linear bases from 3D morphable models (3DMM) to model Gaussian blendshapes, our method maps tracked 3DMM parameters into reduced blendshape weights with an MLP, leading to a compact set of blendshape bases.
“Joining Stability AI is an incredible opportunity, and I couldn’t be more excited to help shape the next era of filmmaking,” said Legato. “With dynamic leaders like Prem Akkaraju and James Cameron driving the vision, the potential here is limitless. What excites me most is Stability AI’s commitment to filmmakers—building a tool that is as intuitive as it is powerful, designed to elevate creativity rather than replace it. It’s an artist-first approach to AI, and I’m thrilled to be part of it.”
The Windows Subsystem for Linux (WSL) is a feature of the Windows operating system that enables you to run a Linux file system, along with Linux command-line tools and GUI apps, directly on Windows, alongside your traditional Windows desktop and apps.
But it supposedly also has 45 million subscribers, and with $124.3 million in revenue. Per the company’s most recent earnings, the three months ending in January saw Apple bring in $124.3 billion in revenue, $26.3 billion of which came from Services, a record for the division. That’s just for one quarter. For the year, Services brought in more than $96 billion. It can afford to absorb a billion dollars in losses.
Village Roadshow (prod company/financier: Wonka, the Matrix series, and Ocean’s 11) has filed for bankruptcy. It’s a rough indicator of where we are in 2025 when one of the last independent production companies working with the studios goes under.
Here’s their balance sheet: $400 M in library value of 100+ films (89 of which they co-own with Warner Bros.) $500 M – $1bn total debt $1.4 M in debt to WGA, whose members were told to stop working with Roadshow in December $794 K owed to Bryan Cranston’s prod company $250 K owed to Sony Pictures TV $300 K/month overhead
The crowning expense that brought down this 36-year-old production company is the $18 M in (unpaid) legal fees from a lengthy and currently unresolved arbitration with their long-time partner Warner Bros, who they’ve had a co-financing arrangement since the late 90s.
Roadshow sued when WBD released their Matrix Resurrections (2021) film in theaters and on Max simultaneously, causing Roadshow to withhold their portion of the $190 M production costs.
Due to mounting financial pressures, Village Roadshow’s CEO, Steve Mosko, a veteran film and TV exec, left the company in January. Now, this all falls on the shoulders of Jim Moore, CEO of Vine, an equity firm that owns Village Roadshow, as well as Luc Besson’s prod company EuropaCorp.
For safety considerations, Google mentions a “layered, holistic approach” that maintains traditional robot safety measures like collision avoidance and force limitations. The company describes developing a “Robot Constitution” framework inspired by Isaac Asimov’s Three Laws of Robotics and releasing a dataset unsurprisingly called “ASIMOV” to help researchers evaluate safety implications of robotic actions.
This new ASIMOV dataset represents Google’s attempt to create standardized ways to assess robot safety beyond physical harm prevention. The dataset appears designed to help researchers test how well AI models understand the potential consequences of actions a robot might take in various scenarios. According to Google’s announcement, the dataset will “help researchers to rigorously measure the safety implications of robotic actions in real-world scenarios.”
