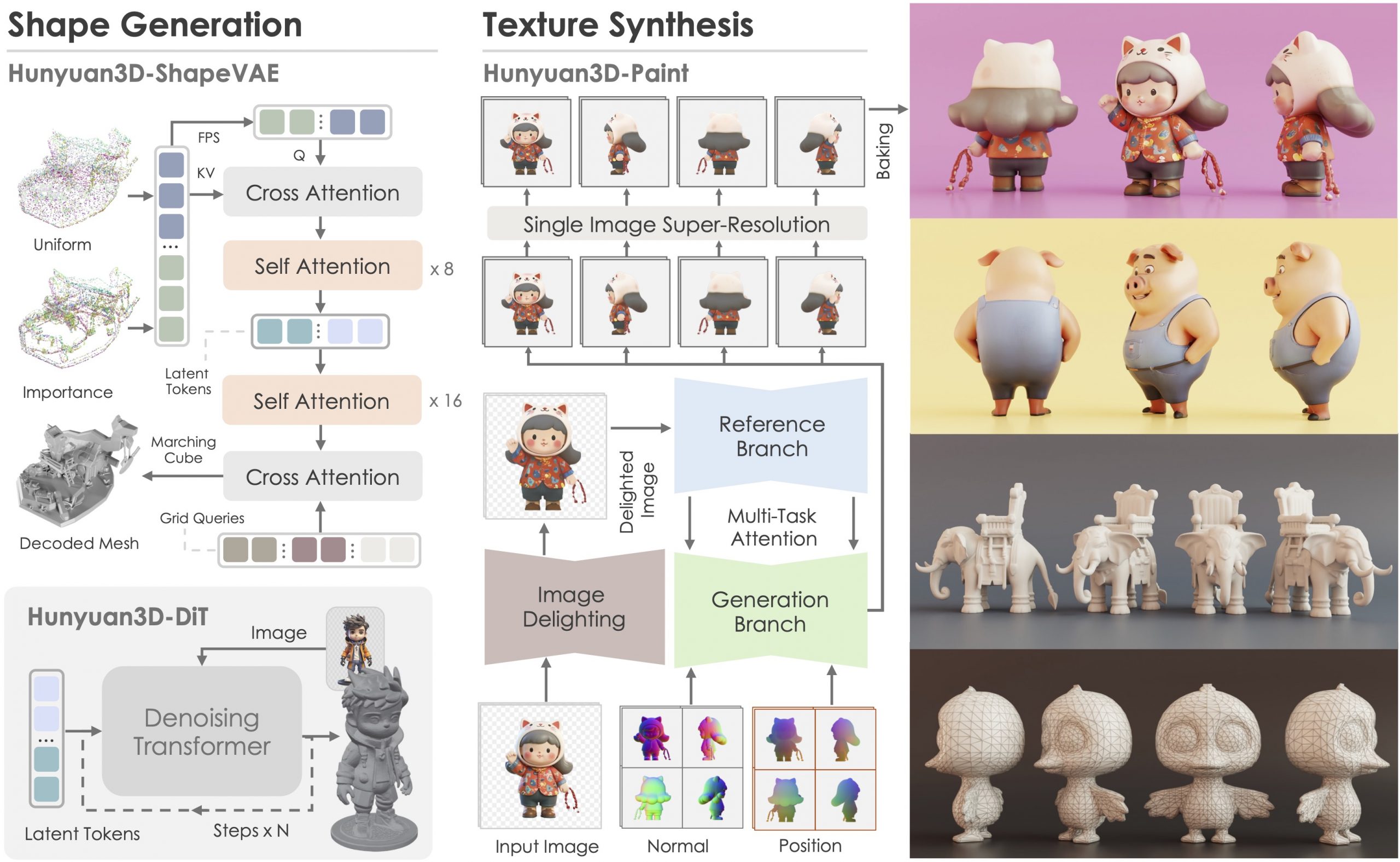
Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model – Hunyuan3D-DiT, and a large-scale texture synthesis model – Hunyuan3D-Paint.
The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio – a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets.
It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and e.t.c.
