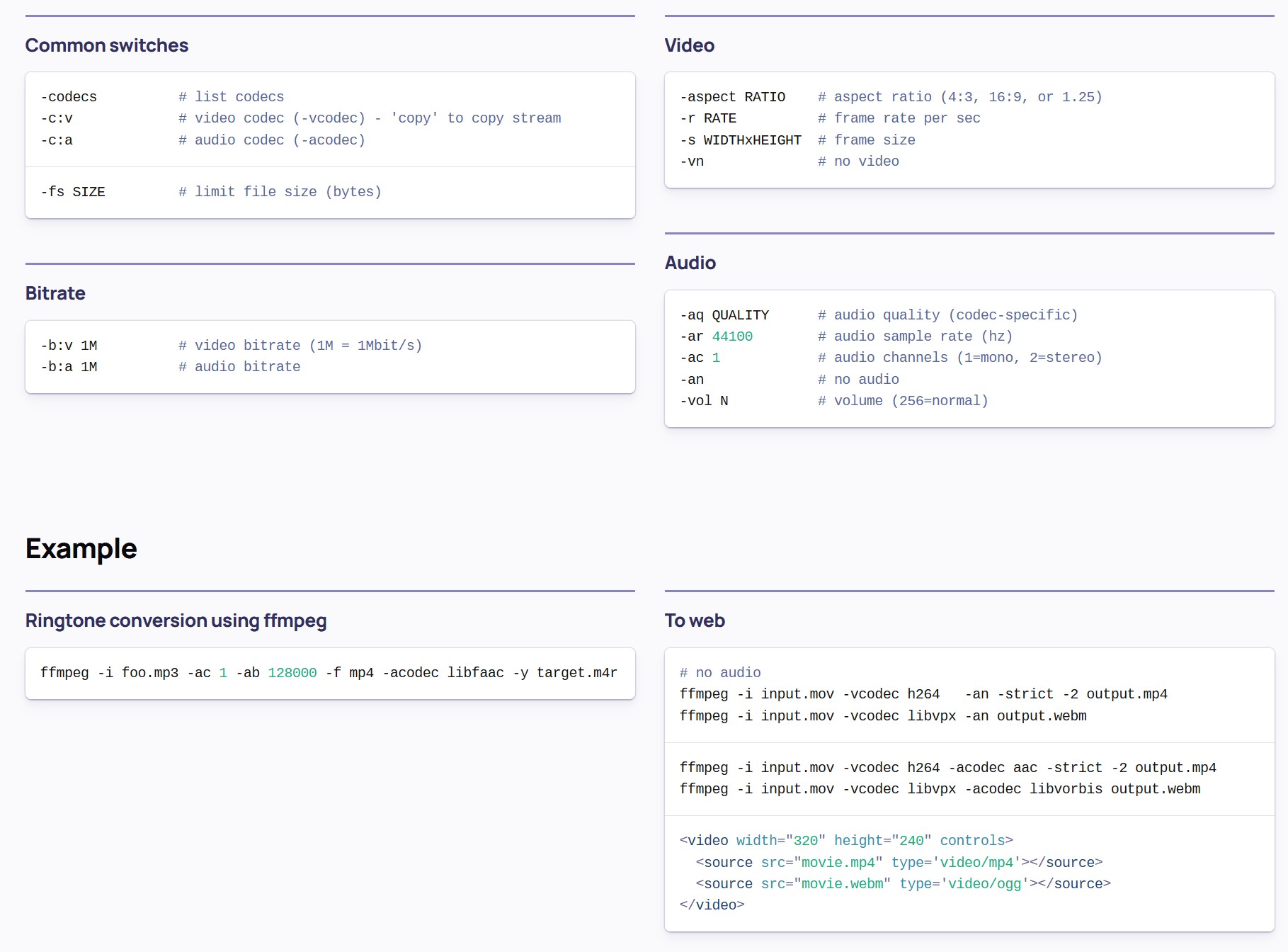
# extract one frame at the end of a video ffmpeg -sseof -0.1 -i intro_1.mp4 -frames:v 1 -q:v 1 intro_end.jpg
-sseof -0.1: This option tells FFmpeg to seek to 0.1 seconds before the end of the file. This approach is often more reliable for extracting the last frame, especially if the video’s duration isn’t an exact multiple of the frame interval. Super User -frames:v 1: Extracts a single frame. -q:v 1: Sets the quality of the output image; 1 is the highest quality.
