



https://stable-diffusion-art.com/how-stable-diffusion-work/
Stable Diffusion is a latent diffusion model that generates AI images from text. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space.
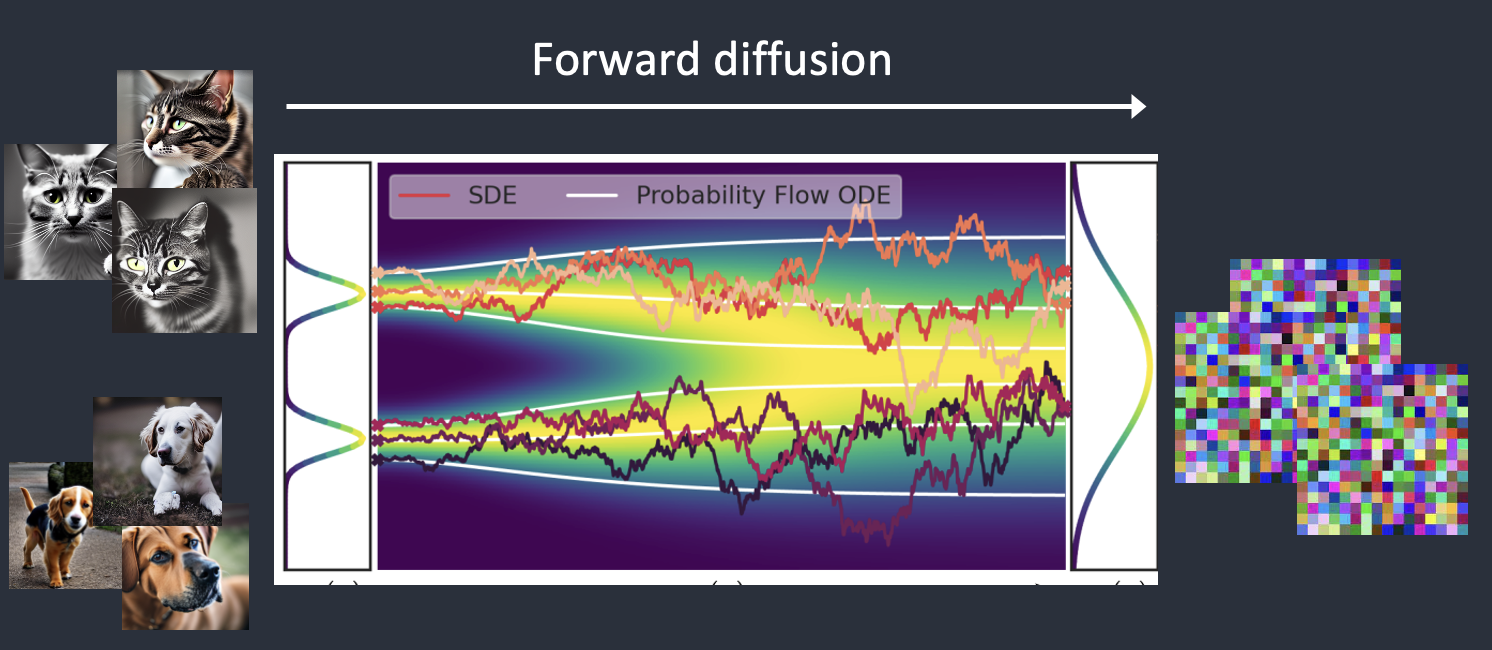
Stable Diffusion belongs to a class of deep learning models called diffusion models. They are generative models, meaning they are designed to generate new data similar to what they have seen in training. In the case of Stable Diffusion, the data are images.
Why is it called the diffusion model? Because its math looks very much like diffusion in physics. Let’s go through the idea.