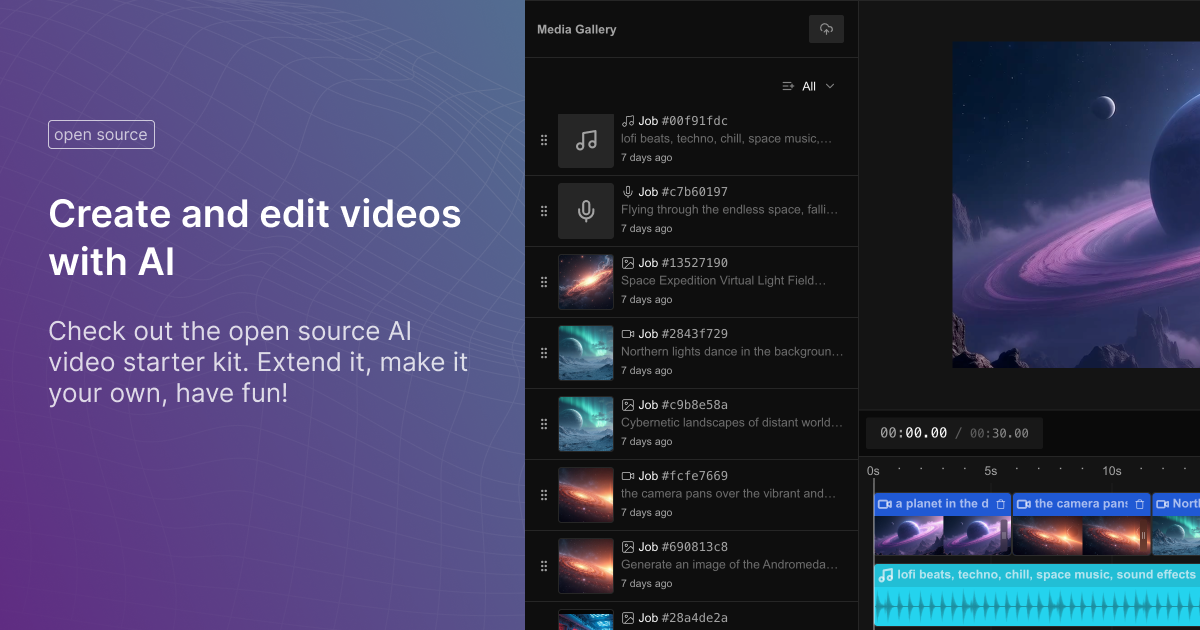
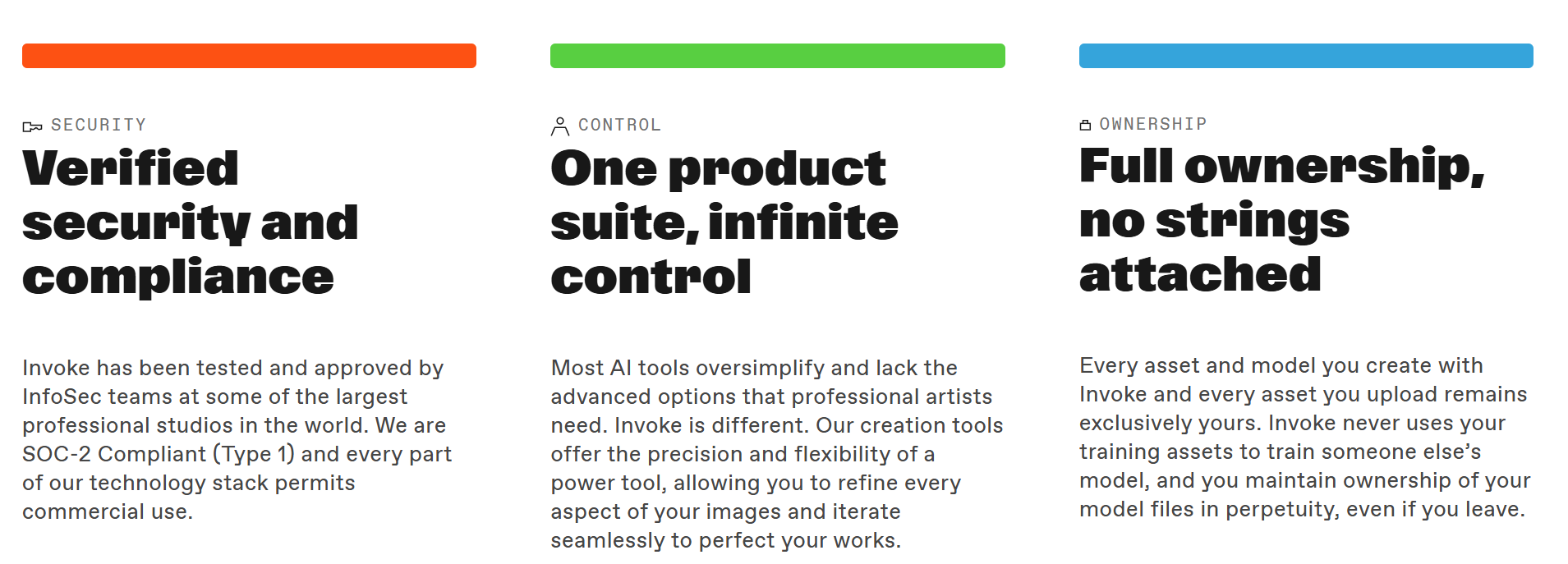
Invoke is a powerful, secure, and easy-to-deploy generative AI platform for professional studios to create visual media. Train models on your intellectual property, control every aspect of the production process, and maintain complete ownership of your data, in perpetuity.