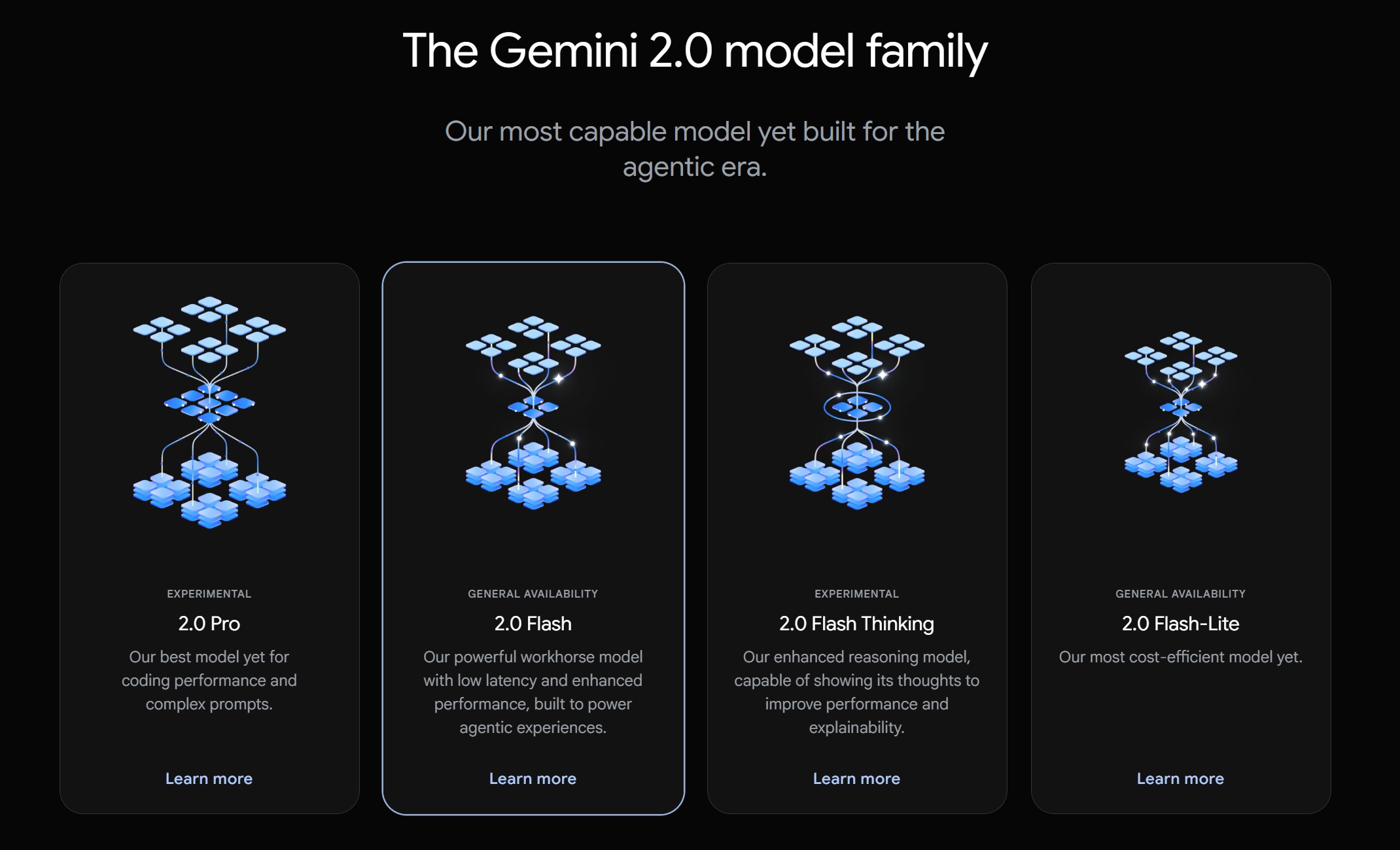
Gemini 2.0 Flash won’t just remove watermarks, but will also attempt to fill in any gaps created by a watermark’s deletion. Other AI-powered tools do this, too, but Gemini 2.0 Flash seems to be exceptionally skilled at it — and free to use.
Stable Virtual Camera offers advanced capabilities for generating 3D videos, including:
Dynamic Camera Control: Supports user-defined camera trajectories as well as multiple dynamic camera paths, including: 360°, Lemniscate (∞ shaped path), Spiral, Dolly Zoom In, Dolly Zoom Out, Zoom In, Zoom Out, Move Forward, Move Backward, Pan Up, Pan Down, Pan Left, Pan Right, and Roll.
Flexible Inputs: Generates 3D videos from just one input image or up to 32.
Multiple Aspect Ratios: Capable of producing videos in square (1:1), portrait (9:16), landscape (16:9), and other custom aspect ratios without additional training.
Long Video Generation: Ensures 3D consistency in videos up to 1,000 frames, enabling seamless
Model limitations
In its initial version, Stable Virtual Camera may produce lower-quality results in certain scenarios. Input images featuring humans, animals, or dynamic textures like water often lead to degraded outputs. Additionally, highly ambiguous scenes, complex camera paths that intersect objects or surfaces, and irregularly shaped objects can cause flickering artifacts, especially when target viewpoints differ significantly from the input images.
A demo video, first reported by The Verge, showed an AI version of the character Aloy from the Playstation game Horizon Forbidden West conversing through voice prompts during gameplay on the PS5 console.
The character’s facial expressions are also powered by Sony’s advanced AI software Mockingbird, while the speech artificially replicates the voice of the actor Ashly Burch.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.