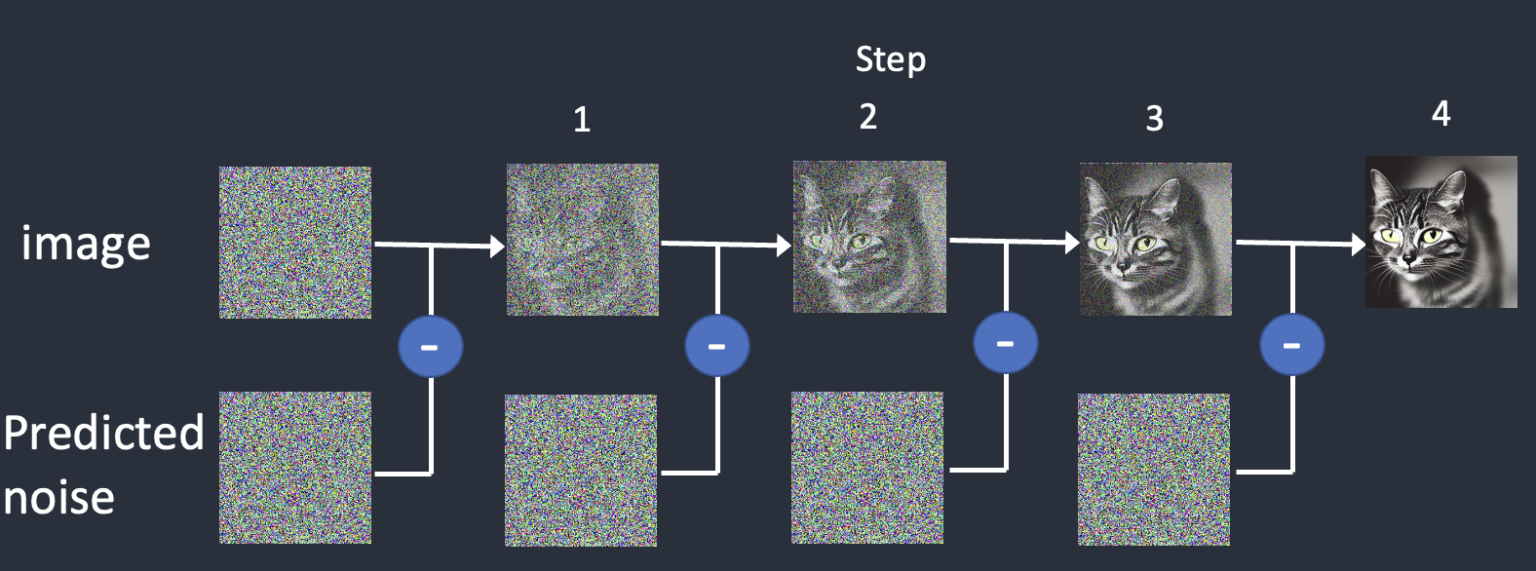
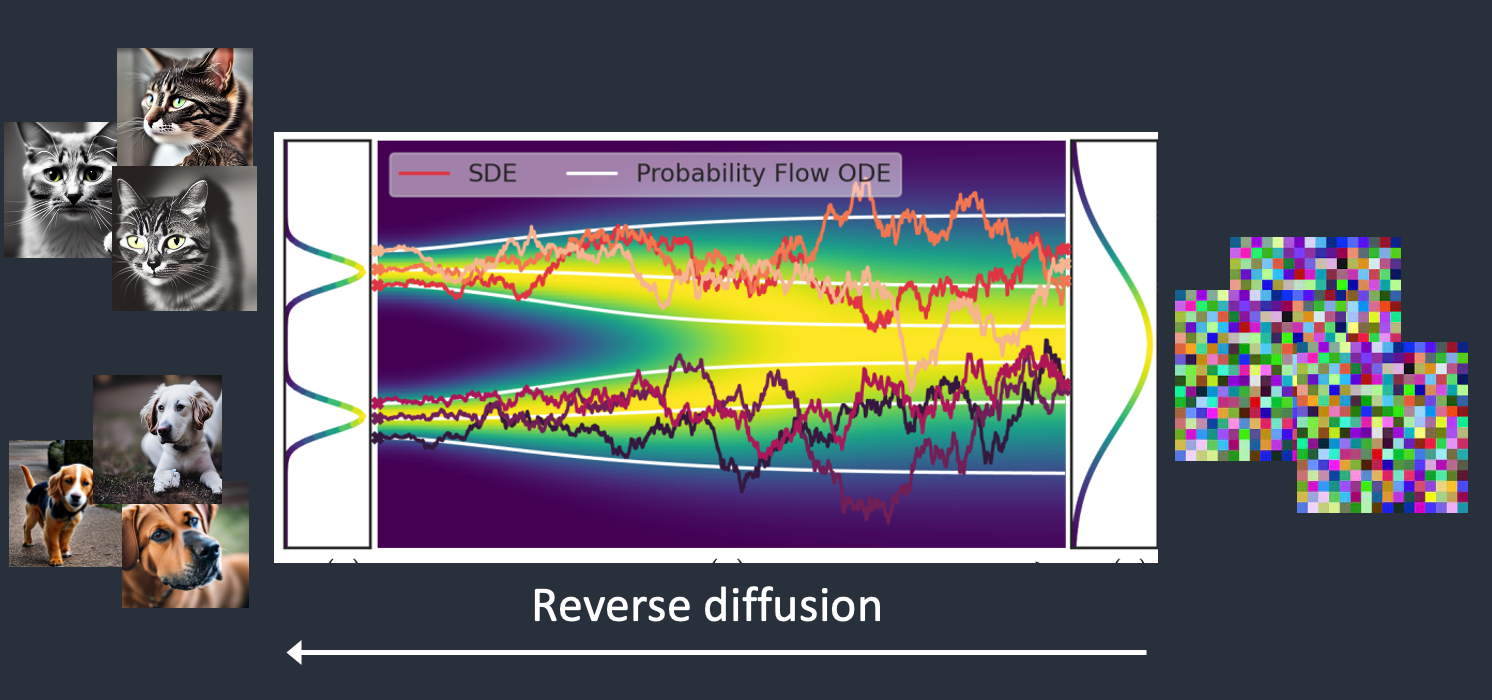
To reverse the diffusion, we need to know how much noise is added to an image. The answer is teaching a neural network model to predict the noise added. It is called the noise predictor in Stable Diffusion. It is a U-Net model.
After training, we have a noise predictor capable of estimating the noise added to an image.
Diffusion models like Google’s Imagen and Open AI’s DALL-E are in pixel space. They have used some tricks to make the model faster but still not enough.
Stable Diffusion is designed to solve the speed problem. Here’s how.
Stable Diffusion is a latent diffusion model. Instead of operating in the high-dimensional image space, it first compresses the image into the latent space. The latent space is 48 times smaller so it reaps the benefit of crunching a lot fewer numbers.
It is done using a technique called the variational autoencoder. Yes, that’s precisely what the VAE files are, but I will make it crystal clear later.