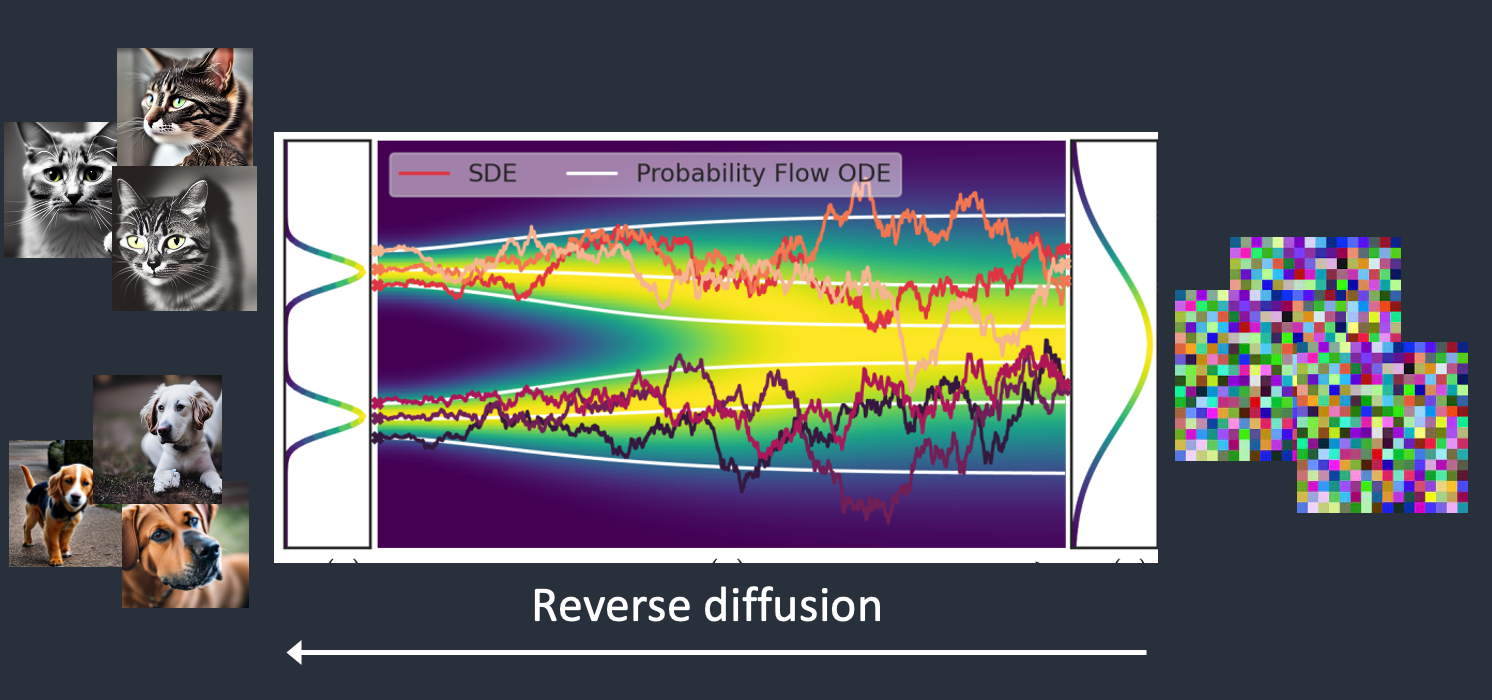
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
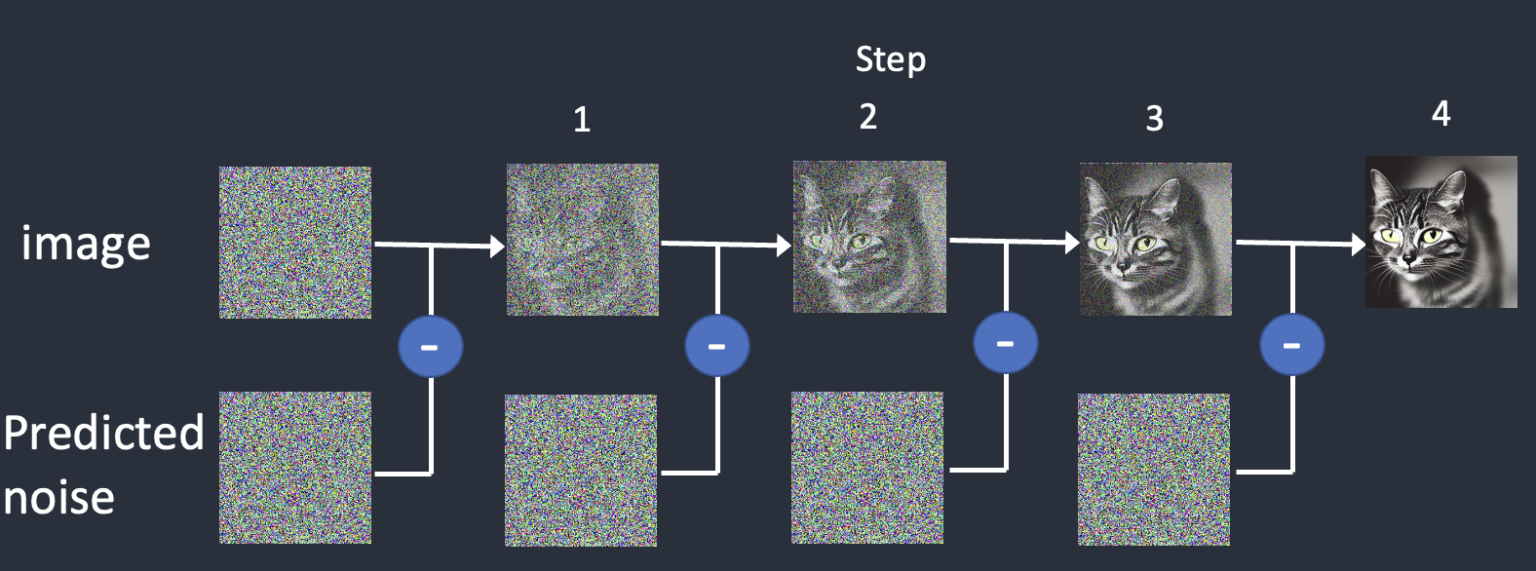
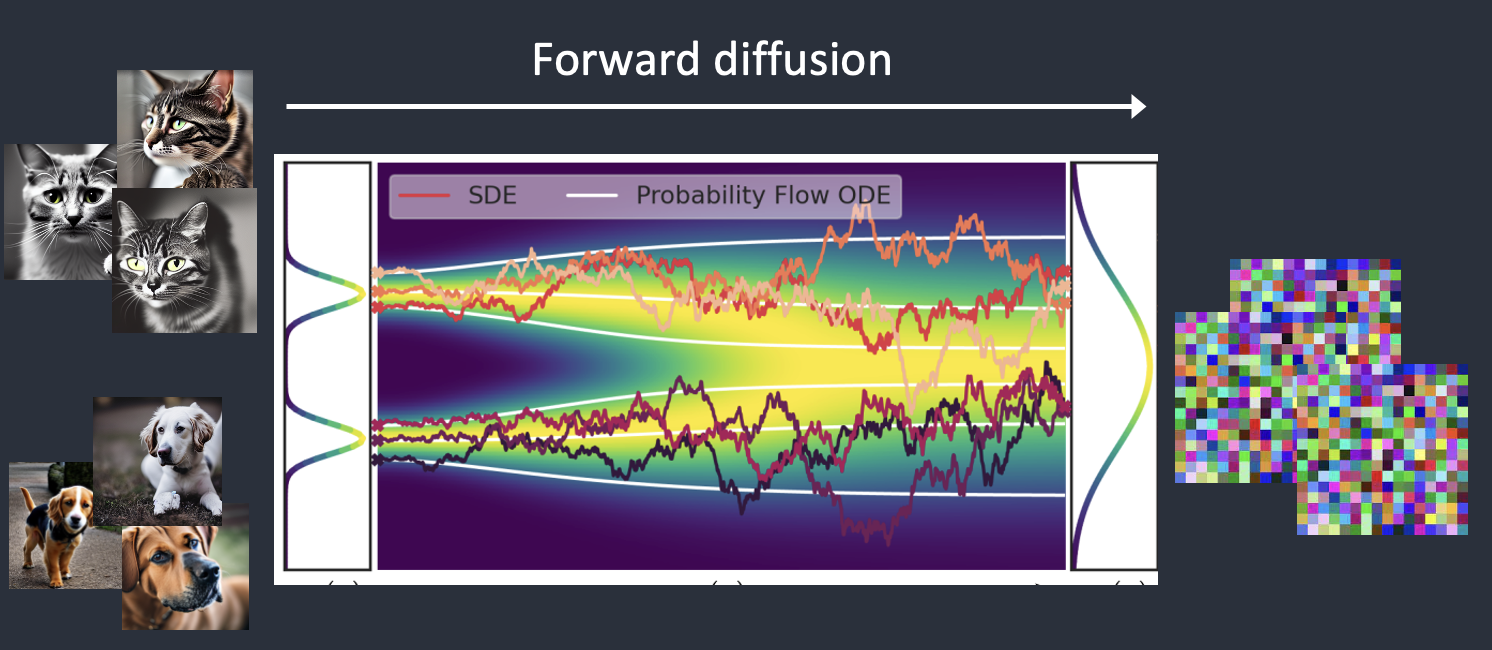
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
This demonstrate large-scale text-to-video generation with a single neural function evaluation (1NFE) by using our proposed adversarial post-training technique. Our model generates 2 seconds of 1280×720 24fps videos in real-time
Jacob Bartlett argues that Swift, once envisioned as a simple and composable programming language by its creator Chris Lattner, has become overly complex due to Apple’s governance. Bartlett highlights that Swift now contains 217 reserved keywords, deviating from its original goal of simplicity. He contrasts Swift’s governance model, where Apple serves as the project lead and arbiter, with other languages like Python and Rust, which have more community-driven or balanced governance structures. Bartlett suggests that Apple’s control has led to Swift’s current state, moving away from Lattner’s initial vision.