# extract one frame at the beginning of a video ffmpeg -i speaking_4.mp4 -frames:v 1 speaking_beginning.jpg
# check video length ffmpeg -i C:\myvideo.mp4 -f null –
# Convert mov/mp4 to animated gifEdit ffmpeg -i input.mp4 -pix_fmt rgb24 output.gif Other useful ffmpeg commandsEdit
There’s been no statements as to when Midjourney’s technology will start showing up in Meta’s products, or to what degree it will be baked into the company’s AI strategy.
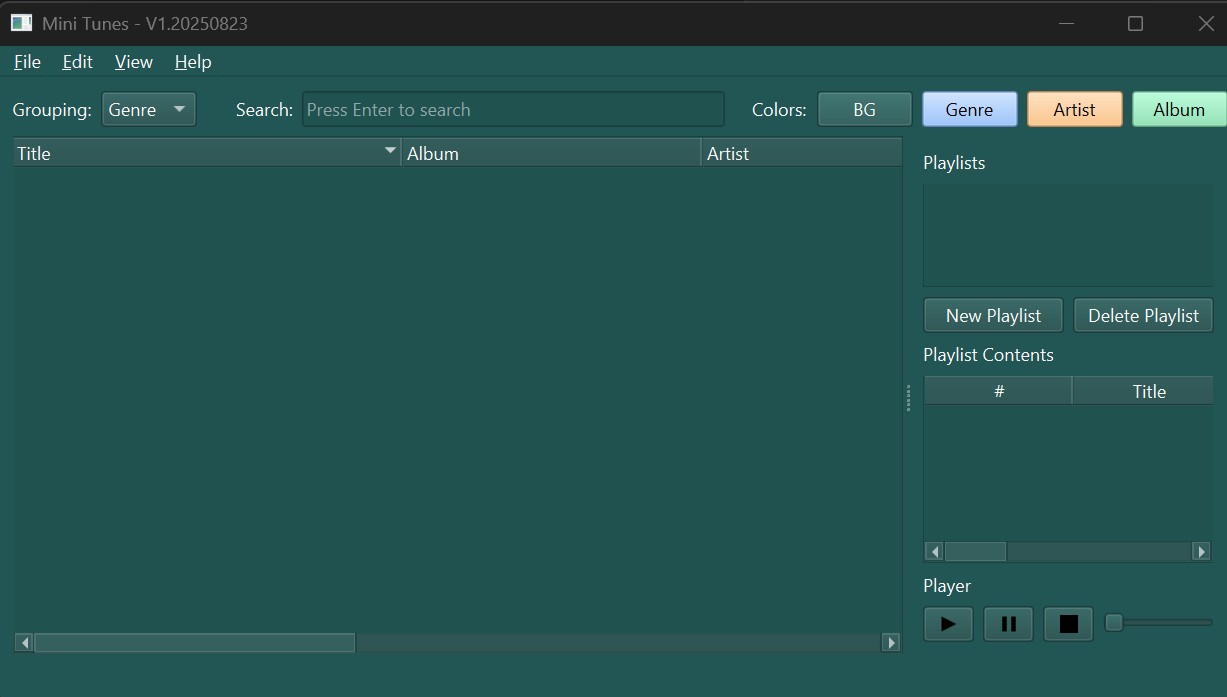
Tired of having iTunes messing up your mp3 library? … Time to try MiniTunes!