The Variational Autoencoder (VAE) neural network has two parts: (1) an encoder and (2) a decoder. The encoder compresses an image to a lower dimensional representation in the latent space. The decoder restores the image from the latent space.
You may wonder why the VAE can compress an image into a much smaller latent space without losing information. The reason is, unsurprisingly, natural images are not random. They have high regularity: A face follows a specific spatial relationship between the eyes, nose, cheek, and mouth. A dog has 4 legs and is a particular shape.
In other words, the high dimensionality of images is artifactual. Natural images can be readily compressed into the much smaller latent space without losing any information. This is called the manifold hypothesis in machine learning.
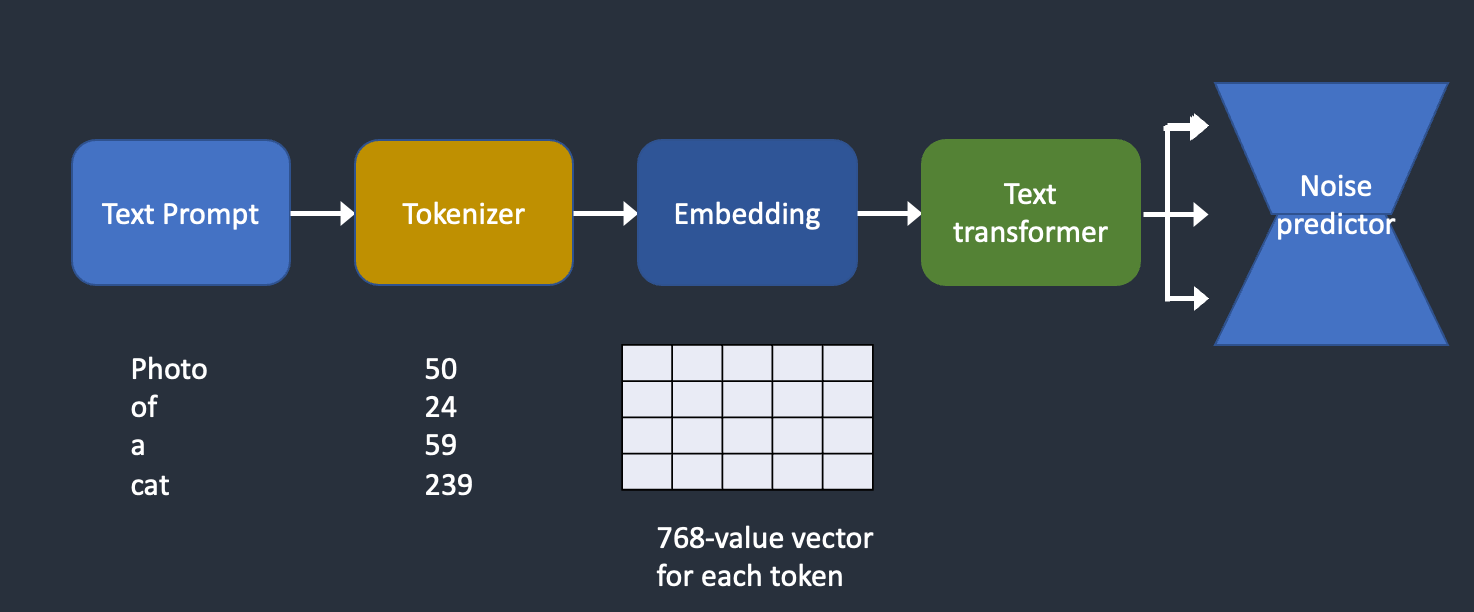
Where does the text prompt enter the picture?
This is where conditioning comes in. The purpose of conditioning is to steer the noise predictor so that the predicted noise will give us what we want after subtracting from the image.
The text prompt is not the only way a Stable Diffusion model can be conditioned. ControlNet conditions the noise predictor with detected outlines, human poses, etc, and achieves excellent controls over image generations.