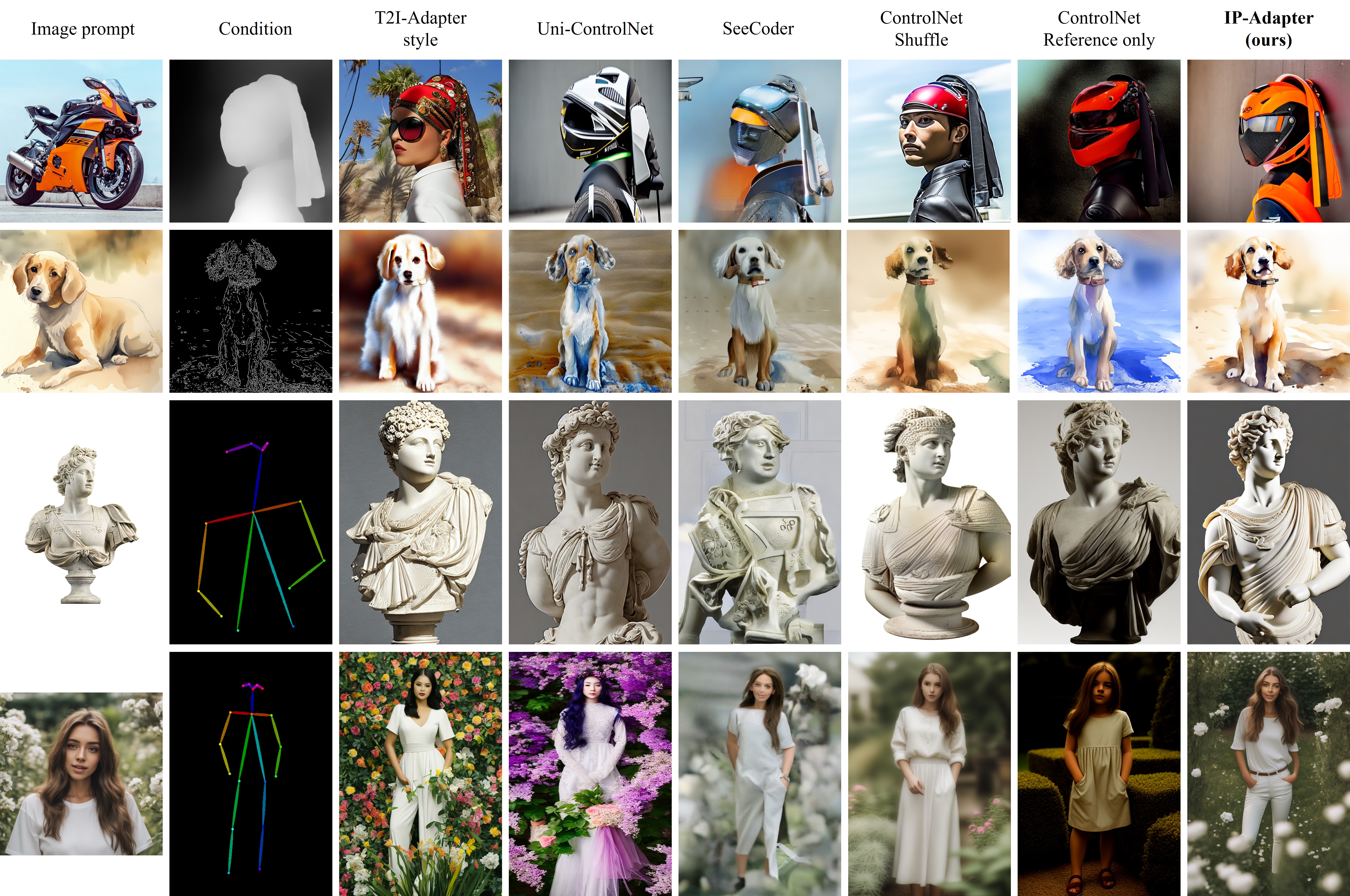
The IPAdapter are very powerful models for image-to-image conditioning. The subject or even just the style of the reference image(s) can be easily transferred to a generation. Think of it as a 1-image lora. They are an effective and lightweight adapter to achieve image prompt capability for the pre-trained text-to-image diffusion models. An IP-Adapter with only 22M parameters can achieve comparable or even better performance to a fine-tuned image prompt model.
Once the IP-Adapter is trained, it can be directly reusable on custom models fine-tuned from the same base model.
The IP-Adapter is fully compatible with existing controllable tools, e.g., ControlNet and T2I-Adapter.
SPAR3D is a fast single-image 3D reconstructor with intermediate point cloud generation, which allows for interactive user edits and achieves state-of-the-art performance.
