https://github.com/nnanhuang/SegAnyMo
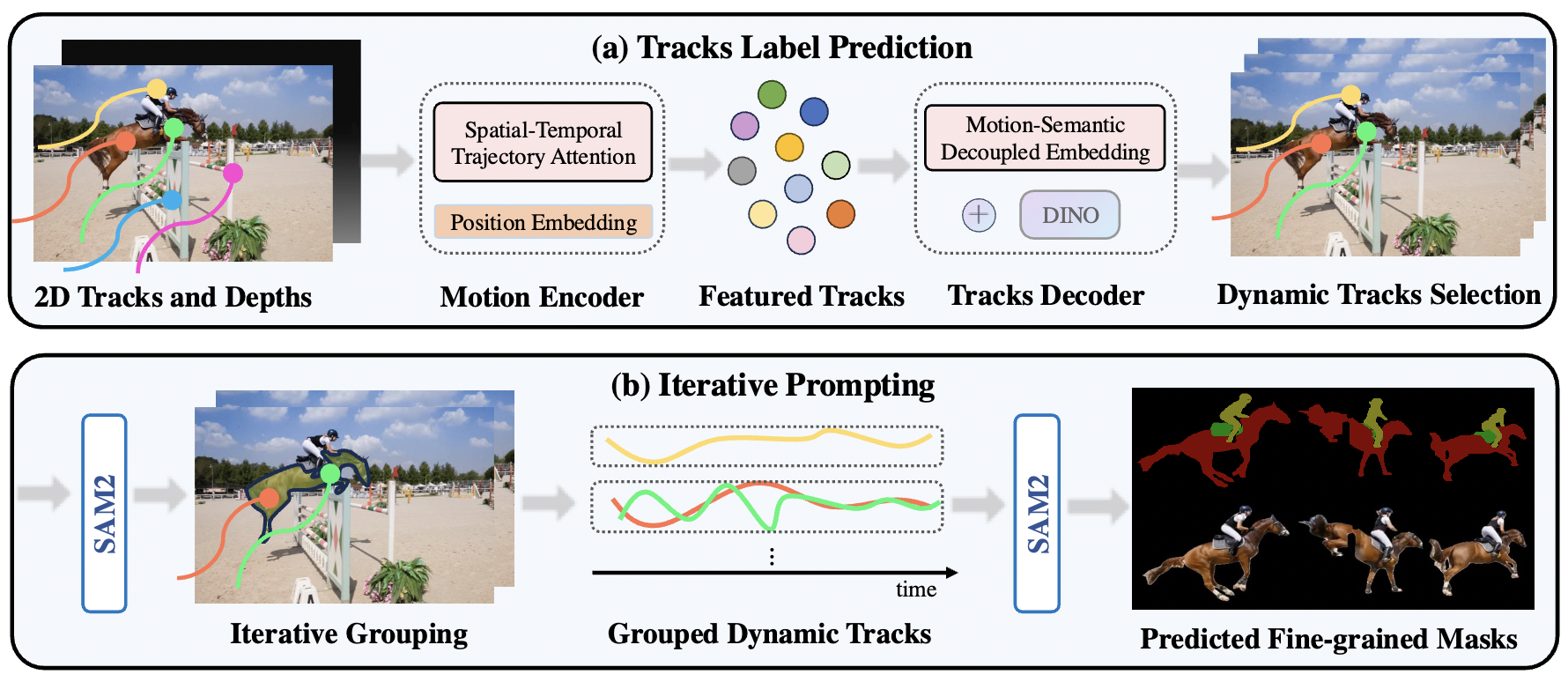
Overview of Our Pipeline. We take 2D tracks and depth maps generated by off-the-shelf models as input, which are then processed by a motion encoder to capture motion patterns, producing featured tracks. Next, we use tracks decoder that integrates DINO feature to decode the featured tracks by decoupling motion and semantic information and ultimately obtain the dynamic trajectories(a). Finally, using SAM2, we group dynamic tracks belonging to the same object and generate fine-grained moving object masks(b).