This write-up won’t be complete without explaining Classifier-Free Guidance (CFG), a value AI artists tinker with every day. To understand what it is, we will need to first touch on its predecessor, classifier guidance…
The classifier guidance scale is a parameter for controlling how closely should the diffusion process follow the label.
Classifier-free guidance, in its authors’ terms, is a way to achieve “classifier guidance without a classifier”. They put the classifier part as conditioning of the noise predictor U-Net, achieving the so-called “classifier-free” (i.e., without a separate image classifier) guidance in image generation.
The SDXL model is the official upgrade to the v1 and v2 models. The model is released as open-source software. The total number of parameters of the SDXL model is 6.6 billion, compared with 0.98 billion for the v1.5 model.
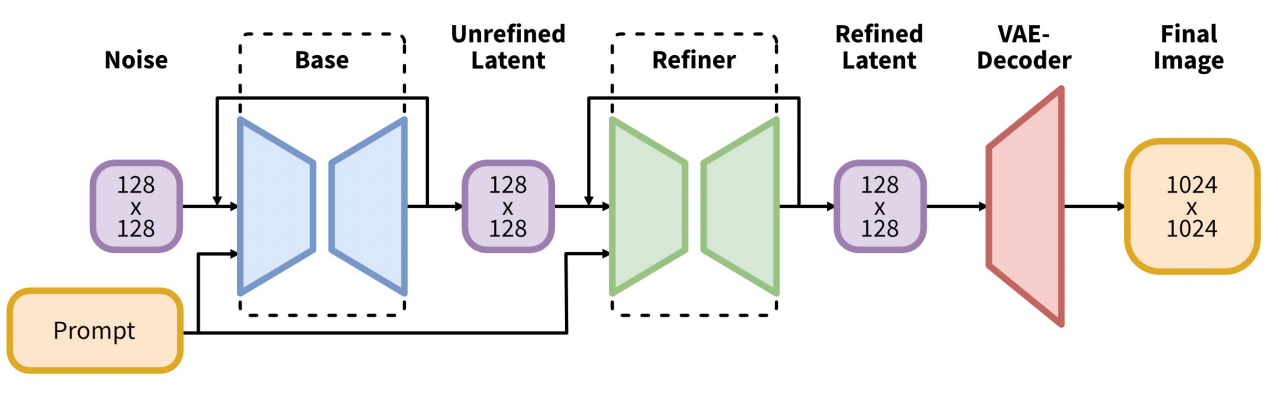
The SDXL model is, in practice, two models. You run the base model, followed by the refiner model. The base model sets the global composition. The refiner model adds finer details.
More about Generative AI here