– Arrange your library by Genre, Artists or Albums. – Change UI colors at will. – Edit tags and create playlists. – Consolidate your library once for all. – Windows 64 only
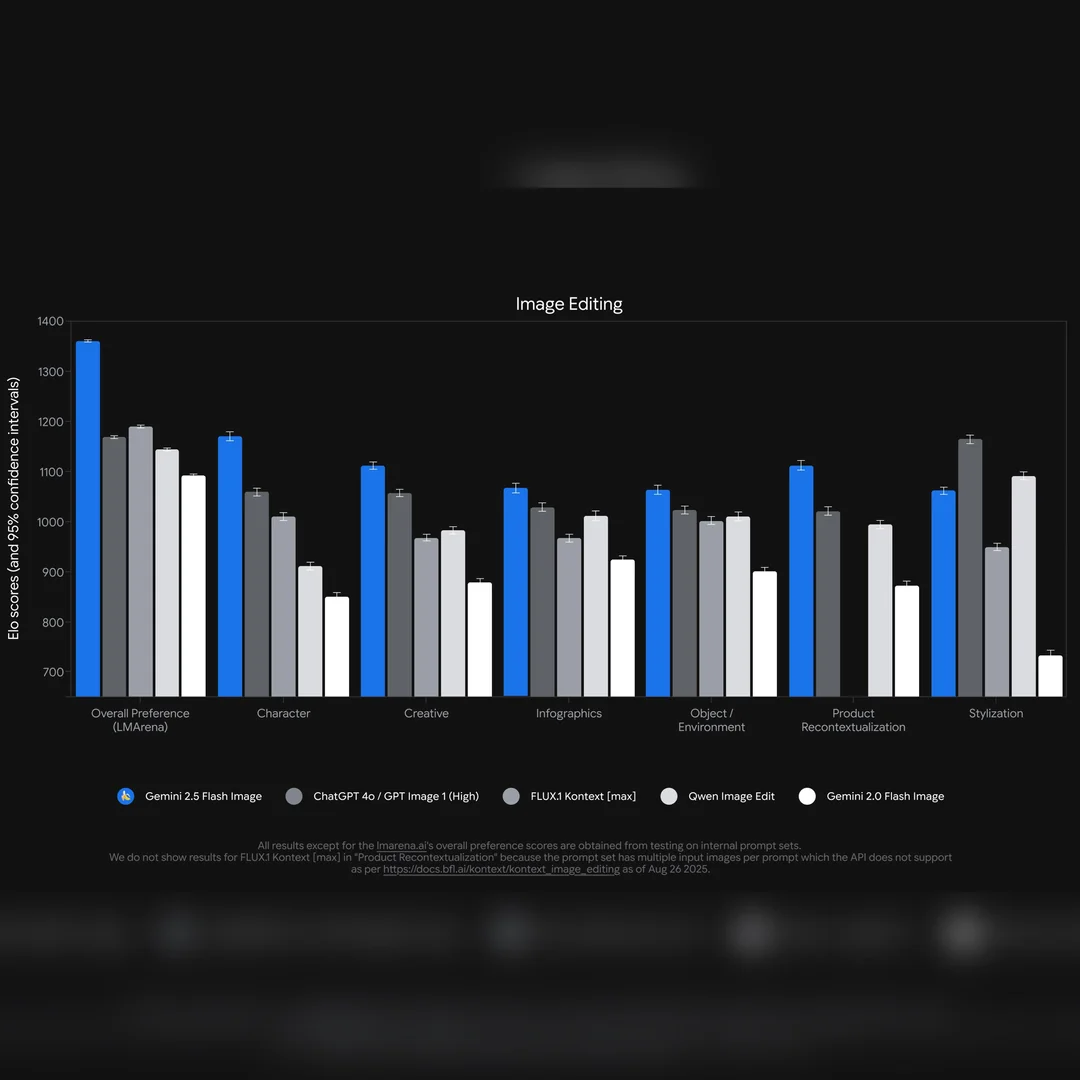
Qwen-Image-Edit is the image editing version of Qwen-Image. It is further trained based on the 20B Qwen-Image model, successfully extending Qwen-Image’s unique text rendering capabilities to editing tasks, enabling precise text editing. In addition, Qwen-Image-Edit feeds the input image into both Qwen2.5-VL (for visual semantic control) and the VAE Encoder (for visual appearance control), thus achieving dual semantic and appearance editing capabilities.
PixiEditor is a universal 2D editor that was made to provide you with tools and features for all your 2D needs. Create beautiful sprites for your games, animations, edit images, create logos. All packed up in an intuitive and familiar interface.
The goal was ambitious: to generate a hyper-detailed 3DGS scan from a massive dataset—20,000 drone photos at full resolution (5280x3956px). All of this on a single machine with just one RTX 4090 GPU.