MiniMax is thrilled to announce the release of the MiniMax-01 series, featuring two groundbreaking models:
MiniMax-Text-01: A foundational language model. MiniMax-VL-01: A visual multi-modal model.
Both models are now open-source, paving the way for innovation and accessibility in AI development!
🔑 Key Innovations
1. Lightning Attention Architecture: Combines 7/8 Lightning Attention with 1/8 Softmax Attention, delivering unparalleled performance.
2. Massive Scale with MoE (Mixture of Experts): 456B parameters with 32 experts and 45.9B activated parameters.
3. 4M-Token Context Window: Processes up to 4 million tokens, 20–32x the capacity of leading models, redefining what’s possible in long-context AI applications.
💡 Why MiniMax-01 Matters
1. Innovative Architecture for Top-Tier Performance
The MiniMax-01 series introduces the Lightning Attention mechanism, a bold alternative to traditional Transformer architectures, delivering unmatched efficiency and scalability.
2. 4M Ultra-Long Context: Ushering in the AI Agent Era
With the ability to handle 4 million tokens, MiniMax-01 is designed to lead the next wave of agent-based applications, where extended context handling and sustained memory are critical.
3. Unbeatable Cost-Effectiveness
Through proprietary architectural innovations and infrastructure optimization, we’re offering the most competitive pricing in the industry:
$0.2 per million input tokens
$1.1 per million output tokens
🌟 Experience the Future of AI Today
We believe MiniMax-01 is poised to transform AI applications across industries. Whether you’re building next-gen AI agents, tackling ultra-long context tasks, or exploring new frontiers in AI, MiniMax-01 is here to empower your vision.
DISCLAIMER – Links and images on this website may be protected by the respective owners’ copyright. All data submitted by users through this site shall be treated as freely available to share.