What was the problem? Most existing tools simply can’t handle this volume of data. For instance, Postshot, which is excellent for many tasks, confidently processed up to 7,000 photos but choked on 20,000—it ran for two days without even starting the model training. The Breakthrough Solution. The real discovery was the software from GreenValley International
Their approach is brilliant: instead of trying to swallow the entire dataset at once, the program intelligently divides it into smaller, manageable chunks, trains each one individually, and then seamlessly merges them into one giant, detailed scene. After 40 hours of rendering, we got this stunning 103 million splats PLY result:
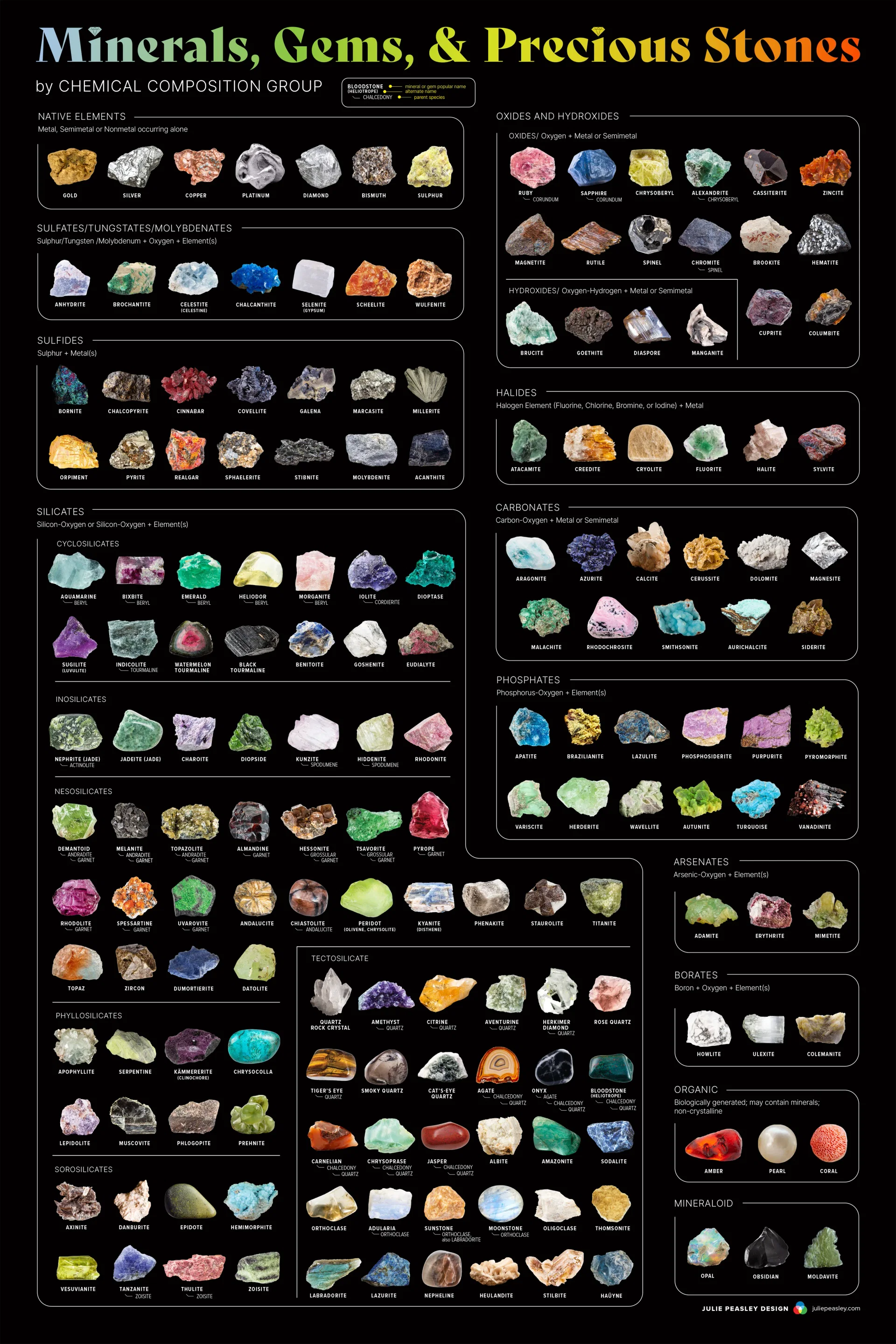
Spectral sensitivity of eye is influenced by light intensity. And the light intensity determines the level of activity of cones cell and rod cell. This is the main characteristic of human vision. Sensitivity to individual colors, in other words, wavelengths of the light spectrum, is explained by the RGB (red-green-blue) theory. This theory assumed that there are three kinds of cones. It’s selectively sensitive to red (700-630 nm), green (560-500 nm), and blue (490-450 nm) light. And their mutual interaction allow to perceive all colors of the spectrum.
























{kind=link}